| <!-- |
| |
| Licensed to the Apache Software Foundation (ASF) under one |
| or more contributor license agreements. See the NOTICE file |
| distributed with this work for additional information |
| regarding copyright ownership. The ASF licenses this file |
| to you under the Apache License, Version 2.0 (the |
| "License"); you may not use this file except in compliance |
| with the License. You may obtain a copy of the License at |
| |
| http://www.apache.org/licenses/LICENSE-2.0 |
| |
| Unless required by applicable law or agreed to in writing, |
| software distributed under the License is distributed on an |
| "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY |
| KIND, either express or implied. See the License for the |
| specific language governing permissions and limitations |
| under the License. |
| |
| --> |
| |
| |
| ## 触发器 |
| ### 使用说明 |
| |
| 触发器提供了一种侦听序列数据变动的机制。配合用户自定义逻辑,可完成告警、数据转发等功能。 |
| |
| 触发器基于 Java 反射机制实现。用户通过简单实现 Java 接口,即可实现数据侦听。IoTDB 允许用户动态注册、卸载触发器,在注册、卸载期间,无需启停服务器。 |
| |
| #### 侦听模式 |
| |
| IoTDB 的单个触发器可用于侦听符合特定模式的时间序列的数据变动,如时间序列 root.sg.a 上的数据变动,或者符合路径模式 root.**.a 的时间序列上的数据变动。您在注册触发器时可以通过 SQL 语句指定触发器侦听的路径模式。 |
| |
| #### 触发器类型 |
| |
| 目前触发器分为两类,您在注册触发器时可以通过 SQL 语句指定类型: |
| |
| - 有状态的触发器。该类触发器的执行逻辑可能依赖前后的多条数据,框架会将不同节点写入的数据汇总到同一个触发器实例进行计算,来保留上下文信息,通常用于采样或者统计一段时间的数据聚合信息。集群中只有一个节点持有有状态触发器的实例。 |
| - 无状态的触发器。触发器的执行逻辑只和当前输入的数据有关,框架无需将不同节点的数据汇总到同一个触发器实例中,通常用于单行数据的计算和异常检测等。集群中每个节点均持有无状态触发器的实例。 |
| |
| #### 触发时机 |
| |
| 触发器的触发时机目前有两种,后续会拓展其它触发时机。您在注册触发器时可以通过 SQL 语句指定触发时机: |
| |
| - BEFORE INSERT,即在数据持久化之前触发。请注意,目前触发器并不支持数据清洗,不会对要持久化的数据本身进行变动。 |
| - AFTER INSERT,即在数据持久化之后触发。 |
| |
| ### 编写触发器 |
| |
| #### 触发器依赖 |
| |
| 触发器的逻辑需要您编写 Java 类进行实现。 |
| 在编写触发器逻辑时,需要使用到下面展示的依赖。如果您使用 [Maven](http://search.maven.org/),则可以直接从 [Maven 库](http://search.maven.org/)中搜索到它们。请注意选择和目标服务器版本相同的依赖版本。 |
| |
| ``` xml |
| <dependency> |
| <groupId>org.apache.iotdb</groupId> |
| <artifactId>iotdb-server</artifactId> |
| <version>1.0.0</version> |
| <scope>provided</scope> |
| </dependency> |
| ``` |
| |
| #### 接口说明 |
| |
| 编写一个触发器需要实现 `org.apache.iotdb.trigger.api.Trigger` 类。 |
| |
| ```java |
| import org.apache.iotdb.trigger.api.enums.FailureStrategy; |
| import org.apache.iotdb.tsfile.write.record.Tablet; |
| |
| public interface Trigger { |
| |
| /** |
| * This method is mainly used to validate {@link TriggerAttributes} before calling {@link |
| * Trigger#onCreate(TriggerAttributes)}. |
| * |
| * @param attributes TriggerAttributes |
| * @throws Exception e |
| */ |
| default void validate(TriggerAttributes attributes) throws Exception {} |
| |
| /** |
| * This method will be called when creating a trigger after validation. |
| * |
| * @param attributes TriggerAttributes |
| * @throws Exception e |
| */ |
| default void onCreate(TriggerAttributes attributes) throws Exception {} |
| |
| /** |
| * This method will be called when dropping a trigger. |
| * |
| * @throws Exception e |
| */ |
| default void onDrop() throws Exception {} |
| |
| /** |
| * When restarting a DataNode, Triggers that have been registered will be restored and this method |
| * will be called during the process of restoring. |
| * |
| * @throws Exception e |
| */ |
| default void restore() throws Exception {} |
| |
| /** |
| * Overrides this method to set the expected FailureStrategy, {@link FailureStrategy#OPTIMISTIC} |
| * is the default strategy. |
| * |
| * @return {@link FailureStrategy} |
| */ |
| default FailureStrategy getFailureStrategy() { |
| return FailureStrategy.OPTIMISTIC; |
| } |
| |
| /** |
| * @param tablet see {@link Tablet} for detailed information of data structure. Data that is |
| * inserted will be constructed as a Tablet and you can define process logic with {@link |
| * Tablet}. |
| * @return true if successfully fired |
| * @throws Exception e |
| */ |
| default boolean fire(Tablet tablet) throws Exception { |
| return true; |
| } |
| } |
| ``` |
| |
| 该类主要提供了两类编程接口:**生命周期相关接口**和**数据变动侦听相关接口**。该类中所有的接口都不是必须实现的,当您不实现它们时,它们不会对流经的数据操作产生任何响应。您可以根据实际需要,只实现其中若干接口。 |
| |
| 下面是所有可供用户进行实现的接口的说明。 |
| |
| ##### 生命周期相关接口 |
| |
| | 接口定义 | 描述 | |
| | ------------------------------------------------------------ | ------------------------------------------------------------ | |
| | *default void validate(TriggerAttributes attributes) throws Exception {}* | 用户在使用 `CREATE TRIGGER` 语句创建触发器时,可以指定触发器需要使用的参数,该接口会用于验证参数正确性。 | |
| | *default void onCreate(TriggerAttributes attributes) throws Exception {}* | 当您使用`CREATE TRIGGER`语句创建触发器后,该接口会被调用一次。在每一个触发器实例的生命周期内,该接口会且仅会被调用一次。该接口主要有如下作用:帮助用户解析 SQL 语句中的自定义属性(使用`TriggerAttributes`)。 可以创建或申请资源,如建立外部链接、打开文件等。 | |
| | *default void onDrop() throws Exception {}* | 当您使用`DROP TRIGGER`语句删除触发器后,该接口会被调用。在每一个触发器实例的生命周期内,该接口会且仅会被调用一次。该接口主要有如下作用:可以进行资源释放的操作。可以用于持久化触发器计算的结果。 | |
| | *default void restore() throws Exception {}* | 当重启 DataNode 时,集群会恢复 DataNode 上已经注册的触发器实例,在此过程中会为该 DataNode 上的有状态触发器调用一次该接口。有状态触发器实例所在的 DataNode 宕机后,集群会在另一个可用 DataNode 上恢复该触发器的实例,在此过程中会调用一次该接口。该接口可以用于自定义恢复逻辑。 | |
| |
| ##### 数据变动侦听相关接口 |
| |
| ###### 侦听接口 |
| |
| ```java |
| /** |
| * @param tablet see {@link Tablet} for detailed information of data structure. Data that is |
| * inserted will be constructed as a Tablet and you can define process logic with {@link |
| * Tablet}. |
| * @return true if successfully fired |
| * @throws Exception e |
| */ |
| default boolean fire(Tablet tablet) throws Exception { |
| return true; |
| } |
| ``` |
| |
| 数据变动时,触发器以 Tablet 作为触发操作的单位。您可以通过 Tablet 获取相应序列的元数据和数据,然后进行相应的触发操作,触发成功则返回值应当为 true。该接口返回 false 或是抛出异常我们均认为触发失败。在触发失败时,我们会根据侦听策略接口进行相应的操作。 |
| |
| 进行一次 INSERT 操作时,对于其中的每条时间序列,我们会检测是否有侦听该路径模式的触发器,然后将符合同一个触发器所侦听的路径模式的时间序列数据组装成一个新的 Tablet 用于触发器的 fire 接口。可以理解成: |
| |
| ```java |
| Map<PartialPath, List<Trigger>> pathToTriggerListMap => Map<Trigger, Tablet> |
| ``` |
| |
| **请注意,目前我们不对触发器的触发顺序有任何保证。** |
| |
| 下面是示例: |
| |
| 假设有三个触发器,触发器的触发时机均为 BEFORE INSERT |
| |
| - 触发器 Trigger1 侦听路径模式:root.sg.* |
| - 触发器 Trigger2 侦听路径模式:root.sg.a |
| - 触发器 Trigger3 侦听路径模式:root.sg.b |
| |
| 写入语句: |
| |
| ```sql |
| insert into root.sg(time, a, b) values (1, 1, 1); |
| ``` |
| |
| 序列 root.sg.a 匹配 Trigger1 和 Trigger2,序列 root.sg.b 匹配 Trigger1 和 Trigger3,那么: |
| |
| - root.sg.a 和 root.sg.b 的数据会被组装成一个新的 tablet1,在相应的触发时机进行 Trigger1.fire(tablet1) |
| - root.sg.a 的数据会被组装成一个新的 tablet2,在相应的触发时机进行 Trigger2.fire(tablet2) |
| - root.sg.b 的数据会被组装成一个新的 tablet3,在相应的触发时机进行 Trigger3.fire(tablet3) |
| |
| ###### 侦听策略接口 |
| |
| 在触发器触发失败时,我们会根据侦听策略接口设置的策略进行相应的操作,您可以通过下述接口设置 `org.apache.iotdb.trigger.api.enums.FailureStrategy`,目前有乐观和悲观两种策略: |
| |
| - 乐观策略:触发失败的触发器不影响后续触发器的触发,也不影响写入流程,即我们不对触发失败涉及的序列做额外处理,仅打日志记录失败,最后返回用户写入数据成功,但触发部分失败。 |
| - 悲观策略:失败触发器影响后续所有 Pipeline 的处理,即我们认为该 Trigger 触发失败会导致后续所有触发流程不再进行。如果该触发器的触发时机为 BEFORE INSERT,那么写入也不再进行,直接返回写入失败。 |
| |
| ```java |
| /** |
| * Overrides this method to set the expected FailureStrategy, {@link FailureStrategy#OPTIMISTIC} |
| * is the default strategy. |
| * |
| * @return {@link FailureStrategy} |
| */ |
| default FailureStrategy getFailureStrategy() { |
| return FailureStrategy.OPTIMISTIC; |
| } |
| ``` |
| |
| 您可以参考下图辅助理解,其中 Trigger1 配置采用乐观策略,Trigger2 配置采用悲观策略。Trigger1 和 Trigger2 的触发时机是 BEFORE INSERT,Trigger3 和 Trigger4 的触发时机是 AFTER INSERT。 正常执行流程如下: |
| |
| <img src="https://alioss.timecho.com/docs/img/UserGuide/Process-Data/Triggers/Trigger_Process_Flow.jpg?raw=true"> |
| |
| <img src="https://alioss.timecho.com/docs/img/UserGuide/Process-Data/Triggers/Trigger_Process_Strategy.jpg?raw=true"> |
| |
| |
| #### 示例 |
| |
| 如果您使用 [Maven](http://search.maven.org/),可以参考我们编写的示例项目 trigger-example。您可以在 [这里](https://github.com/apache/iotdb/tree/master/example/trigger) 找到它。后续我们会加入更多的示例项目供您参考。 |
| |
| 下面是其中一个示例项目的代码: |
| |
| ```java |
| /* |
| * Licensed to the Apache Software Foundation (ASF) under one |
| * or more contributor license agreements. See the NOTICE file |
| * distributed with this work for additional information |
| * regarding copyright ownership. The ASF licenses this file |
| * to you under the Apache License, Version 2.0 (the |
| * "License"); you may not use this file except in compliance |
| * with the License. You may obtain a copy of the License at |
| * |
| * http://www.apache.org/licenses/LICENSE-2.0 |
| * |
| * Unless required by applicable law or agreed to in writing, |
| * software distributed under the License is distributed on an |
| * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY |
| * KIND, either express or implied. See the License for the |
| * specific language governing permissions and limitations |
