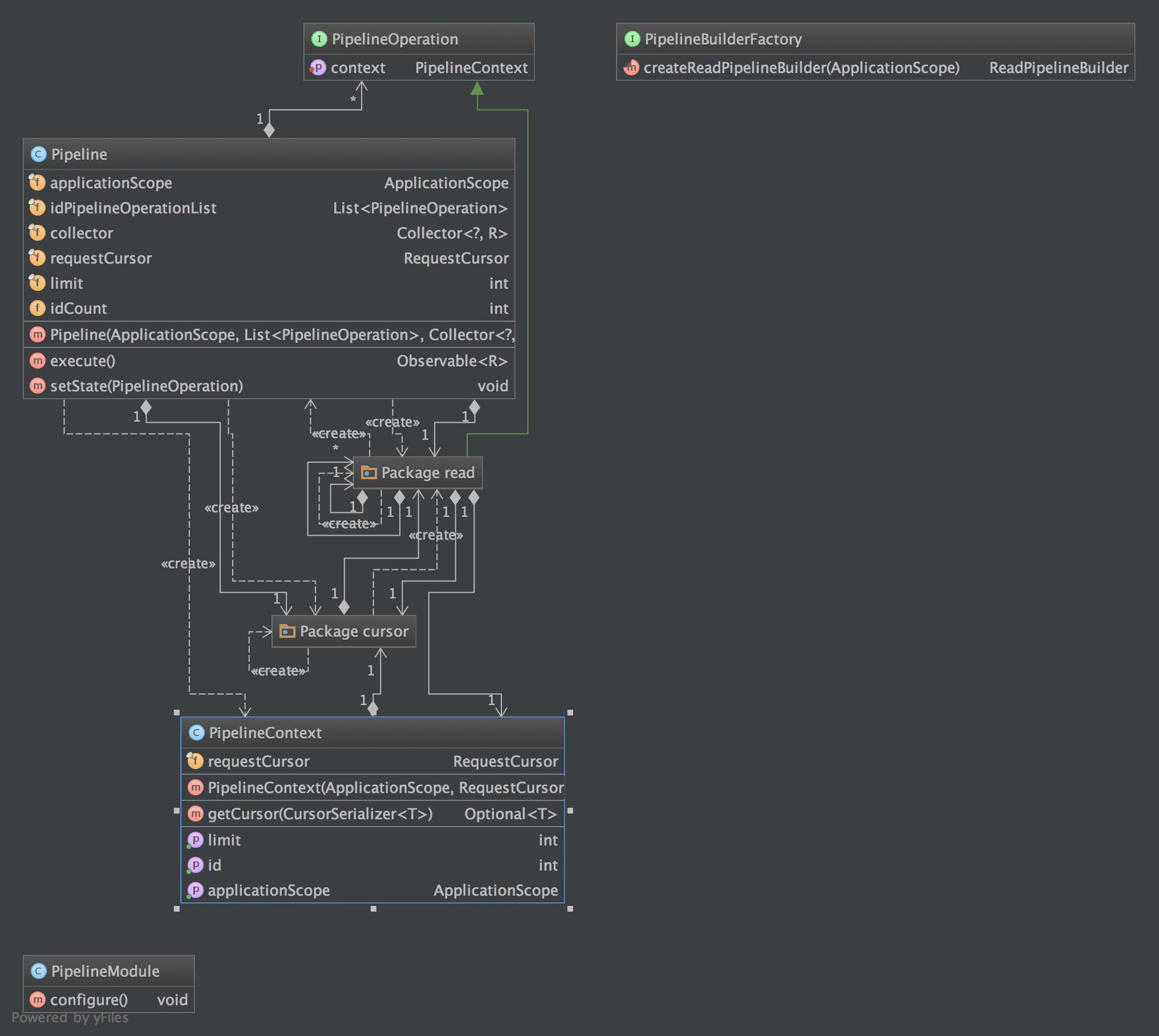
#IO Framework Based on the Pipes and Filters software pattern
##How does this all work? Consider the following example flow:
pipeline = 1. appId -> 2. filter1 -> filter2 -> 3. collector -> 4. Observable

execute method contains the execution of the pipeline. It retrieves the applications and pipes the operations from one