| { |
| "paragraphs": [ |
| { |
| "title": "", |
| "text": "%md\n\n# Introduction\n\nThis tutorial is for how to use Spark Interpreter in Zeppelin.\n\n1. Specify `SPARK_HOME` in interpreter setting. If you don\u0027t specify `SPARK_HOME`, Zeppelin will use the embedded spark which can only run in local mode. And some advanced features may not work in this embedded spark.\n2. Specify `spark.master` for spark execution mode.\n * `local[*]` - Driver and Executor would both run in the same host of zeppelin server. It is only for testing and POC, not for production. \n * `yarn-client` - Driver would run on the same host of zeppelin server which means it would increase memory pressure on the machine of zeppelin server.\n * `yarn-cluster` - Driver would run in a remote node of yarn cluster, it is supported only after 0.8.0. And yarn-cluster is preferred over yarn-client as it mitigate the memory pressure of zeppelin server.\n * `standalone` - Just specify master to be the spark master address. e.g. spark://HOST:PORT\n * `mesos` - There\u0027s no sufficient test on these mode in Zeppelin. So you may hit weird issues when using these modes.\n3. Create different spark interpreter for different spark version. If you want to use different spark version in the same Zeppelin instance, you can create different spark interpreter for each spark version. And for each interpreter, you need to specify its `SPARK_HOME` properly which point to the correct spark distribution. e.g. You can use the default spark interpreter named `spark` for spark 2.4 and create another spark interpreter named `spark3` for spark 3.0\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-05-04 13:44:39.482", |
| "config": { |
| "tableHide": false, |
| "editorSetting": { |
| "language": "markdown", |
| "editOnDblClick": true, |
| "completionKey": "TAB", |
| "completionSupport": false |
| }, |
| "colWidth": 12.0, |
| "editorMode": "ace/mode/markdown", |
| "fontSize": 9.0, |
| "editorHide": true, |
| "results": {}, |
| "enabled": true |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "results": { |
| "code": "SUCCESS", |
| "msg": [ |
| { |
| "type": "HTML", |
| "data": "\u003cdiv class\u003d\"markdown-body\"\u003e\n\u003ch1\u003eIntroduction\u003c/h1\u003e\n\u003cp\u003eThis tutorial is for how to use Spark Interpreter in Zeppelin.\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003eSpecify \u003ccode\u003eSPARK_HOME\u003c/code\u003e in interpreter setting. If you don\u0026rsquo;t specify \u003ccode\u003eSPARK_HOME\u003c/code\u003e, Zeppelin will use the embedded spark which can only run in local mode. And some advanced features may not work in this embedded spark.\u003c/li\u003e\n\u003cli\u003eSpecify \u003ccode\u003emaster\u003c/code\u003e for spark execution mode.\n\u003cul\u003e\n\u003cli\u003e\u003ccode\u003elocal[*]\u003c/code\u003e - Driver and Executor would both run in the same host of zeppelin server. It is only for testing and POC, not for production.\u003c/li\u003e\n\u003cli\u003e\u003ccode\u003eyarn-client\u003c/code\u003e - Driver would run on the same host of zeppelin server which means it would increase memory pressure on the machine of zeppelin server.\u003c/li\u003e\n\u003cli\u003e\u003ccode\u003eyarn-cluster\u003c/code\u003e - Driver would run in a remote node of yarn cluster, it is supported only after 0.8.0. And yarn-cluster is preferred over yarn-client as it mitigate the memory pressure of zeppelin server.\u003c/li\u003e\n\u003cli\u003e\u003ccode\u003estandalone\u003c/code\u003e - Just specify master to be the spark master address. e.g. \u003ca href\u003d\"spark://HOST:PORT\"\u003espark://HOST:PORT\u003c/a\u003e\u003c/li\u003e\n\u003cli\u003e\u003ccode\u003emesos\u003c/code\u003e - There\u0026rsquo;s no sufficient test on these mode in Zeppelin. So you may hit weird issues when using these modes.\u003c/li\u003e\n\u003c/ul\u003e\n\u003c/li\u003e\n\u003cli\u003eCreate different spark interpreter for different spark version. If you want to use different spark version in the same Zeppelin instance, you can create different spark interpreter for each spark version. And for each interpreter, you need to specify its \u003ccode\u003eSPARK_HOME\u003c/code\u003e properly which point to the correct spark distribution. e.g. You can use the default spark interpreter named \u003ccode\u003espark\u003c/code\u003e for spark 2.4 and create another spark interpreter named \u003ccode\u003espark3\u003c/code\u003e for spark 3.0\u003c/li\u003e\n\u003c/ol\u003e\n\n\u003c/div\u003e" |