| * under the License. |
| */ |
| |
| package org.apache.iotdb.trigger; |
| |
| import org.apache.iotdb.db.engine.trigger.sink.alertmanager.AlertManagerConfiguration; |
| import org.apache.iotdb.db.engine.trigger.sink.alertmanager.AlertManagerEvent; |
| import org.apache.iotdb.db.engine.trigger.sink.alertmanager.AlertManagerHandler; |
| import org.apache.iotdb.trigger.api.Trigger; |
| import org.apache.iotdb.trigger.api.TriggerAttributes; |
| import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType; |
| import org.apache.iotdb.tsfile.write.record.Tablet; |
| import org.apache.iotdb.tsfile.write.schema.MeasurementSchema; |
| |
| import org.slf4j.Logger; |
| import org.slf4j.LoggerFactory; |
| |
| import java.io.IOException; |
| import java.util.HashMap; |
| import java.util.List; |
| |
| public class ClusterAlertingExample implements Trigger { |
| private static final Logger LOGGER = LoggerFactory.getLogger(ClusterAlertingExample.class); |
| |
| private final AlertManagerHandler alertManagerHandler = new AlertManagerHandler(); |
| |
| private final AlertManagerConfiguration alertManagerConfiguration = |
| new AlertManagerConfiguration("http://127.0.0.1:9093/api/v2/alerts"); |
| |
| private String alertname; |
| |
| private final HashMap<String, String> labels = new HashMap<>(); |
| |
| private final HashMap<String, String> annotations = new HashMap<>(); |
| |
| @Override |
| public void onCreate(TriggerAttributes attributes) throws Exception { |
| alertname = "alert_test"; |
| |
| labels.put("series", "root.ln.wf01.wt01.temperature"); |
| labels.put("value", ""); |
| labels.put("severity", ""); |
| |
| annotations.put("summary", "high temperature"); |
| annotations.put("description", "{{.alertname}}: {{.series}} is {{.value}}"); |
| |
| alertManagerHandler.open(alertManagerConfiguration); |
| } |
| |
| @Override |
| public void onDrop() throws IOException { |
| alertManagerHandler.close(); |
| } |
| |
| @Override |
| public boolean fire(Tablet tablet) throws Exception { |
| List<MeasurementSchema> measurementSchemaList = tablet.getSchemas(); |
| for (int i = 0, n = measurementSchemaList.size(); i < n; i++) { |
| if (measurementSchemaList.get(i).getType().equals(TSDataType.DOUBLE)) { |
| // for example, we only deal with the columns of Double type |
| double[] values = (double[]) tablet.values[i]; |
| for (double value : values) { |
| if (value > 100.0) { |
| LOGGER.info("trigger value > 100"); |
| labels.put("value", String.valueOf(value)); |
| labels.put("severity", "critical"); |
| AlertManagerEvent alertManagerEvent = |
| new AlertManagerEvent(alertname, labels, annotations); |
| alertManagerHandler.onEvent(alertManagerEvent); |
| } else if (value > 50.0) { |
| LOGGER.info("trigger value > 50"); |
| labels.put("value", String.valueOf(value)); |
| labels.put("severity", "warning"); |
| AlertManagerEvent alertManagerEvent = |
| new AlertManagerEvent(alertname, labels, annotations); |
| alertManagerHandler.onEvent(alertManagerEvent); |
| } |
| } |
| } |
| } |
| return true; |
| } |
| } |
| ``` |
| ### 管理触发器 |
| |
| 您可以通过 SQL 语句注册和卸载一个触发器实例,您也可以通过 SQL 语句查询到所有已经注册的触发器。 |
| |
| **我们建议您在注册触发器时停止写入。** |
| |
| #### 注册触发器 |
| |
| 触发器可以注册在任意路径模式上。被注册有触发器的序列将会被触发器侦听,当序列上有数据变动时,触发器中对应的触发方法将会被调用。 |
| |
| 注册一个触发器可以按如下流程进行: |
| |
| 1. 按照编写触发器章节的说明,实现一个完整的 Trigger 类,假定这个类的全类名为 `org.apache.iotdb.trigger.ClusterAlertingExample` |
| 2. 将项目打成 JAR 包。 |
| 3. 使用 SQL 语句注册该触发器。注册过程中会仅只会调用一次触发器的 `validate` 和 `onCreate` 接口,具体请参考编写触发器章节。 |
| |
| 完整 SQL 语法如下: |
| |
| ```sql |
| // Create Trigger |
| createTrigger |
| : CREATE triggerType TRIGGER triggerName=identifier triggerEventClause ON pathPattern AS className=STRING_LITERAL uriClause? triggerAttributeClause? |
| ; |
| |
| triggerType |
| : STATELESS | STATEFUL |
| ; |
| |
| triggerEventClause |
| : (BEFORE | AFTER) INSERT |
| ; |
| |
| uriClause |
| : USING URI uri |
| ; |
| |
| uri |
| : STRING_LITERAL |
| ; |
| |
| triggerAttributeClause |
| : WITH LR_BRACKET triggerAttribute (COMMA triggerAttribute)* RR_BRACKET |
| ; |
| |
| triggerAttribute |
| : key=attributeKey operator_eq value=attributeValue |
| ; |
| ``` |
| |
| 下面对 SQL 语法进行说明,您可以结合使用说明章节进行理解: |
| |
| - triggerName:触发器 ID,该 ID 是全局唯一的,用于区分不同触发器,大小写敏感。 |
| - triggerType:触发器类型,分为无状态(STATELESS)和有状态(STATEFUL)两类。 |
| - triggerEventClause:触发时机,目前仅支持写入前(BEFORE INSERT)和写入后(AFTER INSERT)两种。 |
| - pathPattern:触发器侦听的路径模式,可以包含通配符 * 和 **。 |
| - className:触发器实现类的类名。 |
| - uriClause:可选项,当不指定该选项时,我们默认 DBA 已经在各个 DataNode 节点的 trigger_root_dir 目录(配置项,默认为 IOTDB_HOME/ext/trigger)下放置好创建该触发器需要的 JAR 包。当指定该选项时,我们会将该 URI 对应的文件资源下载并分发到各 DataNode 的 trigger_root_dir/install 目录下。 |
| - triggerAttributeClause:用于指定触发器实例创建时需要设置的参数,SQL 语法中该部分是可选项。 |
| |
| 下面是一个帮助您理解的 SQL 语句示例: |
| |
| ```sql |
| CREATE STATELESS TRIGGER triggerTest |
| BEFORE INSERT |
| ON root.sg.** |
| AS 'org.apache.iotdb.trigger.ClusterAlertingExample' |
| USING URI 'http://jar/ClusterAlertingExample.jar' |
| WITH ( |
| "name" = "trigger", |
| "limit" = "100" |
| ) |
| ``` |
| |
| 上述 SQL 语句创建了一个名为 triggerTest 的触发器: |
| |
| - 该触发器是无状态的(STATELESS) |
| - 在写入前触发(BEFORE INSERT) |
| - 该触发器侦听路径模式为 root.sg.** |
| - 所编写的触发器类名为 org.apache.iotdb.trigger.ClusterAlertingExample |
| - JAR 包的 URI 为 http://jar/ClusterAlertingExample.jar |
| - 创建该触发器实例时会传入 name 和 limit 两个参数。 |
| |
| #### 卸载触发器 |
| |
| 可以通过指定触发器 ID 的方式卸载触发器,卸载触发器的过程中会且仅会调用一次触发器的 `onDrop` 接口。 |
| |
| 卸载触发器的 SQL 语法如下: |
| |
| ```sql |
| // Drop Trigger |
| dropTrigger |
| : DROP TRIGGER triggerName=identifier |
| ; |
| ``` |
| |
| 下面是示例语句: |
| |
| ```sql |
| DROP TRIGGER triggerTest1 |
| ``` |
| |
| 上述语句将会卸载 ID 为 triggerTest1 的触发器。 |
| |
| #### 查询触发器 |
| |
| 可以通过 SQL 语句查询集群中存在的触发器的信息。SQL 语法如下: |
| |
| ```sql |
| SHOW TRIGGERS |
| ``` |
| |
| 该语句的结果集格式如下: |
| |
| | TriggerName | Event | Type | State | PathPattern | ClassName | NodeId | |
| | ------------ | ---------------------------- | -------------------- | ------------------------------------------- | ----------- | --------------------------------------- | --------------------------------------- | |
| | triggerTest1 | BEFORE_INSERT / AFTER_INSERT | STATELESS / STATEFUL | INACTIVE / ACTIVE / DROPPING / TRANSFFERING | root.** | org.apache.iotdb.trigger.TriggerExample | ALL(STATELESS) / DATA_NODE_ID(STATEFUL) | |
| |
| |
| #### 触发器状态说明 |
| |
| 在集群中注册以及卸载触发器的过程中,我们维护了触发器的状态,下面是对这些状态的说明: |
| |
| | 状态 | 描述 | 是否建议写入进行 | |
| | ------------ | ------------------------------------------------------------ | ---------------- | |
| | INACTIVE | 执行 `CREATE TRIGGER` 的中间状态,集群刚在 ConfigNode 上记录该触发器的信息,还未在任何 DataNode 上激活该触发器 | 否 | |
| | ACTIVE | 执行 `CREATE TRIGGE` 成功后的状态,集群所有 DataNode 上的该触发器都已经可用 | 是 | |
| | DROPPING | 执行 `DROP TRIGGER` 的中间状态,集群正处在卸载该触发器的过程中 | 否 | |
| | TRANSFERRING | 集群正在进行该触发器实例位置的迁移 | 否 | |
| |
| ### 重要注意事项 |
| |
| - 触发器从注册时开始生效,不对已有的历史数据进行处理。**即只有成功注册触发器之后发生的写入请求才会被触发器侦听到。** |
| - 触发器目前采用**同步触发**,所以编写时需要保证触发器效率,否则可能会大幅影响写入性能。**您需要自己保证触发器内部的并发安全性**。 |
| - 集群中**不能注册过多触发器**。因为触发器信息全量保存在 ConfigNode 中,并且在所有 DataNode 都有一份该信息的副本。 |
| - **建议注册触发器时停止写入**。注册触发器并不是一个原子操作,注册触发器时,会出现集群内部分节点已经注册了该触发器,部分节点尚未注册成功的中间状态。为了避免部分节点上的写入请求被触发器侦听到,部分节点上没有被侦听到的情况,我们建议注册触发器时不要执行写入。 |
| - 触发器将作为进程内程序执行,如果您的触发器编写不慎,内存占用过多,由于 IoTDB 并没有办法监控触发器所使用的内存,所以有 OOM 的风险。 |
| - 持有有状态触发器实例的节点宕机时,我们会尝试在另外的节点上恢复相应实例,在恢复过程中我们会调用一次触发器类的 restore 接口,您可以在该接口中实现恢复触发器所维护的状态的逻辑。 |
| - 触发器 JAR 包有大小限制,必须小于 min(`config_node_ratis_log_appender_buffer_size_max`, 2G),其中 `config_node_ratis_log_appender_buffer_size_max` 是一个配置项,具体含义可以参考 IOTDB 配置项说明。 |
| - **不同的 JAR 包中最好不要有全类名相同但功能实现不一样的类**。例如:触发器 trigger1、trigger2 分别对应资源 trigger1.jar、trigger2.jar。如果两个 JAR 包里都包含一个 `org.apache.iotdb.trigger.example.AlertListener` 类,当 `CREATE TRIGGER` 使用到这个类时,系统会随机加载其中一个 JAR 包中的类,最终导致触发器执行行为不一致以及其他的问题。 |
| |
| ### 配置参数 |
| |
| | 配置项 | 含义 | |
| | ------------------------------------------------- | ---------------------------------------------- | |
| | *trigger_lib_dir* | 保存触发器 jar 包的目录位置 | |
| | *stateful\_trigger\_retry\_num\_when\_not\_found* | 有状态触发器触发无法找到触发器实例时的重试次数 | |
| |
| ## 连续查询(Continuous Query, CQ) |
| |
| ### 简介 |
| 连续查询(Continuous queries, aka CQ) 是对实时数据周期性地自动执行的查询,并将查询结果写入指定的时间序列中。 |
| |
| ### 语法 |
| |
| ```sql |
| CREATE (CONTINUOUS QUERY | CQ) <cq_id> |
| [RESAMPLE |
| [EVERY <every_interval>] |
| [BOUNDARY <execution_boundary_time>] |
| [RANGE <start_time_offset>[, end_time_offset]] |
| ] |
| [TIMEOUT POLICY BLOCKED|DISCARD] |
| BEGIN |
| SELECT CLAUSE |
| INTO CLAUSE |
| FROM CLAUSE |
| [WHERE CLAUSE] |
| [GROUP BY(<group_by_interval>[, <sliding_step>]) [, level = <level>]] |
| [HAVING CLAUSE] |