to another until we run out of operations. At that point we aggregate the response into a collection and return an observable with the elements.###Indepth Cursor Module Explanation 
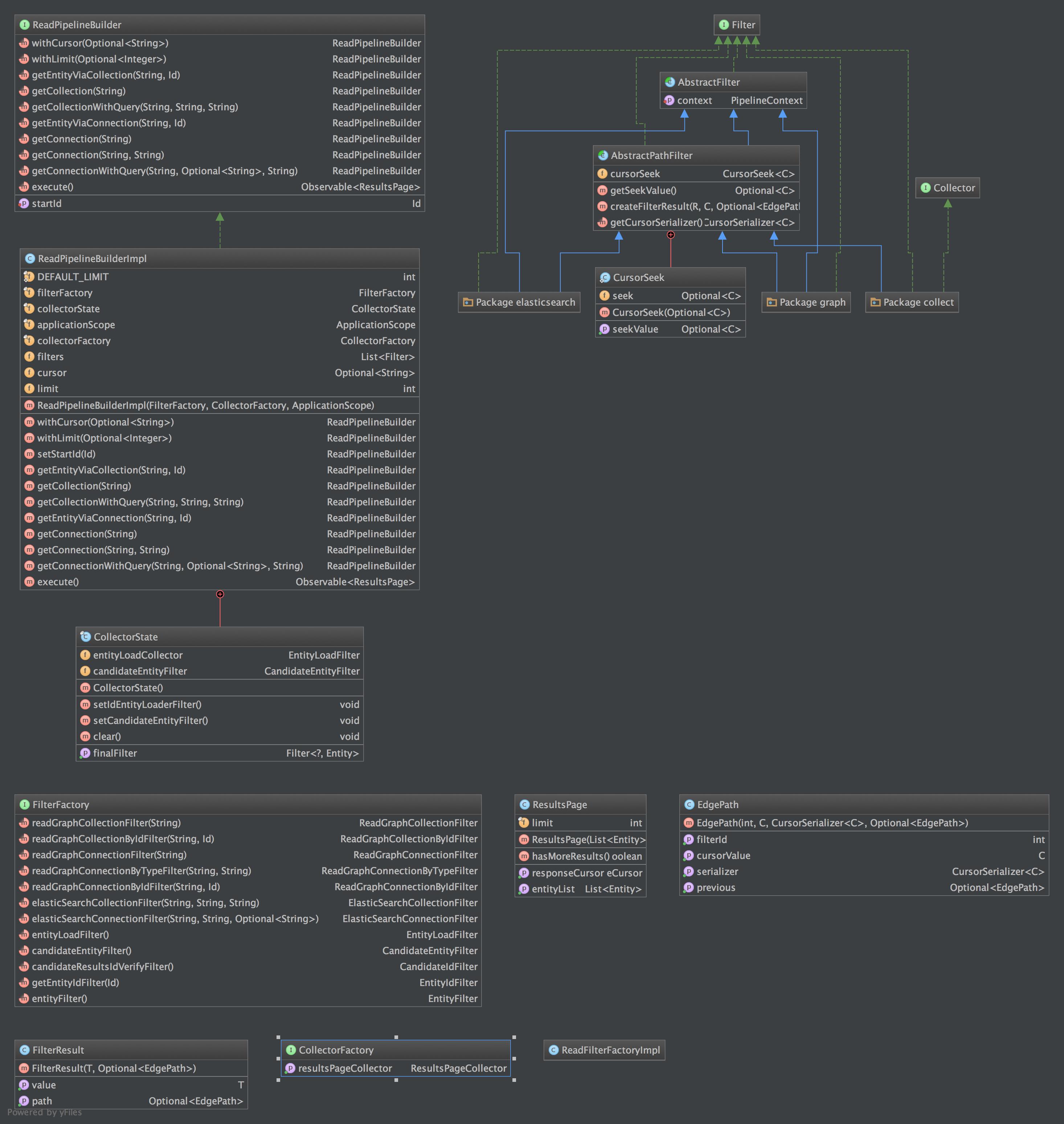
###Indepth Read Module Explanation 
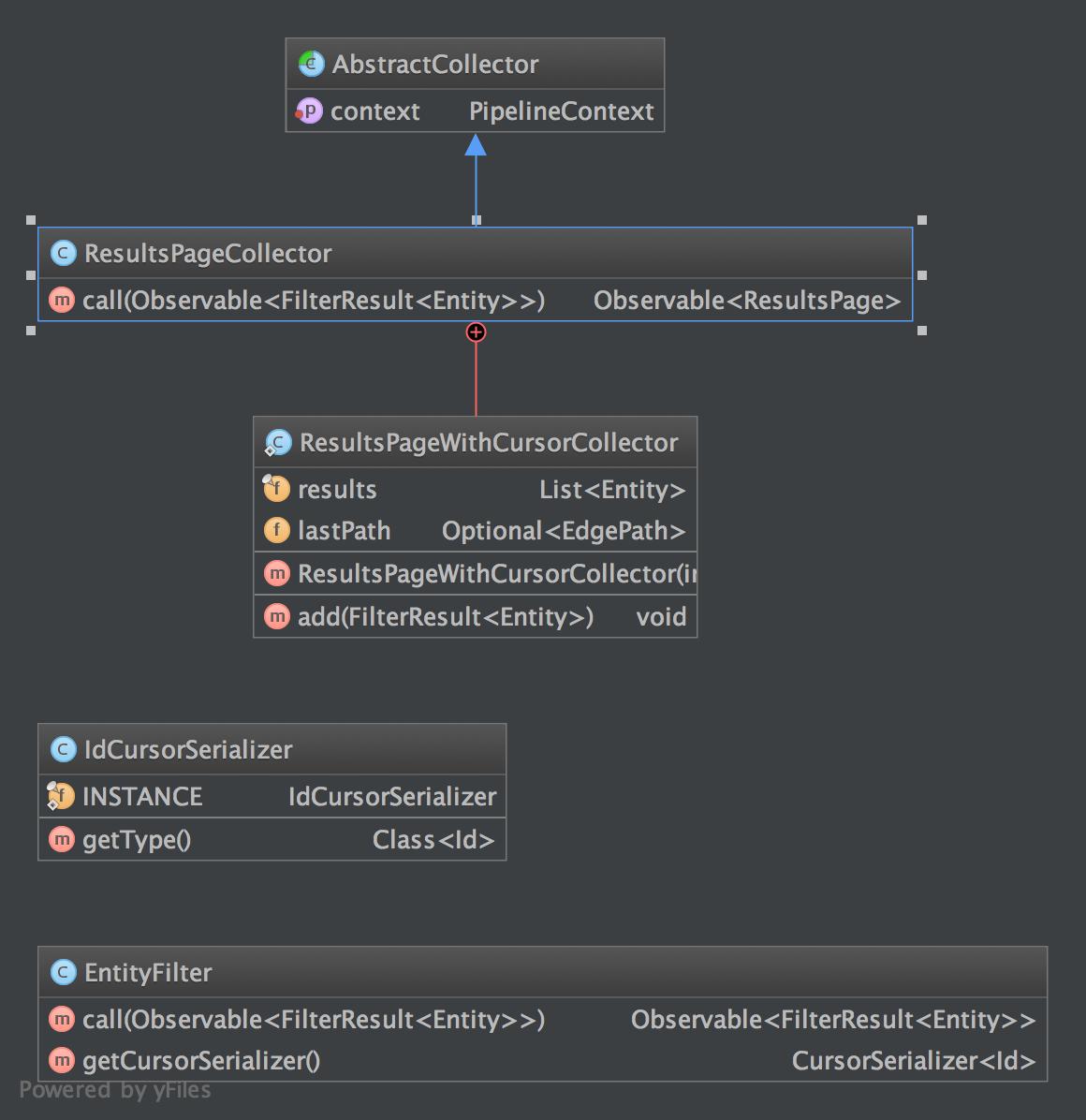
###Indepth Collect Module Explanation

###Indepth Graph Module Explanation 
