| <!--- Licensed to the Apache Software Foundation (ASF) under one --> |
| <!--- or more contributor license agreements. See the NOTICE file --> |
| <!--- distributed with this work for additional information --> |
| <!--- regarding copyright ownership. The ASF licenses this file --> |
| <!--- to you under the Apache License, Version 2.0 (the --> |
| <!--- "License"); you may not use this file except in compliance --> |
| <!--- with the License. You may obtain a copy of the License at --> |
| |
| <!--- http://www.apache.org/licenses/LICENSE-2.0 --> |
| |
| <!--- Unless required by applicable law or agreed to in writing, --> |
| <!--- software distributed under the License is distributed on an --> |
| <!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY --> |
| <!--- KIND, either express or implied. See the License for the --> |
| <!--- specific language governing permissions and limitations --> |
| <!--- under the License. --> |
| |
| # Image Embedding Learning |
| |
| This example implements embedding learning based on a Margin-based Loss with distance weighted sampling [(Wu et al, 2017)](http://www.philkr.net/papers/2017-10-01-iccv/2017-10-01-iccv.pdf). The model obtains a validation Recall@1 of ~64% on the [Caltech-UCSD Birds-200-2011](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html) dataset. |
| |
| |
| ## Usage |
| Download the data |
| |
| Note: the dataset is from [Caltech-UCSD Birds 200](http://www.vision.caltech.edu/visipedia/CUB-200.html). |
| These datasets are copyright Caltech Computational Vision Group and licensed CC BY 4.0 Attribution. |
| See [original dataset source](http://www.vision.caltech.edu/archive.html) for details |
| ```bash |
| ./get_cub200_data.sh |
| ``` |
| |
| Example runs and the results: |
| ``` |
| python3 train.py --data-path=data/CUB_200_2011 --gpus=0,1 --use-pretrained |
| ``` |
| |
| <br> |
| |
| `python train.py --help` gives the following arguments: |
| ``` |
| optional arguments: |
| -h, --help show this help message and exit |
| --data-path DATA_PATH |
| path of data. |