| [FILL {PREVIOUS | LINEAR | constant}] |
| [LIMIT rowLimit OFFSET rowOffset] |
| [ALIGN BY DEVICE] |
| END |
| ``` |
| |
| > 注意: |
| > 1. 如果where子句中出现任何时间过滤条件,IoTDB将会抛出异常,因为IoTDB会自动为每次查询执行指定时间范围。 |
| > 2. GROUP BY TIME CLAUSE在连续查询中的语法稍有不同,它不能包含原来的第一个参数,即 [start_time, end_time),IoTDB会自动填充这个缺失的参数。如果指定,IoTDB将会抛出异常。 |
| > 3. 如果连续查询中既没有GROUP BY TIME子句,也没有指定EVERY子句,IoTDB将会抛出异常。 |
| |
| #### 连续查询语法中参数含义的描述 |
| |
| - `<cq_id>` 为连续查询指定一个全局唯一的标识。 |
| - `<every_interval>` 指定了连续查询周期性执行的间隔。现在支持的时间单位有:ns, us, ms, s, m, h, d, w, 并且它的值不能小于用户在`iotdb-confignode.properties`配置文件中指定的`continuous_query_min_every_interval`。这是一个可选参数,默认等于group by子句中的`group_by_interval`。 |
| - `<start_time_offset>` 指定了每次查询执行窗口的开始时间,即`now()-<start_time_offset>`。现在支持的时间单位有:ns, us, ms, s, m, h, d, w。这是一个可选参数,默认等于`EVERY`子句中的`every_interval`。 |
| - `<end_time_offset>` 指定了每次查询执行窗口的结束时间,即`now()-<end_time_offset>`。现在支持的时间单位有:ns, us, ms, s, m, h, d, w。这是一个可选参数,默认等于`0`. |
| - `<execution_boundary_time>` 表示用户期待的连续查询的首个周期任务的执行时间。(因为连续查询只会对当前实时的数据流做计算,所以该连续查询实际首个周期任务的执行时间并不一定等于用户指定的时间,具体计算逻辑如下所示) |
| - `<execution_boundary_time>` 可以早于、等于或者迟于当前时间。 |
| - 这个参数是可选的,默认等于`0`。 |
| - 首次查询执行窗口的开始时间为`<execution_boundary_time> - <start_time_offset>`. |
| - 首次查询执行窗口的结束时间为`<execution_boundary_time> - <end_time_offset>`. |
| - 第i个查询执行窗口的时间范围是`[<execution_boundary_time> - <start_time_offset> + (i - 1) * <every_interval>, <execution_boundary_time> - <end_time_offset> + (i - 1) * <every_interval>)`。 |
| - 如果当前时间早于或等于, 那连续查询的首个周期任务的执行时间就是用户指定的`execution_boundary_time`. |
| - 如果当前时间迟于用户指定的`execution_boundary_time`,那么连续查询的首个周期任务的执行时间就是`execution_boundary_time + i * <every_interval>`中第一个大于或等于当前时间的值。 |
| |
| > - <every_interval>,<start_time_offset> 和 <group_by_interval> 都应该大于 0 |
| > - <group_by_interval>应该小于等于<start_time_offset> |
| > - 用户应该根据实际需求,为<start_time_offset> 和 <every_interval> 指定合适的值 |
| > - 如果<start_time_offset>大于<every_interval>,在每一次查询执行的时间窗口上会有部分重叠 |
| > - 如果<start_time_offset>小于<every_interval>,在连续的两次查询执行的时间窗口中间将会有未覆盖的时间范围 |
| > - start_time_offset 应该大于end_time_offset |
| |
| ##### `<start_time_offset>`等于`<every_interval>` |
| |
| 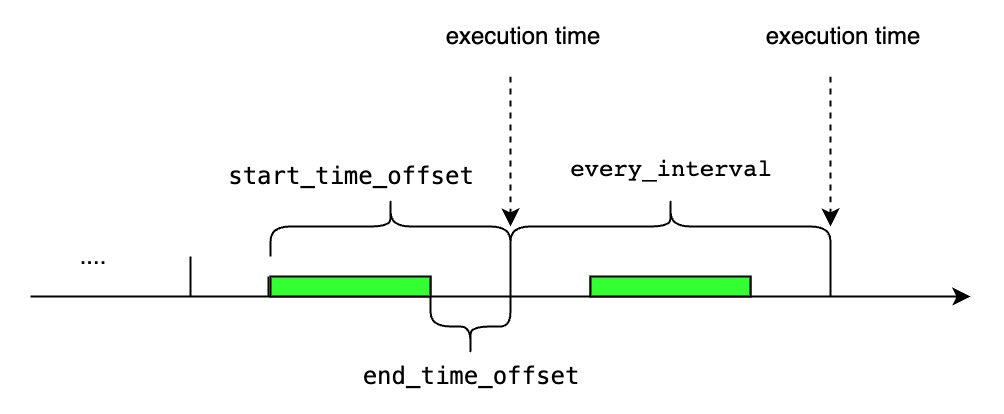 |
| |
| ##### `<start_time_offset>`大于`<every_interval>` |
| |
| 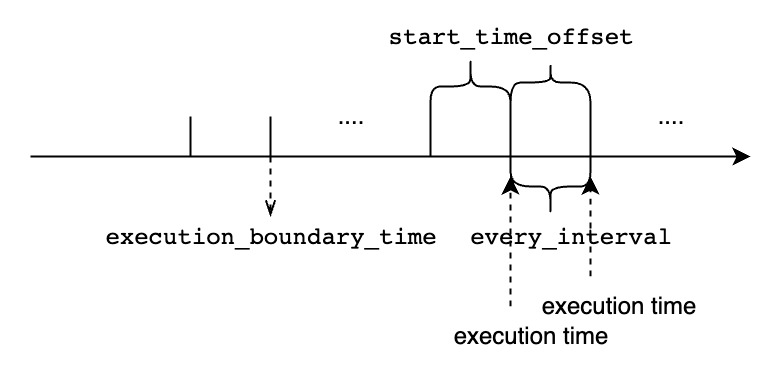 |
| |
| ##### `<start_time_offset>`小于`<every_interval>` |
| |
| 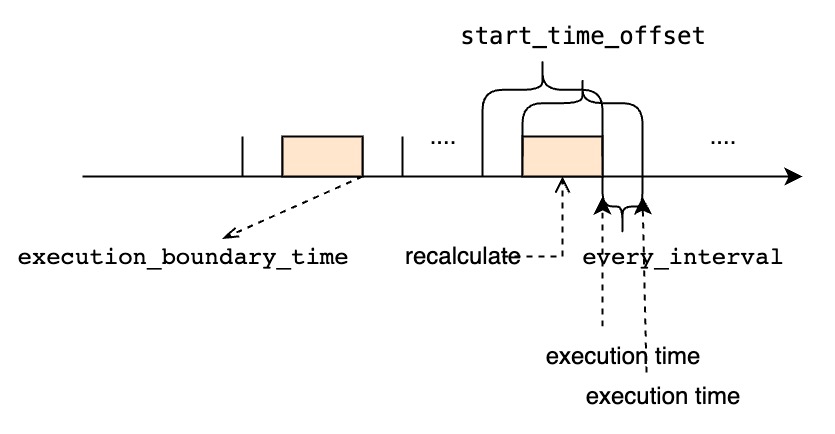 |
| |
| ##### `<every_interval>`不为0 |
| |
| 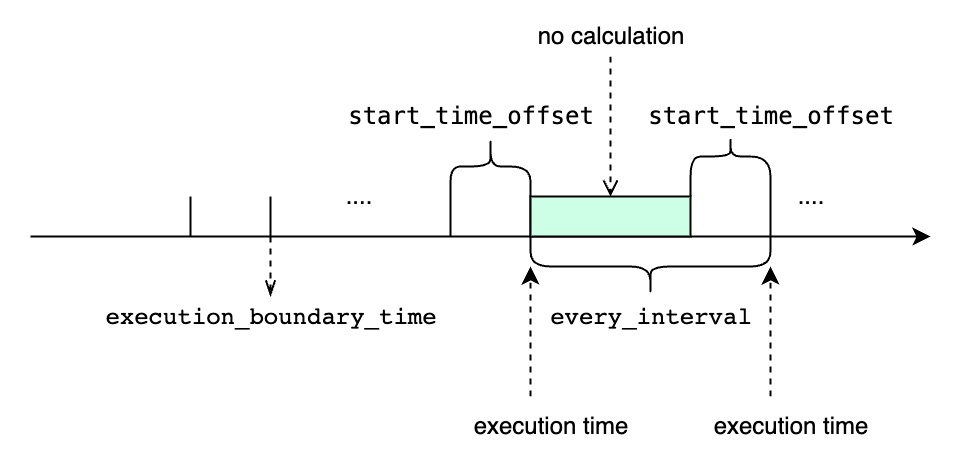 |
| |
| - `TIMEOUT POLICY` 指定了我们如何处理“前一个时间窗口还未执行完时,下一个窗口的执行时间已经到达的场景,默认值是`BLOCKED`. |
| - `BLOCKED`意味着即使下一个窗口的执行时间已经到达,我们依旧需要阻塞等待前一个时间窗口的查询执行完再开始执行下一个窗口。如果使用`BLOCKED`策略,所有的时间窗口都将会被依此执行,但是如果遇到执行查询的时间长于周期性间隔时,连续查询的结果会迟于最新的时间窗口范围。 |
| - `DISCARD`意味着如果前一个时间窗口还未执行完,我们会直接丢弃下一个窗口的执行时间。如果使用`DISCARD`策略,可能会有部分时间窗口得不到执行。但是一旦前一个查询执行完后,它将会使用最新的时间窗口,所以它的执行结果总能赶上最新的时间窗口范围,当然是以部分时间窗口得不到执行为代价。 |
| |
| |
| ### 连续查询的用例 |
| |
| 下面是用例数据,这是一个实时的数据流,我们假设数据都按时到达。 |
| |
| ```` |
| +-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+ |
| | Time|root.ln.wf02.wt02.temperature|root.ln.wf02.wt01.temperature|root.ln.wf01.wt02.temperature|root.ln.wf01.wt01.temperature| |
| +-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+ |
| |2021-05-11T22:18:14.598+08:00| 121.0| 72.0| 183.0| 115.0| |
| |2021-05-11T22:18:19.941+08:00| 0.0| 68.0| 68.0| 103.0| |
| |2021-05-11T22:18:24.949+08:00| 122.0| 45.0| 11.0| 14.0| |
| |2021-05-11T22:18:29.967+08:00| 47.0| 14.0| 59.0| 181.0| |
| |2021-05-11T22:18:34.979+08:00| 182.0| 113.0| 29.0| 180.0| |
| |2021-05-11T22:18:39.990+08:00| 42.0| 11.0| 52.0| 19.0| |
| |2021-05-11T22:18:44.995+08:00| 78.0| 38.0| 123.0| 52.0| |
| |2021-05-11T22:18:49.999+08:00| 137.0| 172.0| 135.0| 193.0| |
| |2021-05-11T22:18:55.003+08:00| 16.0| 124.0| 183.0| 18.0| |
| +-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+ |
| ```` |
| |
| #### 配置连续查询执行的周期性间隔 |
| |
| 在`RESAMPLE`子句中使用`EVERY`参数指定连续查询的执行间隔,如果没有指定,默认等于`group_by_interval`。 |
| |
| ```sql |
| CREATE CONTINUOUS QUERY cq1 |
| RESAMPLE EVERY 20s |
| BEGIN |
| SELECT max_value(temperature) |
| INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max) |
| FROM root.ln.*.* |
| GROUP BY(10s) |
| END |
| ``` |
| |
| `cq1`计算出`temperature`传感器每10秒的平均值,并且将查询结果存储在`temperature_max`传感器下,传感器路径前缀使用跟原来一样的前缀。 |
| |
| `cq1`每20秒执行一次,每次执行的查询的时间窗口范围是从过去20秒到当前时间。 |
| |
| 假设当前时间是`2021-05-11T22:18:40.000+08:00`,如果把日志等级设置为DEBUG,我们可以在`cq1`执行的DataNode上看到如下的输出: |
| |
| ```` |
| At **2021-05-11T22:18:40.000+08:00**, `cq1` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:18:40)`. |
| `cq1` generate 2 lines: |
| > |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0| |
| |2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| > |
| At **2021-05-11T22:19:00.000+08:00**, `cq1` executes a query within the time range `[2021-05-11T22:18:40, 2021-05-11T22:19:00)`. |
| `cq1` generate 2 lines: |
| > |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0| |
| |2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| > |
| ```` |
| |
| `cq1`并不会处理当前时间窗口以外的数据,即`2021-05-11T22:18:20.000+08:00`以前的数据,所以我们会得到如下结果: |
| |
| ```` |
| > SELECT temperature_max from root.ln.*.*; |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0| |
| |2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0| |
| |2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0| |
| |2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| ```` |
| |
| #### 配置连续查询的时间窗口大小 |
| |
| 使用`RANGE`子句中的`start_time_offset`参数指定连续查询每次执行的时间窗口的开始时间偏移,如果没有指定,默认值等于`EVERY`参数。 |
| |
| ```sql |
| CREATE CONTINUOUS QUERY cq2 |
| RESAMPLE RANGE 40s |
| BEGIN |
| SELECT max_value(temperature) |
| INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max) |
| FROM root.ln.*.* |
| GROUP BY(10s) |
| END |
| ``` |
| |
| `cq2`计算出`temperature`传感器每10秒的平均值,并且将查询结果存储在`temperature_max`传感器下,传感器路径前缀使用跟原来一样的前缀。 |
| |
| `cq2`每10秒执行一次,每次执行的查询的时间窗口范围是从过去40秒到当前时间。 |
| |
| 假设当前时间是`2021-05-11T22:18:40.000+08:00`,如果把日志等级设置为DEBUG,我们可以在`cq2`执行的DataNode上看到如下的输出: |
| |
| ```` |
| At **2021-05-11T22:18:40.000+08:00**, `cq2` executes a query within the time range `[2021-05-11T22:18:00, 2021-05-11T22:18:40)`. |
| `cq2` generate 4 lines: |
| > |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:00.000+08:00| NULL| NULL| NULL| NULL| |
| |2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0| |
| |2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0| |
| |2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| > |
| At **2021-05-11T22:18:50.000+08:00**, `cq2` executes a query within the time range `[2021-05-11T22:18:10, 2021-05-11T22:18:50)`. |
| `cq2` generate 4 lines: |
| > |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0| |
| |2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0| |
| |2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0| |
| |2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| > |
| At **2021-05-11T22:19:00.000+08:00**, `cq2` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:19:00)`. |
| `cq2` generate 4 lines: |
| > |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0| |
| |2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0| |
| |2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0| |
| |2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| > |
| ```` |
| |
| `cq2`并不会写入全是null值的行,值得注意的是`cq2`会多次计算某些区间的聚合值,下面是计算结果: |
| |
| ```` |
| > SELECT temperature_max from root.ln.*.*; |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0| |
| |2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0| |
| |2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0| |
| |2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0| |
| |2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| ```` |
| |
| #### 同时配置连续查询执行的周期性间隔和时间窗口大小 |
| |
| 使用`RESAMPLE`子句中的`EVERY`参数和`RANGE`参数分别指定连续查询的执行间隔和窗口大小。并且使用`fill()`来填充没有值的时间区间。 |
| |
| ```sql |
| CREATE CONTINUOUS QUERY cq3 |
| RESAMPLE EVERY 20s RANGE 40s |
| BEGIN |
| SELECT max_value(temperature) |
| INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max) |
| FROM root.ln.*.* |
| GROUP BY(10s) |
| FILL(100.0) |
| END |
| ``` |
| |
| `cq3`计算出`temperature`传感器每10秒的平均值,并且将查询结果存储在`temperature_max`传感器下,传感器路径前缀使用跟原来一样的前缀。如果某些区间没有值,用`100.0`填充。 |
| |
| `cq3`每20秒执行一次,每次执行的查询的时间窗口范围是从过去40秒到当前时间。 |
| |
| 假设当前时间是`2021-05-11T22:18:40.000+08:00`,如果把日志等级设置为DEBUG,我们可以在`cq3`执行的DataNode上看到如下的输出: |
| |
| ```` |
| At **2021-05-11T22:18:40.000+08:00**, `cq3` executes a query within the time range `[2021-05-11T22:18:00, 2021-05-11T22:18:40)`. |
| `cq3` generate 4 lines: |
| > |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0| |
| |2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0| |
