This example demonstrates how a BiLSTM-CRF model can be implemented in Gluon to perform noun-phrase chunking as a sequence labeling task. In this example we define the following training sample:
georgia tech is a university in georgia B I O O O O B
The second line is the IOB representation of the above sentence that is learnt by the model. I stands for in chunk, O for out of a chunk and B for beginning of junks.
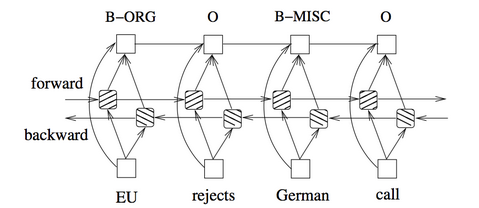
The model consists of an LSTM layer with 2 hidden units and a CRF layer. The CRF layer has a state transition matrix which allows to take past and future tags into account when predicting the current tag. The bidirectional LSTM is reading the word sequence from beginning to end and vice versa. It prodcues a vector representation for the words. The following image is taken from https://arxiv.org/pdf/1508.01991v1.pdf and shows the model architecture:
You can run the example by executing
python lstm_crf.py
The example code does not take any commandline arguments. If you want to change the number of hidden units or the size of vectors embeddings, then you need to change the variables EMBEDDING_DIM and HIDDEN_DIM.