| commit | 4d9667121ae6fb643f2a02ab15e25231ed756cde | [log] [tgz] |
|---|---|---|
| author | stephenrawls <10453511+stephenrawls@users.noreply.github.com> | Wed Jun 19 20:55:33 2019 -0700 |
| committer | Sheng Zha <szha@users.noreply.github.com> | Wed Jun 19 20:55:33 2019 -0700 |
| tree | 485d8c372db11c44059d6ee35a5c4cfff960e8c4 | |
| parent | 145f82d820f94f2930a340f1d2148cd81077ff93 [diff] |
fixing var-seq-len rnn backward() operator (#15278) * fixing var-seq-len rnn backward() operator * updating var-length lstm to test backward pass * removing bit of dbg print to stderr i forgot to remove earlier * resolving TODO about using int32 for sequence_length * setting rtol and atol similar to other tests in this file
| Master | Docs | License |
|---|---|---|
 |
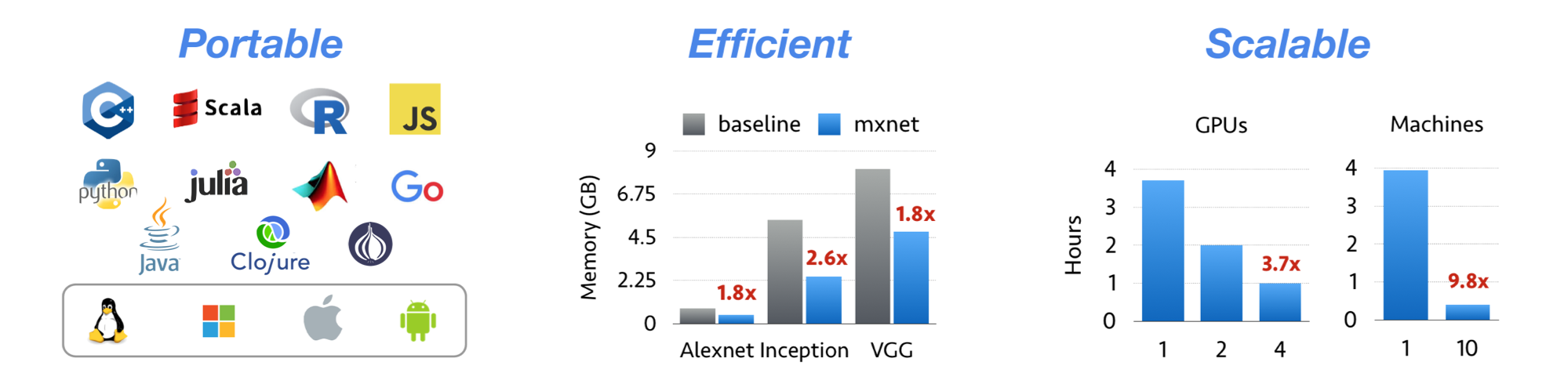
Apache MXNet (incubating) is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scaling effectively to multiple GPUs and multiple machines.
MXNet is more than a deep learning project. It is a collection of blue prints and guidelines for building deep learning systems, and interesting insights of DL systems for hackers.
Licensed under an Apache-2.0 license.
Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems. In Neural Information Processing Systems, Workshop on Machine Learning Systems, 2015
MXNet emerged from a collaboration by the authors of cxxnet, minerva, and purine2. The project reflects what we have learned from the past projects. MXNet combines aspects of each of these projects to achieve flexibility, speed, and memory efficiency.