| |2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0| |
| |2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| > |
| At **2021-05-11T22:19:00.000+08:00**, `cq3` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:19:00)`. |
| `cq3` generate 4 lines: |
| > |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0| |
| |2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0| |
| |2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0| |
| |2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| > |
| ```` |
| |
| 值得注意的是`cq3`会多次计算某些区间的聚合值,下面是计算结果: |
| |
| ```` |
| > SELECT temperature_max from root.ln.*.*; |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0| |
| |2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0| |
| |2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0| |
| |2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0| |
| |2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0| |
| |2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| ```` |
| |
| #### 配置连续查询每次查询执行时间窗口的结束时间 |
| |
| 使用`RESAMPLE`子句中的`EVERY`参数和`RANGE`参数分别指定连续查询的执行间隔和窗口大小。并且使用`fill()`来填充没有值的时间区间。 |
| |
| ```sql |
| CREATE CONTINUOUS QUERY cq4 |
| RESAMPLE EVERY 20s RANGE 40s, 20s |
| BEGIN |
| SELECT max_value(temperature) |
| INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max) |
| FROM root.ln.*.* |
| GROUP BY(10s) |
| FILL(100.0) |
| END |
| ``` |
| |
| `cq4`计算出`temperature`传感器每10秒的平均值,并且将查询结果存储在`temperature_max`传感器下,传感器路径前缀使用跟原来一样的前缀。如果某些区间没有值,用`100.0`填充。 |
| |
| `cq4`每20秒执行一次,每次执行的查询的时间窗口范围是从过去40秒到过去20秒。 |
| |
| 假设当前时间是`2021-05-11T22:18:40.000+08:00`,如果把日志等级设置为DEBUG,我们可以在`cq4`执行的DataNode上看到如下的输出: |
| |
| ```` |
| At **2021-05-11T22:18:40.000+08:00**, `cq4` executes a query within the time range `[2021-05-11T22:18:00, 2021-05-11T22:18:20)`. |
| `cq4` generate 2 lines: |
| > |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0| |
| |2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| > |
| At **2021-05-11T22:19:00.000+08:00**, `cq4` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:18:40)`. |
| `cq4` generate 2 lines: |
| > |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0| |
| |2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| > |
| ```` |
| |
| 值得注意的是`cq4`只会计算每个聚合区间一次,并且每次开始执行计算的时间都会比当前的时间窗口结束时间迟20s, 下面是计算结果: |
| |
| ```` |
| > SELECT temperature_max from root.ln.*.*; |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| | Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| |2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0| |
| |2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0| |
| |2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0| |
| |2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0| |
| +-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+ |
| ```` |
| |
| #### 没有GROUP BY TIME子句的连续查询 |
| |
| 不使用`GROUP BY TIME`子句,并在`RESAMPLE`子句中显式使用`EVERY`参数指定连续查询的执行间隔。 |
| |
| ```sql |
| CREATE CONTINUOUS QUERY cq5 |
| RESAMPLE EVERY 20s |
| BEGIN |
| SELECT temperature + 1 |
| INTO root.precalculated_sg.::(temperature) |
| FROM root.ln.*.* |
| align by device |
| END |
| ``` |
| |
| `cq5`计算以`root.ln`为前缀的所有`temperature + 1`的值,并将结果储存在另一个 database `root.precalculated_sg`中。除 database 名称不同外,目标序列与源序列路径名均相同。 |
| |
| `cq5`每20秒执行一次,每次执行的查询的时间窗口范围是从过去20秒到当前时间。 |
| |
| 假设当前时间是`2021-05-11T22:18:40.000+08:00`,如果把日志等级设置为DEBUG,我们可以在`cq5`执行的DataNode上看到如下的输出: |
| |
| ```` |
| At **2021-05-11T22:18:40.000+08:00**, `cq5` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:18:40)`. |
| `cq5` generate 16 lines: |
| > |
| +-----------------------------+-------------------------------+-----------+ |
| | Time| Device|temperature| |
| +-----------------------------+-------------------------------+-----------+ |
| |2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt02| 123.0| |
| |2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt02| 48.0| |
| |2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt02| 183.0| |
| |2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt02| 45.0| |
| |2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt01| 46.0| |
| |2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt01| 15.0| |
| |2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt01| 114.0| |
| |2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt01| 12.0| |
| |2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt02| 12.0| |
| |2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt02| 60.0| |
| |2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt02| 30.0| |
| |2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt02| 53.0| |
| |2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt01| 15.0| |
| |2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt01| 182.0| |
| |2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt01| 181.0| |
| |2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt01| 20.0| |
| +-----------------------------+-------------------------------+-----------+ |
| > |
| At **2021-05-11T22:19:00.000+08:00**, `cq5` executes a query within the time range `[2021-05-11T22:18:40, 2021-05-11T22:19:00)`. |
| `cq5` generate 12 lines: |
| > |
| +-----------------------------+-------------------------------+-----------+ |
| | Time| Device|temperature| |
| +-----------------------------+-------------------------------+-----------+ |
| |2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt02| 79.0| |
| |2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt02| 138.0| |
| |2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt02| 17.0| |
| |2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt01| 39.0| |
| |2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt01| 173.0| |
| |2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt01| 125.0| |
| |2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt02| 124.0| |
| |2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt02| 136.0| |
| |2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt02| 184.0| |
| |2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt01| 53.0| |
| |2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt01| 194.0| |
| |2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt01| 19.0| |
| +-----------------------------+-------------------------------+-----------+ |
| > |
| ```` |
| |
| `cq5`并不会处理当前时间窗口以外的数据,即`2021-05-11T22:18:20.000+08:00`以前的数据,所以我们会得到如下结果: |
| |
| ```` |
| > SELECT temperature from root.precalculated_sg.*.* align by device; |
| +-----------------------------+-------------------------------+-----------+ |
| | Time| Device|temperature| |
| +-----------------------------+-------------------------------+-----------+ |
| |2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt02| 123.0| |
| |2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt02| 48.0| |
| |2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt02| 183.0| |
| |2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt02| 45.0| |
| |2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt02| 79.0| |
| |2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt02| 138.0| |
| |2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt02| 17.0| |
| |2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt01| 46.0| |
| |2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt01| 15.0| |
| |2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt01| 114.0| |
| |2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt01| 12.0| |
| |2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt01| 39.0| |
| |2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt01| 173.0| |
| |2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt01| 125.0| |
| |2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt02| 12.0| |
| |2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt02| 60.0| |
| |2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt02| 30.0| |
| |2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt02| 53.0| |
| |2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt02| 124.0| |
| |2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt02| 136.0| |
| |2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt02| 184.0| |
| |2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt01| 15.0| |
| |2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt01| 182.0| |
| |2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt01| 181.0| |
| |2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt01| 20.0| |
| |2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt01| 53.0| |
| |2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt01| 194.0| |
| |2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt01| 19.0| |