| } |
| ] |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762311_275695566", |
| "id": "20180530-211919_1936070943", |
| "dateCreated": "2020-04-30 10:46:02.311", |
| "dateStarted": "2020-05-04 13:44:39.482", |
| "dateFinished": "2020-05-04 13:44:39.508", |
| "status": "FINISHED" |
| }, |
| { |
| "title": "Use Generic Inline Configuration instead of Interpreter Setting", |
| "text": "%md\n\nCustomize your spark interpreter is indispensable for Zeppelin Notebook. E.g. You want to add third party jars, change the execution mode, change the number of executor or its memory and etc. You can check this link for all the available [spark configuration](http://spark.apache.org/docs/latest/configuration.html)\nAlthough you can customize these in interpreter setting, it is recommended to do via the generic inline configuration. Because interpreter setting is shared globally, it is intend to be managed by admin not by users. Users is recommended to customize spark interpreter via the generic inline configuration `%spark.conf`\n\nThe following is an example of how to customize your spark interpreter. To be noticed, you have to run this paragraph first before launching spark interpreter process. Because these customization won\u0027t take effect after spark interpreter process is launched.", |
| "user": "anonymous", |
| "dateUpdated": "2020-05-04 13:45:44.204", |
| "config": { |
| "tableHide": false, |
| "editorSetting": { |
| "language": "markdown", |
| "editOnDblClick": true, |
| "completionKey": "TAB", |
| "completionSupport": false |
| }, |
| "colWidth": 12.0, |
| "editorMode": "ace/mode/markdown", |
| "fontSize": 9.0, |
| "editorHide": true, |
| "title": true, |
| "results": {}, |
| "enabled": true |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "results": { |
| "code": "SUCCESS", |
| "msg": [ |
| { |
| "type": "HTML", |
| "data": "\u003cdiv class\u003d\"markdown-body\"\u003e\n\u003cp\u003eCustomize your spark interpreter is indispensable for Zeppelin Notebook. E.g. You want to add third party jars, change the execution mode, change the number of executor or its memory and etc. You can check this link for all the available \u003ca href\u003d\"http://spark.apache.org/docs/latest/configuration.html\"\u003espark configuration\u003c/a\u003e\u003cbr /\u003e\nAlthough you can customize these in interpreter setting, it is recommended to do via the generic inline configuration. Because interpreter setting is shared globally, it is intend to be managed by admin not by users. Users is recommended to customize spark interpreter via the generic inline configuration \u003ccode\u003e%spark.conf\u003c/code\u003e\u003c/p\u003e\n\u003cp\u003eThe following is an example of how to customize your spark interpreter. To be noticed, you have to run this paragraph first before launching spark interpreter process. Because these customization won\u0026rsquo;t take effect after spark interpreter process is launched.\u003c/p\u003e\n\n\u003c/div\u003e" |
| } |
| ] |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762316_737450410", |
| "id": "20180531-100923_1307061430", |
| "dateCreated": "2020-04-30 10:46:02.316", |
| "dateStarted": "2020-05-04 13:45:44.204", |
| "dateFinished": "2020-05-04 13:45:44.221", |
| "status": "FINISHED" |
| }, |
| { |
| "title": "Generic Inline Configuration", |
| "text": "%spark.conf\n\nSPARK_HOME \u003cPATH_TO_SPARK_HOME\u003e\n\n# set driver memory to 8g\nspark.driver.memory 8g\n\n# set executor number to be 6\nspark.executor.instances 6\n\n# set executor memory 4g\nspark.executor.memory 4g\n\n# Any other spark properties can be set here. Here\u0027s avaliable spark configruation you can set. (http://spark.apache.org/docs/latest/configuration.html)\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-04-30 10:56:30.840", |
| "config": { |
| "editorSetting": { |