The Main difference between ReadGraph and ReadGraph by id is that the Id won‘t ever bother itself with cursors because it doesn’t need to worry about cursor generation. Hence the distinction but very similar patterns.
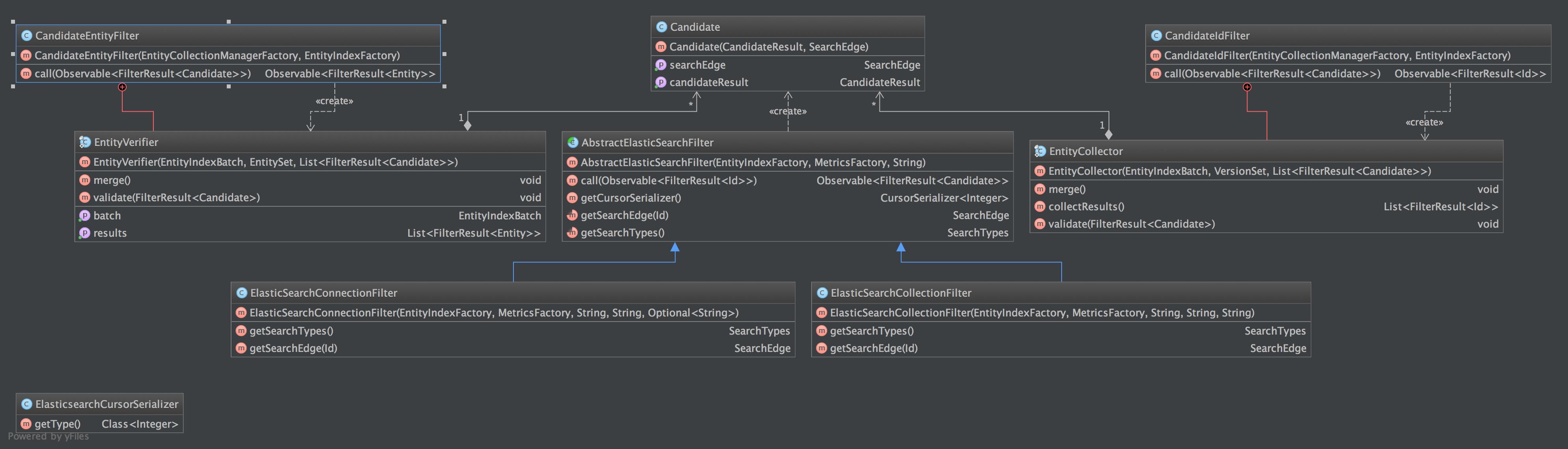
###Indepth Elasticsearch Module Explanation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}