| +-----------------------------+-------------------------------+-----------+ |
| ```` |
| |
| ### 连续查询的管理 |
| |
| #### 查询系统已有的连续查询 |
| |
| 展示集群中所有的已注册的连续查询 |
| |
| ```sql |
| SHOW (CONTINUOUS QUERIES | CQS) |
| ``` |
| |
| `SHOW (CONTINUOUS QUERIES | CQS)`会将结果集按照`cq_id`排序。 |
| |
| ##### 例子 |
| |
| ```sql |
| SHOW CONTINUOUS QUERIES; |
| ``` |
| |
| 执行以上sql,我们将会得到如下的查询结果: |
| |
| | cq_id | query | state | |
| |:-------------|---------------------------------------------------------------------------------------------------------------------------------------|-------| |
| | s1_count_cq | CREATE CQ s1_count_cq<br/>BEGIN<br/>SELECT count(s1)<br/>INTO root.sg_count.d.count_s1<br/>FROM root.sg.d<br/>GROUP BY(30m)<br/>END | active | |
| |
| |
| #### 删除已有的连续查询 |
| |
| 删除指定的名为cq_id的连续查询: |
| |
| ```sql |
| DROP (CONTINUOUS QUERY | CQ) <cq_id> |
| ``` |
| |
| DROP CQ并不会返回任何结果集。 |
| |
| ##### 例子 |
| |
| 删除名为s1_count_cq的连续查询: |
| |
| ```sql |
| DROP CONTINUOUS QUERY s1_count_cq; |
| ``` |
| |
| #### 修改已有的连续查询 |
| |
| 目前连续查询一旦被创建就不能再被修改。如果想要修改某个连续查询,只能先用`DROP`命令删除它,然后再用`CREATE`命令重新创建。 |
| |
| |
| ### 连续查询的使用场景 |
| |
| #### 对数据进行降采样并对降采样后的数据使用不同的保留策略 |
| |
| 可以使用连续查询,定期将高频率采样的原始数据(如每秒1000个点),降采样(如每秒仅保留一个点)后保存到另一个 database 的同名序列中。高精度的原始数据所在 database 的`TTL`可能设置的比较短,比如一天,而低精度的降采样后的数据所在的 database `TTL`可以设置的比较长,比如一个月,从而达到快速释放磁盘空间的目的。 |
| |
| #### 预计算代价昂贵的查询 |
| |
| 我们可以通过连续查询对一些重复的查询进行预计算,并将查询结果保存在某些目标序列中,这样真实查询并不需要真的再次去做计算,而是直接查询目标序列的结果,从而缩短了查询的时间。 |
| |
| > 预计算查询结果尤其对一些可视化工具渲染时序图和工作台时有很大的加速作用。 |
| |
| #### 作为子查询的替代品 |
| |
| IoTDB现在不支持子查询,但是我们可以通过创建连续查询得到相似的功能。我们可以将子查询注册为一个连续查询,并将子查询的结果物化到目标序列中,外层查询再直接查询哪个目标序列。 |
| |
| ##### 例子 |
| |
| IoTDB并不会接收如下的嵌套子查询。这个查询会计算s1序列每隔30分钟的非空值数量的平均值: |
| |
| ```sql |
| SELECT avg(count_s1) from (select count(s1) as count_s1 from root.sg.d group by([0, now()), 30m)); |
| ``` |
| |
| 为了得到相同的结果,我们可以: |
| |
| **1. 创建一个连续查询** |
| |
| 这一步执行内层子查询部分。下面创建的连续查询每隔30分钟计算一次`root.sg.d.s1`序列的非空值数量,并将结果写入目标序列`root.sg_count.d.count_s1`中。 |
| |
| ```sql |
| CREATE CQ s1_count_cq |
| BEGIN |
| SELECT count(s1) |
| INTO root.sg_count.d.count_s1 |
| FROM root.sg.d |
| GROUP BY(30m) |
| END |
| ``` |
| |
| **2. 查询连续查询的结果** |
| |
| 这一步执行外层查询的avg([...])部分。 |
| |
| 查询序列`root.sg_count.d.count_s1`的值,并计算平均值: |
| |
| ```sql |
| SELECT avg(count_s1) from root.sg_count.d; |
| ``` |
| |
| |
| ### 连续查询相关的配置参数 |
| | 参数名 | 描述 | 类型 | 默认值 | |
| | :---------------------------------- |----------------------|----------|---------------| |
| | `continuous_query_submit_thread` | 用于周期性提交连续查询执行任务的线程数 | int32 | 2 | |
| | `continuous_query_min_every_interval_in_ms` | 系统允许的连续查询最小的周期性时间间隔 | duration | 1000 | |
| |
| ## 用户自定义函数 |
| |
| ### 数据质量函数 |
| #### Completeness |
| |
| ##### 函数简介 |
| |
| 本函数用于计算时间序列的完整性。将输入序列划分为若干个连续且不重叠的窗口,分别计算每一个窗口的完整性,并输出窗口第一个数据点的时间戳和窗口的完整性。 |
| |
| **函数名:** COMPLETENESS |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `window`:窗口大小,它是一个大于0的整数或者一个有单位的正数。前者代表每一个窗口包含的数据点数目,最后一个窗口的数据点数目可能会不足;后者代表窗口的时间跨度,目前支持五种单位,分别是'ms'(毫秒)、's'(秒)、'm'(分钟)、'h'(小时)和'd'(天)。缺省情况下,全部输入数据都属于同一个窗口。 |
| + `downtime`:完整性计算是否考虑停机异常。它的取值为 'true' 或 'false',默认值为 'true'. 在考虑停机异常时,长时间的数据缺失将被视作停机,不对完整性产生影响。 |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE,其中每一个数据点的值的范围都是 [0,1]. |
| |
| **提示:** 只有当窗口内的数据点数目超过10时,才会进行完整性计算。否则,该窗口将被忽略,不做任何输出。 |
| |
| |
| ##### 使用示例 |
| |
| ###### 参数缺省 |
| |
| 在参数缺省的情况下,本函数将会把全部输入数据都作为同一个窗口计算完整性。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select completeness(s1) from root.test.d1 where time <= 2020-01-01 00:00:30 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-----------------------------+ |
| | Time|completeness(root.test.d1.s1)| |
| +-----------------------------+-----------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 0.875| |
| +-----------------------------+-----------------------------+ |
| ``` |
| |
| ###### 指定窗口大小 |
| |
| 在指定窗口大小的情况下,本函数会把输入数据划分为若干个窗口计算完整性。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| |2020-01-01T00:00:32.000+08:00| 130.0| |
| |2020-01-01T00:00:34.000+08:00| 132.0| |
| |2020-01-01T00:00:36.000+08:00| 134.0| |
| |2020-01-01T00:00:38.000+08:00| 136.0| |
| |2020-01-01T00:00:40.000+08:00| 138.0| |
| |2020-01-01T00:00:42.000+08:00| 140.0| |
| |2020-01-01T00:00:44.000+08:00| 142.0| |
| |2020-01-01T00:00:46.000+08:00| 144.0| |
| |2020-01-01T00:00:48.000+08:00| 146.0| |
| |2020-01-01T00:00:50.000+08:00| 148.0| |
| |2020-01-01T00:00:52.000+08:00| 150.0| |
| |2020-01-01T00:00:54.000+08:00| 152.0| |
| |2020-01-01T00:00:56.000+08:00| 154.0| |
| |2020-01-01T00:00:58.000+08:00| 156.0| |
| |2020-01-01T00:01:00.000+08:00| 158.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select completeness(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------------------------------+ |
| | Time|completeness(root.test.d1.s1, "window"="15")| |
| +-----------------------------+--------------------------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 0.875| |
| |2020-01-01T00:00:32.000+08:00| 1.0| |
| +-----------------------------+--------------------------------------------+ |
| ``` |
| |
| #### Consistency |
| |
| ##### 函数简介 |
| |
| 本函数用于计算时间序列的一致性。将输入序列划分为若干个连续且不重叠的窗口,分别计算每一个窗口的一致性,并输出窗口第一个数据点的时间戳和窗口的时效性。 |
| |
| **函数名:** CONSISTENCY |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `window`:窗口大小,它是一个大于0的整数或者一个有单位的正数。前者代表每一个窗口包含的数据点数目,最后一个窗口的数据点数目可能会不足;后者代表窗口的时间跨度,目前支持五种单位,分别是 'ms'(毫秒)、's'(秒)、'm'(分钟)、'h'(小时)和'd'(天)。缺省情况下,全部输入数据都属于同一个窗口。 |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE,其中每一个数据点的值的范围都是 [0,1]. |
| |
| **提示:** 只有当窗口内的数据点数目超过10时,才会进行一致性计算。否则,该窗口将被忽略,不做任何输出。 |
| |
| |
| ##### 使用示例 |
| |
| ###### 参数缺省 |
| |
| 在参数缺省的情况下,本函数将会把全部输入数据都作为同一个窗口计算一致性。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select consistency(s1) from root.test.d1 where time <= 2020-01-01 00:00:30 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+----------------------------+ |
| | Time|consistency(root.test.d1.s1)| |
| +-----------------------------+----------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 0.9333333333333333| |
| +-----------------------------+----------------------------+ |
| ``` |
| |
| ###### 指定窗口大小 |
| |
| 在指定窗口大小的情况下,本函数会把输入数据划分为若干个窗口计算一致性。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| |2020-01-01T00:00:32.000+08:00| 130.0| |
| |2020-01-01T00:00:34.000+08:00| 132.0| |
| |2020-01-01T00:00:36.000+08:00| 134.0| |
| |2020-01-01T00:00:38.000+08:00| 136.0| |
| |2020-01-01T00:00:40.000+08:00| 138.0| |
| |2020-01-01T00:00:42.000+08:00| 140.0| |
| |2020-01-01T00:00:44.000+08:00| 142.0| |
| |2020-01-01T00:00:46.000+08:00| 144.0| |
| |2020-01-01T00:00:48.000+08:00| 146.0| |
| |2020-01-01T00:00:50.000+08:00| 148.0| |
| |2020-01-01T00:00:52.000+08:00| 150.0| |
| |2020-01-01T00:00:54.000+08:00| 152.0| |
| |2020-01-01T00:00:56.000+08:00| 154.0| |
| |2020-01-01T00:00:58.000+08:00| 156.0| |
| |2020-01-01T00:01:00.000+08:00| 158.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select consistency(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------------------------+ |
| | Time|consistency(root.test.d1.s1, "window"="15")| |
| +-----------------------------+-------------------------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 0.9333333333333333| |
| |2020-01-01T00:00:32.000+08:00| 1.0| |
| +-----------------------------+-------------------------------------------+ |
| ``` |
| |
| #### Timeliness |
| |
| ##### 函数简介 |
| |
| 本函数用于计算时间序列的时效性。将输入序列划分为若干个连续且不重叠的窗口,分别计算每一个窗口的时效性,并输出窗口第一个数据点的时间戳和窗口的时效性。 |
| |
| **函数名:** TIMELINESS |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `window`:窗口大小,它是一个大于0的整数或者一个有单位的正数。前者代表每一个窗口包含的数据点数目,最后一个窗口的数据点数目可能会不足;后者代表窗口的时间跨度,目前支持五种单位,分别是 'ms'(毫秒)、's'(秒)、'm'(分钟)、'h'(小时)和'd'(天)。缺省情况下,全部输入数据都属于同一个窗口。 |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE,其中每一个数据点的值的范围都是 [0,1]. |
| |
| **提示:** 只有当窗口内的数据点数目超过10时,才会进行时效性计算。否则,该窗口将被忽略,不做任何输出。 |
| |
| |
| ##### 使用示例 |
| |
| ###### 参数缺省 |
| |
| 在参数缺省的情况下,本函数将会把全部输入数据都作为同一个窗口计算时效性。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select timeliness(s1) from root.test.d1 where time <= 2020-01-01 00:00:30 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+---------------------------+ |
| | Time|timeliness(root.test.d1.s1)| |
| +-----------------------------+---------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 0.9333333333333333| |
| +-----------------------------+---------------------------+ |
| ``` |
| |
| ###### 指定窗口大小 |
| |
| 在指定窗口大小的情况下,本函数会把输入数据划分为若干个窗口计算时效性。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| |2020-01-01T00:00:32.000+08:00| 130.0| |
| |2020-01-01T00:00:34.000+08:00| 132.0| |