| "language": "text", |
| "editOnDblClick": false, |
| "completionKey": "TAB", |
| "completionSupport": true |
| }, |
| "colWidth": 12.0, |
| "editorMode": "ace/mode/text", |
| "fontSize": 9.0, |
| "results": {}, |
| "enabled": true, |
| "title": true |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762316_1311021507", |
| "id": "20180531-101615_648039641", |
| "dateCreated": "2020-04-30 10:46:02.316", |
| "status": "READY" |
| }, |
| { |
| "title": "Use Third Party Library", |
| "text": "%md\n\nThere\u0027re 2 ways to add third party libraries.\n\n* `Generic Inline Configuration` It is the recommended way to add third party jars/packages. Use `spark.jars` for adding local jar file and `spark.jars.packages` for adding packages\n* `Interpreter Setting` You can also config `spark.jars` and `spark.jars.packages` in interpreter setting, but since adding third party libraries is usually application specific. It is recommended to use `Generic Inline Configuration` so that user can see clearly what dependencies this note needs and also easy to rerun this note in another enviroment. Otherwise you need create many interpreters for each note with different dependencies.\n\nThe following is an example that we want to use package `com.databricks:spark-avro_2.11:4.0.0` for reading avro data.\n1. First we specify it in `%spark.conf`\n2. Then we can use it in the next paragraph\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-04-30 10:59:35.270", |
| "config": { |
| "tableHide": false, |
| "editorSetting": { |
| "language": "markdown", |
| "editOnDblClick": true, |
| "completionKey": "TAB", |
| "completionSupport": false |
| }, |
| "colWidth": 12.0, |
| "editorMode": "ace/mode/markdown", |
| "fontSize": 9.0, |
| "editorHide": true, |
| "title": true, |
| "results": {}, |
| "enabled": true |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "results": { |
| "code": "SUCCESS", |
| "msg": [ |
| { |
| "type": "HTML", |
| "data": "\u003cdiv class\u003d\"markdown-body\"\u003e\n\u003cp\u003eThere\u0026rsquo;re 2 ways to add third party libraries.\u003c/p\u003e\n\u003cul\u003e\n\u003cli\u003e\u003ccode\u003eGeneric Inline Configuration\u003c/code\u003e It is the recommended way to add third party jars/packages. Use \u003ccode\u003espark.jars\u003c/code\u003e for adding local jar file and \u003ccode\u003espark.jars.packages\u003c/code\u003e for adding packages\u003c/li\u003e\n\u003cli\u003e\u003ccode\u003eInterpreter Setting\u003c/code\u003e You can also config \u003ccode\u003espark.jars\u003c/code\u003e and \u003ccode\u003espark.jars.packages\u003c/code\u003e in interpreter setting, but since adding third party libraries is usually application specific. It is recommended to use \u003ccode\u003eGeneric Inline Configuration\u003c/code\u003e so that user can see clearly what dependencies this note needs and also easy to rerun this note in another environment. Otherwise you need create many interpreters for each note with different dependencies.\u003c/li\u003e\n\u003c/ul\u003e\n\u003cp\u003eThe following is an example that we want to use package \u003ccode\u003ecom.databricks:spark-avro_2.11:4.0.0\u003c/code\u003e for reading avro data.\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003eFirst we specify it in \u003ccode\u003e%spark.conf\u003c/code\u003e\u003c/li\u003e\n\u003cli\u003eThen we can use it in the next paragraph\u003c/li\u003e\n\u003c/ol\u003e\n\n\u003c/div\u003e" |
| } |
| ] |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762323_1299339607", |
| "id": "20180530-212309_72587811", |
| "dateCreated": "2020-04-30 10:46:02.323", |
| "dateStarted": "2020-04-30 10:59:35.271", |
| "dateFinished": "2020-04-30 10:59:35.282", |
| "status": "FINISHED" |
| }, |
| { |
| "title": "", |
| "text": "%spark.conf\n\n# Must set SPARK_HOME for this example, because it won\u0027t work for Zeppelin\u0027s embedded spark mode. The embedded spark mode doesn\u0027t \n# use spark-submit to launch spark interpreter, so spark.jars and spark.jars.packages won\u0027t take affect. \nSPARK_HOME \u003cPATH_TO_SPARK_HOME\u003e\n\n# set execution mode\nmaster yarn-client\n\n# spark.jars can be used for adding any local jar files into spark interpreter\n# spark.jars \u003cpath_to_local_jar\u003e\n\n# spark.jars.packages can be used for adding packages into spark interpreter\n# The following is to add avro into your spark interpreter\nspark.jars.packages com.databricks:spark-avro_2.11:4.0.0\n\n\n\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-04-30 11:01:36.681", |
