| commit | 8c81ee48c197dd66276fa8d4008cbad0dcd2c8fb | [log] [tgz] |
|---|---|---|
| author | Arik Poznanski <arikpoz@users.noreply.github.com> | Thu Jun 29 02:11:52 2017 +0300 |
| committer | Eric Junyuan Xie <piiswrong@users.noreply.github.com> | Wed Jun 28 16:11:52 2017 -0700 |
| tree | 845dde7223f4c8eae5640765aa5afb9bfb610edf | |
| parent | 09e08f59ffb092bd1a28bfc27531e04ccaa56386 [diff] |
* extended caffe to mxnet converter and improved converter test (#6822) - added support for networks which uses batch normalization without a scale layer following the batch norm, i.e. gamma is fixed to 1 - extended naming convention used when implementing batch normalization in caffe - added support for old caffe versions where dilation didn't exist. This is needed to convert models which depends on old caffe - added support for deconvolution layer - added support for older version of caffe where kernel_size, pad and stride parameters were not iterable - fixed crash happening when a bottom layer doesn't exist in the internal top_to_layers dictionary, this can happen if the name of the input is not 'data' - added ignore-by-design support for converting 'Crop' layers - fixed batch norm layer comparison to take into account the rescaling factor - added careful condition in tester to swap (RGB,BGR) input channels only if they are of size 3 or 4, which is the same check the conversion does - allow comparing layers of models with no mean file - added support for comparing the parameters of deconvolution layers


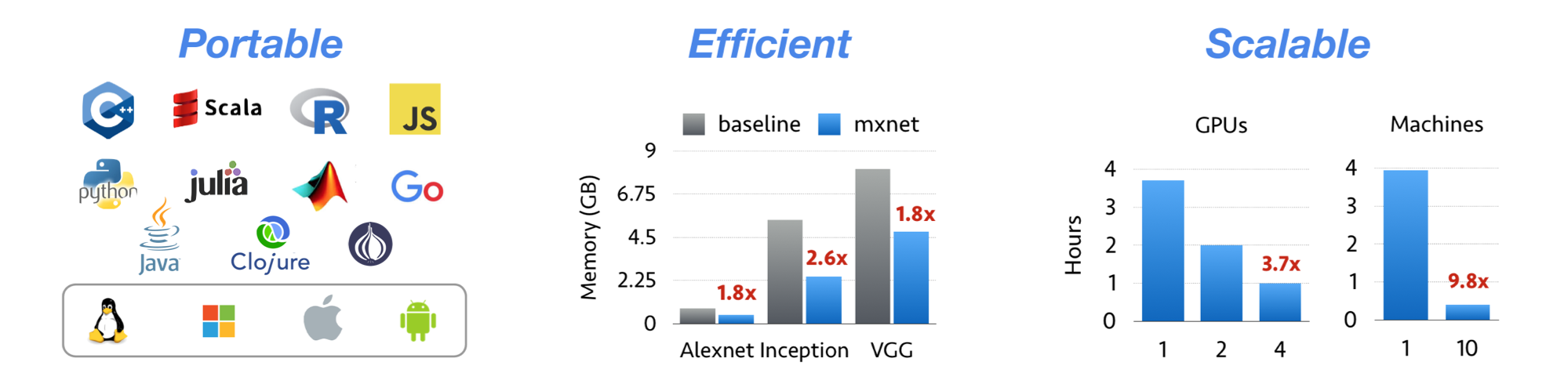
MXNet is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scaling effectively to multiple GPUs and multiple machines.
MXNet is also more than a deep learning project. It is also a collection of blue prints and guidelines for building deep learning systems, and interesting insights of DL systems for hackers.

© Contributors, 2015-2017. Licensed under an Apache-2.0 license.
Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems. In Neural Information Processing Systems, Workshop on Machine Learning Systems, 2015
MXNet emerged from a collaboration by the authors of cxxnet, minerva, and purine2. The project reflects what we have learned from the past projects. MXNet combines aspects of each of these projects to achieve flexibility, speed, and memory efficiency.