| |2020-01-01T00:00:36.000+08:00| 134.0| |
| |2020-01-01T00:00:38.000+08:00| 136.0| |
| |2020-01-01T00:00:40.000+08:00| 138.0| |
| |2020-01-01T00:00:42.000+08:00| 140.0| |
| |2020-01-01T00:00:44.000+08:00| 142.0| |
| |2020-01-01T00:00:46.000+08:00| 144.0| |
| |2020-01-01T00:00:48.000+08:00| 146.0| |
| |2020-01-01T00:00:50.000+08:00| 148.0| |
| |2020-01-01T00:00:52.000+08:00| 150.0| |
| |2020-01-01T00:00:54.000+08:00| 152.0| |
| |2020-01-01T00:00:56.000+08:00| 154.0| |
| |2020-01-01T00:00:58.000+08:00| 156.0| |
| |2020-01-01T00:01:00.000+08:00| 158.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select timeliness(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------------+ |
| | Time|timeliness(root.test.d1.s1, "window"="15")| |
| +-----------------------------+------------------------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 0.9333333333333333| |
| |2020-01-01T00:00:32.000+08:00| 1.0| |
| +-----------------------------+------------------------------------------+ |
| ``` |
| |
| #### Validity |
| |
| ##### 函数简介 |
| |
| 本函数用于计算时间序列的有效性。将输入序列划分为若干个连续且不重叠的窗口,分别计算每一个窗口的有效性,并输出窗口第一个数据点的时间戳和窗口的有效性。 |
| |
| |
| **函数名:** VALIDITY |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `window`:窗口大小,它是一个大于0的整数或者一个有单位的正数。前者代表每一个窗口包含的数据点数目,最后一个窗口的数据点数目可能会不足;后者代表窗口的时间跨度,目前支持五种单位,分别是 'ms'(毫秒)、's'(秒)、'm'(分钟)、'h'(小时)和'd'(天)。缺省情况下,全部输入数据都属于同一个窗口。 |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE,其中每一个数据点的值的范围都是 [0,1]. |
| |
| **提示:** 只有当窗口内的数据点数目超过10时,才会进行有效性计算。否则,该窗口将被忽略,不做任何输出。 |
| |
| |
| ##### 使用示例 |
| |
| ###### 参数缺省 |
| |
| 在参数缺省的情况下,本函数将会把全部输入数据都作为同一个窗口计算有效性。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select validity(s1) from root.test.d1 where time <= 2020-01-01 00:00:30 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------+ |
| | Time|validity(root.test.d1.s1)| |
| +-----------------------------+-------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 0.8833333333333333| |
| +-----------------------------+-------------------------+ |
| ``` |
| |
| ###### 指定窗口大小 |
| |
| 在指定窗口大小的情况下,本函数会把输入数据划分为若干个窗口计算有效性。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| |2020-01-01T00:00:32.000+08:00| 130.0| |
| |2020-01-01T00:00:34.000+08:00| 132.0| |
| |2020-01-01T00:00:36.000+08:00| 134.0| |
| |2020-01-01T00:00:38.000+08:00| 136.0| |
| |2020-01-01T00:00:40.000+08:00| 138.0| |
| |2020-01-01T00:00:42.000+08:00| 140.0| |
| |2020-01-01T00:00:44.000+08:00| 142.0| |
| |2020-01-01T00:00:46.000+08:00| 144.0| |
| |2020-01-01T00:00:48.000+08:00| 146.0| |
| |2020-01-01T00:00:50.000+08:00| 148.0| |
| |2020-01-01T00:00:52.000+08:00| 150.0| |
| |2020-01-01T00:00:54.000+08:00| 152.0| |
| |2020-01-01T00:00:56.000+08:00| 154.0| |
| |2020-01-01T00:00:58.000+08:00| 156.0| |
| |2020-01-01T00:01:00.000+08:00| 158.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select validity(s1,"window"="15") from root.test.d1 where time <= 2020-01-01 00:01:00 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+----------------------------------------+ |
| | Time|validity(root.test.d1.s1, "window"="15")| |
| +-----------------------------+----------------------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 0.8833333333333333| |
| |2020-01-01T00:00:32.000+08:00| 1.0| |
| +-----------------------------+----------------------------------------+ |
| ``` |
| |
| #### Accuracy |
| |
| ##### 函数简介 |
| |
| 本函数基于主数据计算原始时间序列的准确性。 |
| |
| **函数名**:Accuracy |
| |
| **输入序列:** 支持多个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| - `omega`:算法窗口大小,非负整数(单位为毫秒), 在缺省情况下,算法根据不同时间差下的两个元组距离自动估计该参数。 |
| - `eta`:算法距离阈值,正数, 在缺省情况下,算法根据窗口中元组的距离分布自动估计该参数。 |
| - `k`:主数据中的近邻数量,正整数, 在缺省情况下,算法根据主数据中的k个近邻的元组距离自动估计该参数。 |
| |
| **输出序列**:输出单个值,类型为DOUBLE,值的范围为[0,1]。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+------------+------------+------------+------------+------------+ |
| | Time|root.test.t1|root.test.t2|root.test.t3|root.test.m1|root.test.m2|root.test.m3| |
| +-----------------------------+------------+------------+------------+------------+------------+------------+ |
| |2021-07-01T12:00:01.000+08:00| 1704| 1154.55| 0.195| 1704| 1154.55| 0.195| |
| |2021-07-01T12:00:02.000+08:00| 1702| 1152.30| 0.193| 1702| 1152.30| 0.193| |
| |2021-07-01T12:00:03.000+08:00| 1702| 1148.65| 0.192| 1702| 1148.65| 0.192| |
| |2021-07-01T12:00:04.000+08:00| 1701| 1145.20| 0.194| 1701| 1145.20| 0.194| |
| |2021-07-01T12:00:07.000+08:00| 1703| 1150.55| 0.195| 1703| 1150.55| 0.195| |
| |2021-07-01T12:00:08.000+08:00| 1694| 1151.55| 0.193| 1704| 1151.55| 0.193| |
| |2021-07-01T12:01:09.000+08:00| 1705| 1153.55| 0.194| 1705| 1153.55| 0.194| |
| |2021-07-01T12:01:10.000+08:00| 1706| 1152.30| 0.190| 1706| 1152.30| 0.190| |
| +-----------------------------+------------+------------+------------+------------+------------+------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select Accuracy(t1,t2,t3,m1,m2,m3) from root.test |
| ``` |
| |
| 输出序列: |
| |
| |
| ``` |
| +-----------------------------+---------------------------------------------------------------------------------------+ |
| | Time|Accuracy(root.test.t1,root.test.t2,root.test.t3,root.test.m1,root.test.m2,root.test.m3)| |
| +-----------------------------+---------------------------------------------------------------------------------------+ |
| |2021-07-01T12:00:01.000+08:00| 0.875| |
| +-----------------------------+---------------------------------------------------------------------------------------+ |
| ``` |
| |
| |
| |
| ### 趋势计算函数 |
| |
| 目前 IoTDB 支持如下趋势计算函数: |
| |
| | 函数名 | 输入序列类型 | 输出序列类型 | 功能描述 | |
| | ----------------------- | ----------------------------------------------- | ------------------------ | ------------------------------------------------------------ | |
| | TIME_DIFFERENCE | INT32 / INT64 / FLOAT / DOUBLE / BOOLEAN / TEXT | INT64 | 统计序列中某数据点的时间戳与前一数据点时间戳的差。范围内第一个数据点没有对应的结果输出。 | |
| | DIFFERENCE | INT32 / INT64 / FLOAT / DOUBLE | 与输入序列的实际类型一致 | 统计序列中某数据点的值与前一数据点的值的差。范围内第一个数据点没有对应的结果输出。 | |
| | NON_NEGATIVE_DIFFERENCE | INT32 / INT64 / FLOAT / DOUBLE | 与输入序列的实际类型一致 | 统计序列中某数据点的值与前一数据点的值的差的绝对值。范围内第一个数据点没有对应的结果输出。 | |
| | DERIVATIVE | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | 统计序列中某数据点相对于前一数据点的变化率,数量上等同于 DIFFERENCE / TIME_DIFFERENCE。范围内第一个数据点没有对应的结果输出。 | |
| | NON_NEGATIVE_DERIVATIVE | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | 统计序列中某数据点相对于前一数据点的变化率的绝对值,数量上等同于 NON_NEGATIVE_DIFFERENCE / TIME_DIFFERENCE。范围内第一个数据点没有对应的结果输出。 | |
| |
| 例如: |
| |
| ``` sql |
| select s1, time_difference(s1), difference(s1), non_negative_difference(s1), derivative(s1), non_negative_derivative(s1) from root.sg1.d1 limit 5 offset 1000; |
| ``` |
| |
| 结果: |
| |
| ``` |
| +-----------------------------+-------------------+-------------------------------+--------------------------+---------------------------------------+--------------------------+---------------------------------------+ |
| | Time| root.sg1.d1.s1|time_difference(root.sg1.d1.s1)|difference(root.sg1.d1.s1)|non_negative_difference(root.sg1.d1.s1)|derivative(root.sg1.d1.s1)|non_negative_derivative(root.sg1.d1.s1)| |
| +-----------------------------+-------------------+-------------------------------+--------------------------+---------------------------------------+--------------------------+---------------------------------------+ |
| |2020-12-10T17:11:49.037+08:00|7360723084922759782| 1| -8431715764844238876| 8431715764844238876| -8.4317157648442388E18| 8.4317157648442388E18| |
| |2020-12-10T17:11:49.038+08:00|4377791063319964531| 1| -2982932021602795251| 2982932021602795251| -2.982932021602795E18| 2.982932021602795E18| |
| |2020-12-10T17:11:49.039+08:00|7972485567734642915| 1| 3594694504414678384| 3594694504414678384| 3.5946945044146785E18| 3.5946945044146785E18| |
| |2020-12-10T17:11:49.040+08:00|2508858212791964081| 1| -5463627354942678834| 5463627354942678834| -5.463627354942679E18| 5.463627354942679E18| |
| |2020-12-10T17:11:49.041+08:00|2817297431185141819| 1| 308439218393177738| 308439218393177738| 3.0843921839317773E17| 3.0843921839317773E17| |
| +-----------------------------+-------------------+-------------------------------+--------------------------+---------------------------------------+--------------------------+---------------------------------------+ |
| Total line number = 5 |
| It costs 0.014s |
| ``` |
| |
| | 函数名 | 输入序列类型 | 参数 | 输出序列类型 | 功能描述 | |
| |------|--------------------------------|------------------------------------------------------------------------------------------------------------------------|--------|------------------------------------------------| |