| "config": { |
| "editorSetting": { |
| "language": "text", |
| "editOnDblClick": false, |
| "completionKey": "TAB", |
| "completionSupport": true |
| }, |
| "colWidth": 6.0, |
| "editorMode": "ace/mode/text", |
| "fontSize": 9.0, |
| "results": {}, |
| "enabled": true, |
| "editorHide": false |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "results": { |
| "code": "SUCCESS", |
| "msg": [] |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762323_630094194", |
| "id": "20180530-222209_612020876", |
| "dateCreated": "2020-04-30 10:46:02.324", |
| "status": "READY" |
| }, |
| { |
| "title": "", |
| "text": "%spark\n\nimport com.databricks.spark.avro._\n\nval df \u003d spark.read.format(\"com.databricks.spark.avro\").load(\"users.avro\")\ndf.printSchema\n\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-04-30 10:46:02.324", |
| "config": { |
| "editorSetting": { |
| "language": "scala", |
| "editOnDblClick": false, |
| "completionKey": "TAB", |
| "completionSupport": true |
| }, |
| "colWidth": 6.0, |
| "editorMode": "ace/mode/scala", |
| "fontSize": 9.0, |
| "results": {}, |
| "enabled": true |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "results": { |
| "code": "SUCCESS", |
| "msg": [ |
| { |
| "type": "TEXT", |
| "data": "import com.databricks.spark.avro._\ndf: org.apache.spark.sql.DataFrame \u003d [name: string, favorite_color: string ... 1 more field]\n+------+--------------+----------------+\n| name|favorite_color|favorite_numbers|\n+------+--------------+----------------+\n|Alyssa| null| [3, 9, 15, 20]|\n| Ben| red| []|\n+------+--------------+----------------+\n\n" |
| } |
| ] |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762324_60233930", |
| "id": "20180530-222838_1995256600", |
| "dateCreated": "2020-04-30 10:46:02.324", |
| "status": "READY" |
| }, |
| { |
| "title": "Enable Hive", |
| "text": "%md\n\nIf you want to work with hive tables, you need to enable hive via the following 2 steps:\n\n1. Set `zeppelin.spark.useHiveContext` to `true`\n2. Put `hive-site.xml` under `SPARK_CONF_DIR` (By default it is the conf folder of `SPARK_HOME`). \n\n**To be noticed**, You can only enable hive when specifying `SPARK_HOME` explicitly. It doens\u0027t work with zeppelin\u0027s embedded spark.\n\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-04-30 10:46:02.324", |
| "config": { |
| "editorSetting": { |
| "language": "scala", |
| "editOnDblClick": false, |
| "completionKey": "TAB", |
| "completionSupport": true |
| }, |
| "colWidth": 12.0, |
| "editorMode": "ace/mode/scala", |
| "fontSize": 9.0, |
| "editorHide": true, |
| "title": true, |
| "results": {}, |
| "enabled": true |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "results": { |
| "code": "SUCCESS", |
| "msg": [ |
| { |
| "type": "HTML", |
| "data": "\u003cdiv class\u003d\"markdown-body\"\u003e\n\u003cp\u003eIf you want to work with hive tables, you need to enable hive via the following 2 steps:\u003c/p\u003e\n\u003col\u003e\n \u003cli\u003eSet \u003ccode\u003ezeppelin.spark.useHiveContext\u003c/code\u003e to \u003ccode\u003etrue\u003c/code\u003e\u003c/li\u003e\n \u003cli\u003ePut \u003ccode\u003ehive-site.xml\u003c/code\u003e under \u003ccode\u003eSPARK_CONF_DIR\u003c/code\u003e (By default it is the conf folder of \u003ccode\u003eSPARK_HOME\u003c/code\u003e).\u003c/li\u003e\n\u003c/ol\u003e\n\u003cp\u003e\u003cstrong\u003eTo be noticed\u003c/strong\u003e, You can only enable hive when specifying \u003ccode\u003eSPARK_HOME\u003c/code\u003e explicitly. It doens\u0026rsquo;t work with zeppelin\u0026rsquo;s embedded spark.\u003c/p\u003e\n\u003c/div\u003e" |
| } |
| ] |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762324_975709991", |
| "id": "20180601-095002_1719356880", |
| "dateCreated": "2020-04-30 10:46:02.324", |
| "status": "READY" |
| }, |
| { |