| --embed-dim EMBED_DIM |
| dimensionality of image embedding. default is 128. |
| --batch-size BATCH_SIZE |
| training batch size per device (CPU/GPU). default is |
| 70. |
| --batch-k BATCH_K number of images per class in a batch. default is 5. |
| --gpus GPUS list of gpus to use, e.g. 0 or 0,2,5. empty means |
| using cpu. |
| --epochs EPOCHS number of training epochs. default is 20. |
| --optimizer OPTIMIZER |
| optimizer. default is adam. |
| --lr LR learning rate. default is 0.0001. |
| --lr-beta LR_BETA learning rate for the beta in margin based loss. |
| default is 0.1. |
| --margin MARGIN margin for the margin based loss. default is 0.2. |
| --beta BETA initial value for beta. default is 1.2. |
| --nu NU regularization parameter for beta. default is 0.0. |
| --factor FACTOR learning rate schedule factor. default is 0.5. |
| --steps STEPS epochs to update learning rate. default is |
| 12,14,16,18. |
| --wd WD weight decay rate. default is 0.0001. |
| --seed SEED random seed to use. default=123. |
| --model MODEL type of model to use. see vision_model for options. |
| --save-model-prefix SAVE_MODEL_PREFIX |
| prefix of models to be saved. |
| --use-pretrained enable using pretrained model from gluon. |
| --kvstore KVSTORE kvstore to use for trainer. |
| --log-interval LOG_INTERVAL |
| number of batches to wait before logging. |
| ``` |
| |
| ## Learned embeddings |
| The following visualizes the learned embeddings with t-SNE. |
| |
| 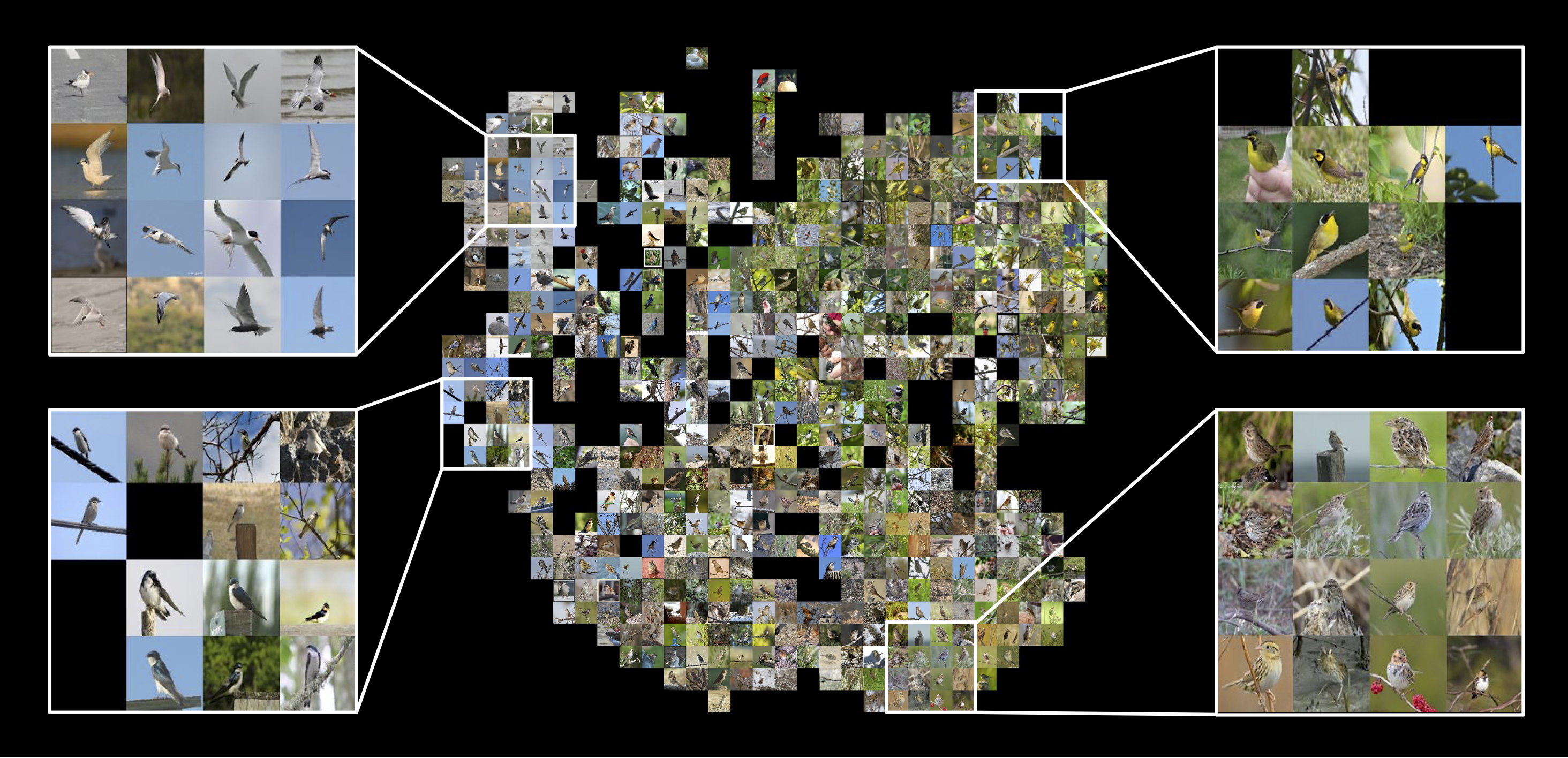 |
| |
| |
| ## Citation |
| <b>Sampling Matters in Deep Embedding Learning</b> [<a href="https://arxiv.org/abs/1706.07567">paper</a>] [<a href="https://www.cs.utexas.edu/~cywu/projects/sampling_matters/">project</a>] <br> |
| Chao-Yuan Wu, R. Manmatha, Alexander J. Smola and Philipp Krähenbühl |
| <pre> |
| @inproceedings{wu2017sampling, |
| title={Sampling Matters in Deep Embedding Learning}, |
| author={Wu, Chao-Yuan and Manmatha, R and Smola, Alexander J and Kr{\"a}henb{\"u}hl, Philipp}, |
| booktitle={ICCV}, |
| year={2017} |
| } |
| </pre> |