| | DIFF | INT32 / INT64 / FLOAT / DOUBLE | `ignoreNull`:可选,默认为true;为true时,前一个数据点值为null时,忽略该数据点继续向前找到第一个出现的不为null的值;为false时,如果前一个数据点为null,则不忽略,使用null进行相减,结果也为null | DOUBLE | 统计序列中某数据点的值与前一数据点的值的差。第一个数据点没有对应的结果输出,输出值为null | |
| |
| #### 使用示例 |
| |
| ##### 原始数据 |
| |
| ``` |
| +-----------------------------+------------+------------+ |
| | Time|root.test.s1|root.test.s2| |
| +-----------------------------+------------+------------+ |
| |1970-01-01T08:00:00.001+08:00| 1| 1.0| |
| |1970-01-01T08:00:00.002+08:00| 2| null| |
| |1970-01-01T08:00:00.003+08:00| null| 3.0| |
| |1970-01-01T08:00:00.004+08:00| 4| null| |
| |1970-01-01T08:00:00.005+08:00| 5| 5.0| |
| |1970-01-01T08:00:00.006+08:00| null| 6.0| |
| +-----------------------------+------------+------------+ |
| ``` |
| |
| ##### 不使用ignoreNull参数(忽略null) |
| |
| SQL: |
| ```sql |
| SELECT DIFF(s1), DIFF(s2) from root.test; |
| ``` |
| |
| 输出: |
| ``` |
| +-----------------------------+------------------+------------------+ |
| | Time|DIFF(root.test.s1)|DIFF(root.test.s2)| |
| +-----------------------------+------------------+------------------+ |
| |1970-01-01T08:00:00.001+08:00| null| null| |
| |1970-01-01T08:00:00.002+08:00| 1.0| null| |
| |1970-01-01T08:00:00.003+08:00| null| 2.0| |
| |1970-01-01T08:00:00.004+08:00| 2.0| null| |
| |1970-01-01T08:00:00.005+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.006+08:00| null| 1.0| |
| +-----------------------------+------------------+------------------+ |
| ``` |
| |
| ##### 使用ignoreNull参数 |
| |
| SQL: |
| ```sql |
| SELECT DIFF(s1, 'ignoreNull'='false'), DIFF(s2, 'ignoreNull'='false') from root.test; |
| ``` |
| |
| 输出: |
| ``` |
| +-----------------------------+----------------------------------------+----------------------------------------+ |
| | Time|DIFF(root.test.s1, "ignoreNull"="false")|DIFF(root.test.s2, "ignoreNull"="false")| |
| +-----------------------------+----------------------------------------+----------------------------------------+ |
| |1970-01-01T08:00:00.001+08:00| null| null| |
| |1970-01-01T08:00:00.002+08:00| 1.0| null| |
| |1970-01-01T08:00:00.003+08:00| null| null| |
| |1970-01-01T08:00:00.004+08:00| null| null| |
| |1970-01-01T08:00:00.005+08:00| 1.0| null| |
| |1970-01-01T08:00:00.006+08:00| null| 1.0| |
| +-----------------------------+----------------------------------------+----------------------------------------+ |
| ``` |
| |
| |
| ### 采样函数 |
| |
| #### 等数量分桶降采样函数 |
| |
| 本函数对输入序列进行等数量分桶采样,即根据用户给定的降采样比例和降采样方法将输入序列按固定点数等分为若干桶。在每个桶内通过给定的采样方法进行采样。 |
| |
| ##### 等数量分桶随机采样 |
| |
| 对等数量分桶后,桶内进行随机采样。 |
| |
| | 函数名 | 可接收的输入序列类型 | 必要的属性参数 | 输出序列类型 | 功能类型 | |
| |----------|--------------------------------|---------------------------------------|------------|--------------------------------------------------| |
| | EQUAL_SIZE_BUCKET_RANDOM_SAMPLE | INT32 / INT64 / FLOAT / DOUBLE | 降采样比例 `proportion`,取值范围为`(0, 1]`,默认为`0.1` | INT32 / INT64 / FLOAT / DOUBLE | 返回符合采样比例的等分桶随机采样 | |
| |
| ###### 使用示例 |
| |
| 输入序列:`root.ln.wf01.wt01.temperature`从`0.0-99.0`共`100`条数据。 |
| |
| ``` |
| IoTDB> select temperature from root.ln.wf01.wt01; |
| +-----------------------------+-----------------------------+ |
| | Time|root.ln.wf01.wt01.temperature| |
| +-----------------------------+-----------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.0| |
| |1970-01-01T08:00:00.001+08:00| 1.0| |
| |1970-01-01T08:00:00.002+08:00| 2.0| |
| |1970-01-01T08:00:00.003+08:00| 3.0| |
| |1970-01-01T08:00:00.004+08:00| 4.0| |
| |1970-01-01T08:00:00.005+08:00| 5.0| |
| |1970-01-01T08:00:00.006+08:00| 6.0| |
| |1970-01-01T08:00:00.007+08:00| 7.0| |
| |1970-01-01T08:00:00.008+08:00| 8.0| |
| |1970-01-01T08:00:00.009+08:00| 9.0| |
| |1970-01-01T08:00:00.010+08:00| 10.0| |
| |1970-01-01T08:00:00.011+08:00| 11.0| |
| |1970-01-01T08:00:00.012+08:00| 12.0| |
| |.............................|.............................| |
| |1970-01-01T08:00:00.089+08:00| 89.0| |
| |1970-01-01T08:00:00.090+08:00| 90.0| |
| |1970-01-01T08:00:00.091+08:00| 91.0| |
| |1970-01-01T08:00:00.092+08:00| 92.0| |
| |1970-01-01T08:00:00.093+08:00| 93.0| |
| |1970-01-01T08:00:00.094+08:00| 94.0| |
| |1970-01-01T08:00:00.095+08:00| 95.0| |
| |1970-01-01T08:00:00.096+08:00| 96.0| |
| |1970-01-01T08:00:00.097+08:00| 97.0| |
| |1970-01-01T08:00:00.098+08:00| 98.0| |
| |1970-01-01T08:00:00.099+08:00| 99.0| |
| +-----------------------------+-----------------------------+ |
| ``` |
| sql: |
| ```sql |
| select equal_size_bucket_random_sample(temperature,'proportion'='0.1') as random_sample from root.ln.wf01.wt01; |
| ``` |
| 结果: |
| ``` |
| +-----------------------------+-------------+ |
| | Time|random_sample| |
| +-----------------------------+-------------+ |
| |1970-01-01T08:00:00.007+08:00| 7.0| |
| |1970-01-01T08:00:00.014+08:00| 14.0| |
| |1970-01-01T08:00:00.020+08:00| 20.0| |
| |1970-01-01T08:00:00.035+08:00| 35.0| |
| |1970-01-01T08:00:00.047+08:00| 47.0| |
| |1970-01-01T08:00:00.059+08:00| 59.0| |
| |1970-01-01T08:00:00.063+08:00| 63.0| |
| |1970-01-01T08:00:00.079+08:00| 79.0| |
| |1970-01-01T08:00:00.086+08:00| 86.0| |
| |1970-01-01T08:00:00.096+08:00| 96.0| |
| +-----------------------------+-------------+ |
| Total line number = 10 |
| It costs 0.024s |
| ``` |
| |
| ##### 等数量分桶聚合采样 |
| |
| 采用聚合采样法对输入序列进行采样,用户需要另外提供一个聚合函数参数即 |
| - `type`:聚合类型,取值为`avg`或`max`或`min`或`sum`或`extreme`或`variance`。在缺省情况下,采用`avg`。其中`extreme`表示等分桶中,绝对值最大的值。`variance`表示采样等分桶中的方差。 |
| |
| 每个桶采样输出的时间戳为这个桶第一个点的时间戳 |
| |
| |
| | 函数名 | 可接收的输入序列类型 | 必要的属性参数 | 输出序列类型 | 功能类型 | |
| |----------|--------------------------------|---------------------------------------|------------|--------------------------------------------------| |
| | EQUAL_SIZE_BUCKET_AGG_SAMPLE | INT32 / INT64 / FLOAT / DOUBLE | `proportion`取值范围为`(0, 1]`,默认为`0.1`<br>`type`:取值类型有`avg`, `max`, `min`, `sum`, `extreme`, `variance`, 默认为`avg` | INT32 / INT64 / FLOAT / DOUBLE | 返回符合采样比例的等分桶聚合采样 | |
| |
| ###### 使用示例 |
| |
| 输入序列:`root.ln.wf01.wt01.temperature`从`0.0-99.0`共`100`条有序数据,同等分桶随机采样的测试数据。 |
| |
| sql: |
| ```sql |
| select equal_size_bucket_agg_sample(temperature, 'type'='avg','proportion'='0.1') as agg_avg, equal_size_bucket_agg_sample(temperature, 'type'='max','proportion'='0.1') as agg_max, equal_size_bucket_agg_sample(temperature,'type'='min','proportion'='0.1') as agg_min, equal_size_bucket_agg_sample(temperature, 'type'='sum','proportion'='0.1') as agg_sum, equal_size_bucket_agg_sample(temperature, 'type'='extreme','proportion'='0.1') as agg_extreme, equal_size_bucket_agg_sample(temperature, 'type'='variance','proportion'='0.1') as agg_variance from root.ln.wf01.wt01; |
| ``` |
| 结果: |
| ``` |
| +-----------------------------+-----------------+-------+-------+-------+-----------+------------+ |
| | Time| agg_avg|agg_max|agg_min|agg_sum|agg_extreme|agg_variance| |
| +-----------------------------+-----------------+-------+-------+-------+-----------+------------+ |
| |1970-01-01T08:00:00.000+08:00| 4.5| 9.0| 0.0| 45.0| 9.0| 8.25| |
| |1970-01-01T08:00:00.010+08:00| 14.5| 19.0| 10.0| 145.0| 19.0| 8.25| |
| |1970-01-01T08:00:00.020+08:00| 24.5| 29.0| 20.0| 245.0| 29.0| 8.25| |
| |1970-01-01T08:00:00.030+08:00| 34.5| 39.0| 30.0| 345.0| 39.0| 8.25| |
| |1970-01-01T08:00:00.040+08:00| 44.5| 49.0| 40.0| 445.0| 49.0| 8.25| |
| |1970-01-01T08:00:00.050+08:00| 54.5| 59.0| 50.0| 545.0| 59.0| 8.25| |
| |1970-01-01T08:00:00.060+08:00| 64.5| 69.0| 60.0| 645.0| 69.0| 8.25| |
| |1970-01-01T08:00:00.070+08:00|74.50000000000001| 79.0| 70.0| 745.0| 79.0| 8.25| |
| |1970-01-01T08:00:00.080+08:00| 84.5| 89.0| 80.0| 845.0| 89.0| 8.25| |
| |1970-01-01T08:00:00.090+08:00| 94.5| 99.0| 90.0| 945.0| 99.0| 8.25| |
| +-----------------------------+-----------------+-------+-------+-------+-----------+------------+ |
| Total line number = 10 |
| It costs 0.044s |
| ``` |
| |
| ##### 等数量分桶 M4 采样 |
| |
| 采用M4采样法对输入序列进行采样。即对于每个桶采样首、尾、最小和最大值。 |
| |
| | 函数名 | 可接收的输入序列类型 | 必要的属性参数 | 输出序列类型 | 功能类型 | |
| |----------|--------------------------------|---------------------------------------|------------|--------------------------------------------------| |
| | EQUAL_SIZE_BUCKET_M4_SAMPLE | INT32 / INT64 / FLOAT / DOUBLE | `proportion`取值范围为`(0, 1]`,默认为`0.1`| INT32 / INT64 / FLOAT / DOUBLE | 返回符合采样比例的等分桶M4采样 | |
| |
| ###### 使用示例 |
| |
| 输入序列:`root.ln.wf01.wt01.temperature`从`0.0-99.0`共`100`条有序数据,同等分桶随机采样的测试数据。 |
| |
| sql: |
| ```sql |
| select equal_size_bucket_m4_sample(temperature, 'proportion'='0.1') as M4_sample from root.ln.wf01.wt01; |
| ``` |
| 结果: |
| ``` |
| +-----------------------------+---------+ |