| "title": "Code Completion in Scala", |
| "text": "%md\n\nSpark interpreter provide code completion feature. As long as you type `tab`, code completion will start to work and provide you with a list of candidates. Here\u0027s one screenshot of how it works. \n\n**To be noticed**, code completion only works after spark interpreter is launched. So it will not work when you type code in the first paragraph as the spark interpreter is not launched yet. For me, usually I will run one simple code such as `sc.version` to launch spark interpreter, then type my code to leverage the code completion of spark interpreter.\n\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-04-30 11:03:03.127", |
| "config": { |
| "tableHide": false, |
| "editorSetting": { |
| "language": "markdown", |
| "editOnDblClick": true, |
| "completionKey": "TAB", |
| "completionSupport": false |
| }, |
| "colWidth": 12.0, |
| "editorMode": "ace/mode/markdown", |
| "fontSize": 9.0, |
| "editorHide": true, |
| "title": true, |
| "results": {}, |
| "enabled": true |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "results": { |
| "code": "SUCCESS", |
| "msg": [ |
| { |
| "type": "HTML", |
| "data": "\u003cdiv class\u003d\"markdown-body\"\u003e\n\u003cp\u003eSpark interpreter provide code completion feature. As long as you type \u003ccode\u003etab\u003c/code\u003e, code completion will start to work and provide you with a list of candidates. Here\u0026rsquo;s one screenshot of how it works.\u003c/p\u003e\n\u003cp\u003e\u003cstrong\u003eTo be noticed\u003c/strong\u003e, code completion only works after spark interpreter is launched. So it will not work when you type code in the first paragraph as the spark interpreter is not launched yet. For me, usually I will run one simple code such as \u003ccode\u003esc.version\u003c/code\u003e to launch spark interpreter, then type my code to leverage the code completion of spark interpreter.\u003c/p\u003e\n\u003cp\u003e\u003cimg src\u003d\"https://user-images.githubusercontent.com/164491/40758276-1ab2783e-64bf-11e8-9c1e-d132455234b3.gif\" alt\u003d\"code_completion\" /\u003e\u003c/p\u003e\n\n\u003c/div\u003e" |
| } |
| ] |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762324_1893956125", |
| "id": "20180531-095404_2000387113", |
| "dateCreated": "2020-04-30 10:46:02.324", |
| "dateStarted": "2020-04-30 11:03:03.136", |
| "dateFinished": "2020-04-30 11:03:03.147", |
| "status": "FINISHED" |
| }, |
| { |
| "title": "PySpark", |
| "text": "%md\n\nFor using PySpark, you need to do some other pyspark configuration besides the above spark configuration we mentioned before. The most important property you need to set is python path for both driver and executor. If you hit the following error, it means your python on driver is mismatched with that of executor. In this case you need to check the 2 properties: `PYSPARK_PYTHON` and `PYSPARK_DRIVER_PYTHON`. (You can use `spark.pyspark.python` and `spark.pyspark.driver.python` instead if you are using spark after 2.1.0)\n\n```\nPy4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.\n: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 7, localhost, executor 1): org.apache.spark.api.python.PythonException: Traceback (most recent call last):\n File \"/Users/jzhang/Java/lib/spark-2.3.0-bin-hadoop2.7/python/pyspark/worker.py\", line 175, in main\n (\"%d.%d\" % sys.version_info[:2], version))\nException: Python in worker has different version 2.7 than that in driver 3.6, PySpark cannot run with different minor versions.Please check environment variables PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON are correctly set.\n```\n\nAlso it is better to specify them in the `generic inline configuration` like the following paragraph.\n\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-04-30 11:04:18.086", |
| "config": { |
| "tableHide": false, |
| "editorSetting": { |
| "language": "markdown", |
| "editOnDblClick": true, |
| "completionKey": "TAB", |
| "completionSupport": false |
| }, |
| "colWidth": 12.0, |
| "editorMode": "ace/mode/markdown", |
| "fontSize": 9.0, |
| "editorHide": true, |
| "title": true, |
| "results": {}, |
| "enabled": true |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "results": { |
| "code": "SUCCESS", |
| "msg": [ |
| { |
| "type": "HTML", |
| "data": "\u003cdiv class\u003d\"markdown-body\"\u003e\n\u003cp\u003eFor using PySpark, you need to do some other pyspark configuration besides the above spark configuration we mentioned before. The most important property you need to set is python path for both driver and executor. If you hit the following error, it means your python on driver is mismatched with that of executor. In this case you need to check the 2 properties: \u003ccode\u003ePYSPARK_PYTHON\u003c/code\u003e and \u003ccode\u003ePYSPARK_DRIVER_PYTHON\u003c/code\u003e. (You can use \u003ccode\u003espark.pyspark.python\u003c/code\u003e and \u003ccode\u003espark.pyspark.driver.python\u003c/code\u003e instead if you are using spark after 2.1.0)\u003c/p\u003e\n\u003cpre\u003e\u003ccode\u003ePy4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.\n: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 7, localhost, executor 1): org.apache.spark.api.python.PythonException: Traceback (most recent call last):\n File \u0026quot;/Users/jzhang/Java/lib/spark-2.3.0-bin-hadoop2.7/python/pyspark/worker.py\u0026quot;, line 175, in main\n (\u0026quot;%d.%d\u0026quot; % sys.version_info[:2], version))\nException: Python in worker has different version 2.7 than that in driver 3.6, PySpark cannot run with different minor versions.Please check environment variables PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON are correctly set.\n\u003c/code\u003e\u003c/pre\u003e\n\u003cp\u003eAlso it is better to specify them in the \u003ccode\u003egeneric inline configuration\u003c/code\u003e like the following paragraph.\u003c/p\u003e\n\n\u003c/div\u003e" |
| } |
| ] |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762324_1658396672", |
| "id": "20180531-104119_406393728", |
| "dateCreated": "2020-04-30 10:46:02.324", |
| "dateStarted": "2020-04-30 11:04:18.087", |
| "dateFinished": "2020-04-30 11:04:18.098", |
| "status": "FINISHED" |
| }, |
| { |
| "title": "", |
| "text": "%spark.conf\n\n# If you python path on driver and executor is the same, then you only need to set PYSPARK_PYTHON\nPYSPARK_PYTHON \u003cpython_path\u003e\nspark.pyspark.python \u003cpython_path\u003e\n\n# You need to set PYSPARK_DRIVER_PYTHON as well if your python path on driver is different from executors.\nPYSPARK_DRIVER_PYTHON \u003cpython_path\u003e\nspark.pyspark.driver.python \u003cpython_path\u003e\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-04-30 11:04:52.984", |
| "config": { |
| "editorSetting": { |
| "language": "text", |
| "editOnDblClick": false, |
| "completionKey": "TAB", |
| "completionSupport": true |
| }, |
| "colWidth": 12.0, |
| "editorMode": "ace/mode/text", |
| "fontSize": 9.0, |
| "editorHide": false, |
| "results": {}, |
| "enabled": true |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "results": { |
| "code": "SUCCESS", |
| "msg": [] |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762324_496073034", |
| "id": "20180531-110822_21877516", |
| "dateCreated": "2020-04-30 10:46:02.324", |
| "status": "READY" |
| }, |
| { |
| "title": "Use IPython", |
| "text": "%md\n\nStarting from Zeppelin 0.8.0, `ipython` is integrated into Zeppelin. And `PySparkInterpreter`(`%spark.pyspark`) would use `ipython` if it is available. It is recommended to use `ipython` interpreter as it provides more powerful feature than the old PythonInterpreter. Spark create a new interpreter called `IPySparkInterpreter` (`%spark.ipyspark`) which use IPython underneath. You can use all the `ipython` features in this IPySparkInterpreter. There\u0027s one ipython tutorial note in Zeppelin which you can refer for more details.\n\n`spark.pyspark` will try to use `ipython` if it is available, it will fall back to the old PySpark implemention if `ipython` is not available. But you can always use `ipython` via `%spark.ipyspark`.\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-04-30 11:10:07.426", |
| "config": { |
| "tableHide": false, |
| "editorSetting": { |
| "language": "markdown", |
| "editOnDblClick": true, |
| "completionKey": "TAB", |
| "completionSupport": false |
| }, |
| "colWidth": 12.0, |
| "editorMode": "ace/mode/markdown", |
| "fontSize": 9.0, |
| "editorHide": true, |
| "title": true, |
| "results": {}, |
| "enabled": true |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "results": { |
| "code": "SUCCESS", |
| "msg": [ |
| { |
| "type": "HTML", |
| "data": "\u003cdiv class\u003d\"markdown-body\"\u003e\n\u003cp\u003eStarting from Zeppelin 0.8.0, \u003ccode\u003eipython\u003c/code\u003e is integrated into Zeppelin. And \u003ccode\u003ePySparkInterpreter\u003c/code\u003e(\u003ccode\u003e%spark.pyspark\u003c/code\u003e) would use \u003ccode\u003eipython\u003c/code\u003e if it is available. It is recommended to use \u003ccode\u003eipython\u003c/code\u003e interpreter as it provides more powerful feature than the old PythonInterpreter. Spark create a new interpreter called \u003ccode\u003eIPySparkInterpreter\u003c/code\u003e (\u003ccode\u003e%spark.ipyspark\u003c/code\u003e) which use IPython underneath. You can use all the \u003ccode\u003eipython\u003c/code\u003e features in this IPySparkInterpreter. There\u0026rsquo;s one ipython tutorial note in Zeppelin which you can refer for more details.\u003c/p\u003e\n\u003cp\u003e\u003ccode\u003espark.pyspark\u003c/code\u003e will try to use \u003ccode\u003eipython\u003c/code\u003e if it is available, it will fall back to the old PySpark implemention if \u003ccode\u003eipython\u003c/code\u003e is not available. But you can always use \u003ccode\u003eipython\u003c/code\u003e via \u003ccode\u003e%spark.ipyspark\u003c/code\u003e.\u003c/p\u003e\n\n\u003c/div\u003e" |
| } |
| ] |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762324_1303560480", |
| "id": "20180531-104646_1689036640", |
| "dateCreated": "2020-04-30 10:46:02.324", |
| "dateStarted": "2020-04-30 11:10:07.428", |
| "dateFinished": "2020-04-30 11:10:07.436", |
| "status": "FINISHED" |
| }, |
| { |
| "title": "Enable Impersonation", |
| "text": "%md\n\nBy default, all the spark interpreter will run as user who launch zeppelin server. This is OK for single user, but expose potential issue for multiple user scenaior. For multiple user scenaior, it is better to enable impersonation for Spark Interpreter in yarn mode.\nThere are 3 steps you need to do to enable impersonation.\n\n1. Enable it in Spark Interpreter Setting. You have to choose Isolated Per User mode, and then click the impersonation option as following screenshot. 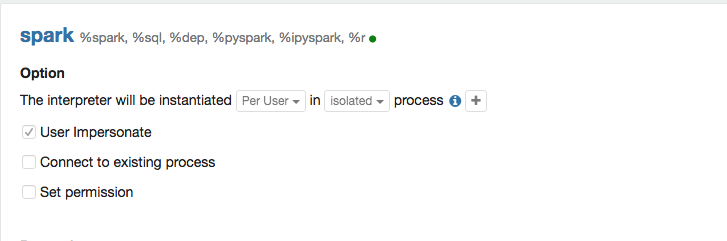\n2. Add the following configure in core-site.xml of your hadoop cluser, and then restart the hadoop cluster (restart hdfs and yarn). \u003cuser_name\u003e is the user who launch zeppelin server. \n\n```xml\n\u003cproperty\u003e\n \u003cname\u003ehadoop.proxyuser.\u003cuser_name\u003e.groups\u003c/name\u003e\n \u003cvalue\u003e*\u003c/value\u003e\n\u003c/property\u003e\n\n\u003cproperty\u003e\n \u003cname\u003ehadoop.proxyuser.\u003cuser_name\u003e.hosts\u003c/name\u003e\n \u003cvalue\u003e*\u003c/value\u003e\n\u003c/property\u003e\n```\n3. Create user home folder on hdfs and also set the right permission on this folder. Because spark will use this home folder as staging directory which is used to upload spark jars and other dependencies that is needed by yarn container. Here\u0027s a sample output of command `hadoop fs -ls /user`\n```\ndrwxr-xr-x - user1 supergroup 0 2018-05-31 13:41 /user/user1\ndrwxr-xr-x - user2 supergroup 0 2017-01-10 12:31 /user/user2\n```\nYou can use the following command to create home folder for `user1` and also set proper permission.\n```\nhadoop fs -mkdir /uesr/user1\nhadoop fs -chown user1 /user/user1\n```\n\nAfter all these steps, you can see impersonation should work in yarn web ui. E.g. In the following screenshot, we can see that the yarn app run as user `user1` instead of the user who run zeppelin server.\n\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-04-30 11:11:51.383", |
| "config": { |
| "tableHide": false, |
| "editorSetting": { |
| "language": "markdown", |
| "editOnDblClick": true, |
| "completionKey": "TAB", |
| "completionSupport": false |
| }, |
| "colWidth": 12.0, |
| "editorMode": "ace/mode/markdown", |
| "fontSize": 9.0, |
| "editorHide": true, |
| "title": true, |
| "results": {}, |
| "enabled": true |
| }, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "results": { |
| "code": "SUCCESS", |
| "msg": [ |
| { |
| "type": "HTML", |
| "data": "\u003cdiv class\u003d\"markdown-body\"\u003e\n\u003cp\u003eBy default, all the spark interpreter will run as user who launch zeppelin server. This is OK for single user, but expose potential issue for multiple user scenaior. For multiple user scenaior, it is better to enable impersonation for Spark Interpreter in yarn mode.\u003cbr /\u003e\nThere are 3 steps you need to do to enable impersonation.\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003eEnable it in Spark Interpreter Setting. You have to choose Isolated Per User mode, and then click the impersonation option as following screenshot. \u003cimg src\u003d\"https://user-images.githubusercontent.com/164491/40763519-b76fa56c-64d7-11e8-9d49-53928a04ba5d.png\" alt\u003d\"screen shot 2018-05-31 at 1 35 34 pm\" /\u003e\u003c/li\u003e\n\u003cli\u003eAdd the following configure in core-site.xml of your hadoop cluser, and then restart the hadoop cluster (restart hdfs and yarn). \u0026lt;user_name\u0026gt; is the user who launch zeppelin server.\u003c/li\u003e\n\u003c/ol\u003e\n\u003cpre\u003e\u003ccode class\u003d\"language-xml\"\u003e\u0026lt;property\u0026gt;\n \u0026lt;name\u0026gt;hadoop.proxyuser.\u0026lt;user_name\u0026gt;.groups\u0026lt;/name\u0026gt;\n \u0026lt;value\u0026gt;*\u0026lt;/value\u0026gt;\n\u0026lt;/property\u0026gt;\n\n\u0026lt;property\u0026gt;\n \u0026lt;name\u0026gt;hadoop.proxyuser.\u0026lt;user_name\u0026gt;.hosts\u0026lt;/name\u0026gt;\n \u0026lt;value\u0026gt;*\u0026lt;/value\u0026gt;\n\u0026lt;/property\u0026gt;\n\u003c/code\u003e\u003c/pre\u003e\n\u003col start\u003d\"3\"\u003e\n\u003cli\u003eCreate user home folder on hdfs and also set the right permission on this folder. Because spark will use this home folder as staging directory which is used to upload spark jars and other dependencies that is needed by yarn container. Here\u0026rsquo;s a sample output of command \u003ccode\u003ehadoop fs -ls /user\u003c/code\u003e\u003c/li\u003e\n\u003c/ol\u003e\n\u003cpre\u003e\u003ccode\u003edrwxr-xr-x - user1 supergroup 0 2018-05-31 13:41 /user/user1\ndrwxr-xr-x - user2 supergroup 0 2017-01-10 12:31 /user/user2\n\u003c/code\u003e\u003c/pre\u003e\n\u003cp\u003eYou can use the following command to create home folder for \u003ccode\u003euser1\u003c/code\u003e and also set proper permission.\u003c/p\u003e\n\u003cpre\u003e\u003ccode\u003ehadoop fs -mkdir /uesr/user1\nhadoop fs -chown user1 /user/user1\n\u003c/code\u003e\u003c/pre\u003e\n\u003cp\u003eAfter all these steps, you can see impersonation should work in yarn web ui. E.g. In the following screenshot, we can see that the yarn app run as user \u003ccode\u003euser1\u003c/code\u003e instead of the user who run zeppelin server.\u003c/p\u003e\n\u003cp\u003e\u003cimg src\u003d\"https://user-images.githubusercontent.com/164491/40763896-330dc8f6-64d9-11e8-9737-92d8371e85ae.png\" alt\u003d\"screen shot 2018-05-31 at 1 47 05 pm\" /\u003e\u003c/p\u003e\n\n\u003c/div\u003e" |
| } |
| ] |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762324_1470430553", |
| "id": "20180531-105943_1008146830", |
| "dateCreated": "2020-04-30 10:46:02.324", |
| "dateStarted": "2020-04-30 11:11:51.385", |
| "dateFinished": "2020-04-30 11:11:51.395", |
| "status": "FINISHED" |
| }, |
| { |
| "title": "", |
| "text": "%spark\n", |
| "user": "anonymous", |
| "dateUpdated": "2020-04-30 10:46:02.325", |
| "config": {}, |
| "settings": { |
| "params": {}, |
| "forms": {} |
| }, |
| "apps": [], |
| "progressUpdateIntervalMs": 500, |
| "jobName": "paragraph_1588214762325_1205048464", |
| "id": "20180531-134529_63265354", |
| "dateCreated": "2020-04-30 10:46:02.325", |
| "status": "READY" |
| } |
| ], |
| "name": "1. Spark Interpreter Introduction", |
| "id": "2F8KN6TKK", |
| "defaultInterpreterGroup": "spark", |
| "version": "0.9.0-SNAPSHOT", |
| "noteParams": {}, |
| "noteForms": {}, |
| "angularObjects": {}, |
| "config": { |
| "isZeppelinNotebookCronEnable": false |
| }, |
| "info": {} |
| } |