| | Time|M4_sample| |
| +-----------------------------+---------+ |
| |1970-01-01T08:00:00.000+08:00| 0.0| |
| |1970-01-01T08:00:00.001+08:00| 1.0| |
| |1970-01-01T08:00:00.038+08:00| 38.0| |
| |1970-01-01T08:00:00.039+08:00| 39.0| |
| |1970-01-01T08:00:00.040+08:00| 40.0| |
| |1970-01-01T08:00:00.041+08:00| 41.0| |
| |1970-01-01T08:00:00.078+08:00| 78.0| |
| |1970-01-01T08:00:00.079+08:00| 79.0| |
| |1970-01-01T08:00:00.080+08:00| 80.0| |
| |1970-01-01T08:00:00.081+08:00| 81.0| |
| |1970-01-01T08:00:00.098+08:00| 98.0| |
| |1970-01-01T08:00:00.099+08:00| 99.0| |
| +-----------------------------+---------+ |
| Total line number = 12 |
| It costs 0.065s |
| ``` |
| |
| ##### 等数量分桶离群值采样 |
| |
| 本函数对输入序列进行等数量分桶离群值采样,即根据用户给定的降采样比例和桶内采样个数将输入序列按固定点数等分为若干桶,在每个桶内通过给定的离群值采样方法进行采样。 |
| |
| | 函数名 | 可接收的输入序列类型 | 必要的属性参数 | 输出序列类型 | 功能类型 | |
| |----------|--------------------------------|---------------------------------------|------------|--------------------------------------------------| |
| | EQUAL_SIZE_BUCKET_OUTLIER_SAMPLE | INT32 / INT64 / FLOAT / DOUBLE | `proportion`取值范围为`(0, 1]`,默认为`0.1`<br>`type`取值为`avg`或`stendis`或`cos`或`prenextdis`,默认为`avg`<br>`number`取值应大于0,默认`3`| INT32 / INT64 / FLOAT / DOUBLE | 返回符合采样比例和桶内采样个数的等分桶离群值采样 | |
| |
| 参数说明 |
| - `proportion`: 采样比例 |
| - `number`: 每个桶内的采样个数,默认`3` |
| - `type`: 离群值采样方法,取值为 |
| - `avg`: 取桶内数据点的平均值,并根据采样比例,找到距离均值最远的`top number`个 |
| - `stendis`: 取桶内每一个数据点距离桶的首末数据点连成直线的垂直距离,并根据采样比例,找到距离最大的`top number`个 |
| - `cos`: 设桶内一个数据点为b,b左边的数据点为a,b右边的数据点为c,则取ab与bc向量的夹角的余弦值,值越小,说明形成的角度越大,越可能是异常值。找到cos值最小的`top number`个 |
| - `prenextdis`: 设桶内一个数据点为b,b左边的数据点为a,b右边的数据点为c,则取ab与bc的长度之和作为衡量标准,和越大越可能是异常值,找到最大的`top number`个 |
| |
| ###### 使用示例 |
| |
| 测试数据:`root.ln.wf01.wt01.temperature`从`0.0-99.0`共`100`条数据,其中为了加入离群值,我们使得个位数为5的值自增100。 |
| ``` |
| IoTDB> select temperature from root.ln.wf01.wt01; |
| +-----------------------------+-----------------------------+ |
| | Time|root.ln.wf01.wt01.temperature| |
| +-----------------------------+-----------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.0| |
| |1970-01-01T08:00:00.001+08:00| 1.0| |
| |1970-01-01T08:00:00.002+08:00| 2.0| |
| |1970-01-01T08:00:00.003+08:00| 3.0| |
| |1970-01-01T08:00:00.004+08:00| 4.0| |
| |1970-01-01T08:00:00.005+08:00| 105.0| |
| |1970-01-01T08:00:00.006+08:00| 6.0| |
| |1970-01-01T08:00:00.007+08:00| 7.0| |
| |1970-01-01T08:00:00.008+08:00| 8.0| |
| |1970-01-01T08:00:00.009+08:00| 9.0| |
| |1970-01-01T08:00:00.010+08:00| 10.0| |
| |1970-01-01T08:00:00.011+08:00| 11.0| |
| |1970-01-01T08:00:00.012+08:00| 12.0| |
| |1970-01-01T08:00:00.013+08:00| 13.0| |
| |1970-01-01T08:00:00.014+08:00| 14.0| |
| |1970-01-01T08:00:00.015+08:00| 115.0| |
| |1970-01-01T08:00:00.016+08:00| 16.0| |
| |.............................|.............................| |
| |1970-01-01T08:00:00.092+08:00| 92.0| |
| |1970-01-01T08:00:00.093+08:00| 93.0| |
| |1970-01-01T08:00:00.094+08:00| 94.0| |
| |1970-01-01T08:00:00.095+08:00| 195.0| |
| |1970-01-01T08:00:00.096+08:00| 96.0| |
| |1970-01-01T08:00:00.097+08:00| 97.0| |
| |1970-01-01T08:00:00.098+08:00| 98.0| |
| |1970-01-01T08:00:00.099+08:00| 99.0| |
| +-----------------------------+-----------------------------+ |
| ``` |
| sql: |
| ```sql |
| select equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='avg', 'number'='2') as outlier_avg_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='stendis', 'number'='2') as outlier_stendis_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='cos', 'number'='2') as outlier_cos_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='prenextdis', 'number'='2') as outlier_prenextdis_sample from root.ln.wf01.wt01; |
| ``` |
| 结果: |
| ``` |
| +-----------------------------+------------------+----------------------+------------------+-------------------------+ |
| | Time|outlier_avg_sample|outlier_stendis_sample|outlier_cos_sample|outlier_prenextdis_sample| |
| +-----------------------------+------------------+----------------------+------------------+-------------------------+ |
| |1970-01-01T08:00:00.005+08:00| 105.0| 105.0| 105.0| 105.0| |
| |1970-01-01T08:00:00.015+08:00| 115.0| 115.0| 115.0| 115.0| |
| |1970-01-01T08:00:00.025+08:00| 125.0| 125.0| 125.0| 125.0| |
| |1970-01-01T08:00:00.035+08:00| 135.0| 135.0| 135.0| 135.0| |
| |1970-01-01T08:00:00.045+08:00| 145.0| 145.0| 145.0| 145.0| |
| |1970-01-01T08:00:00.055+08:00| 155.0| 155.0| 155.0| 155.0| |
| |1970-01-01T08:00:00.065+08:00| 165.0| 165.0| 165.0| 165.0| |
| |1970-01-01T08:00:00.075+08:00| 175.0| 175.0| 175.0| 175.0| |
| |1970-01-01T08:00:00.085+08:00| 185.0| 185.0| 185.0| 185.0| |
| |1970-01-01T08:00:00.095+08:00| 195.0| 195.0| 195.0| 195.0| |
| +-----------------------------+------------------+----------------------+------------------+-------------------------+ |
| Total line number = 10 |
| It costs 0.041s |
| ``` |
| |
| #### M4函数 |
| |
| ##### 函数简介 |
| |
| M4用于在窗口内采样第一个点(`first`)、最后一个点(`last`)、最小值点(`bottom`)、最大值点(`top`): |
| |
| - 第一个点是拥有这个窗口内最小时间戳的点; |
| - 最后一个点是拥有这个窗口内最大时间戳的点; |
| - 最小值点是拥有这个窗口内最小值的点(如果有多个这样的点,M4只返回其中一个); |
| - 最大值点是拥有这个窗口内最大值的点(如果有多个这样的点,M4只返回其中一个)。 |
| |
| <img src="https://alioss.timecho.com/docs/img/github/198178733-a0919d17-0663-4672-9c4f-1efad6f463c2.png" alt="image" style="zoom:50%;" /> |
| |
| | 函数名 | 可接收的输入序列类型 | 属性参数 | 输出序列类型 | 功能类型 | |
| | ------ | ------------------------------ | ------------------------------------------------------------ | ------------------------------ | ------------------------------------------------------------ | |
| | M4 | INT32 / INT64 / FLOAT / DOUBLE | 包含固定点数的窗口和滑动时间窗口使用不同的属性参数。包含固定点数的窗口使用属性`windowSize`和`slidingStep`。滑动时间窗口使用属性`timeInterval`、`slidingStep`、`displayWindowBegin`和`displayWindowEnd`。更多细节见下文。 | INT32 / INT64 / FLOAT / DOUBLE | 返回每个窗口内的第一个点(`first`)、最后一个点(`last`)、最小值点(`bottom`)、最大值点(`top`)。在一个窗口内的聚合点输出之前,M4会将它们按照时间戳递增排序并且去重。 | |
| |
| ##### 属性参数 |
| |
| **(1) 包含固定点数的窗口(SlidingSizeWindowAccessStrategy)使用的属性参数:** |
| |
| + `windowSize`: 一个窗口内的点数。Int数据类型。必需的属性参数。 |
| + `slidingStep`: 按照设定的点数来滑动窗口。Int数据类型。可选的属性参数;如果没有设置,默认取值和`windowSize`一样。 |
| |
| <img src="https://alioss.timecho.com/docs/img/github/198181449-00d563c8-7bce-4ecd-a031-ec120ca42c3f.png" alt="image" style="zoom: 50%;" /> |
| |
| **(2) 滑动时间窗口(SlidingTimeWindowAccessStrategy)使用的属性参数:** |
| |
| + `timeInterval`: 一个窗口的时间长度。Long数据类型。必需的属性参数。 |
| + `slidingStep`: 按照设定的时长来滑动窗口。Long数据类型。可选的属性参数;如果没有设置,默认取值和`timeInterval`一样。 |
| + `displayWindowBegin`: 窗口滑动的起始时间戳位置(包含在内)。Long数据类型。可选的属性参数;如果没有设置,默认取值为Long.MIN_VALUE,意为使用输入的时间序列的第一个点的时间戳作为窗口滑动的起始时间戳位置。 |
| + `displayWindowEnd`: 结束时间限制(不包含在内;本质上和`WHERE time < displayWindowEnd`起的效果是一样的)。Long数据类型。可选的属性参数;如果没有设置,默认取值为Long.MAX_VALUE,意为除了输入的时间序列自身数据读取完毕之外没有增加额外的结束时间过滤条件限制。 |
| |
| <img src="https://alioss.timecho.com/docs/img/github/198183015-93b56644-3330-4acf-ae9e-d718a02b5f4c.png" alt="groupBy window" style="zoom: 67%;" /> |
| |
| ##### 使用示例 |
| |
| 输入的时间序列: |
| |
| ```sql |
| +-----------------------------+------------------+ |
| | Time|root.vehicle.d1.s1| |
| +-----------------------------+------------------+ |
| |1970-01-01T08:00:00.001+08:00| 5.0| |
| |1970-01-01T08:00:00.002+08:00| 15.0| |
| |1970-01-01T08:00:00.005+08:00| 10.0| |
| |1970-01-01T08:00:00.008+08:00| 8.0| |
| |1970-01-01T08:00:00.010+08:00| 30.0| |
| |1970-01-01T08:00:00.020+08:00| 20.0| |
| |1970-01-01T08:00:00.025+08:00| 8.0| |
| |1970-01-01T08:00:00.027+08:00| 20.0| |
| |1970-01-01T08:00:00.030+08:00| 40.0| |
| |1970-01-01T08:00:00.033+08:00| 9.0| |
| |1970-01-01T08:00:00.035+08:00| 10.0| |
| |1970-01-01T08:00:00.040+08:00| 20.0| |
| |1970-01-01T08:00:00.045+08:00| 30.0| |
| |1970-01-01T08:00:00.052+08:00| 8.0| |
| |1970-01-01T08:00:00.054+08:00| 18.0| |
| +-----------------------------+------------------+ |
| ``` |
| |
| 查询语句1: |
| |
| ```sql |
| select M4(s1,'timeInterval'='25','displayWindowBegin'='0','displayWindowEnd'='100') from root.vehicle.d1 |
| ``` |
| |
| 输出结果1: |
| |
| ```sql |
| +-----------------------------+-----------------------------------------------------------------------------------------------+ |
| | Time|M4(root.vehicle.d1.s1, "timeInterval"="25", "displayWindowBegin"="0", "displayWindowEnd"="100")| |
| +-----------------------------+-----------------------------------------------------------------------------------------------+ |
| |1970-01-01T08:00:00.001+08:00| 5.0| |
| |1970-01-01T08:00:00.010+08:00| 30.0| |
| |1970-01-01T08:00:00.020+08:00| 20.0| |
| |1970-01-01T08:00:00.025+08:00| 8.0| |
| |1970-01-01T08:00:00.030+08:00| 40.0| |
| |1970-01-01T08:00:00.045+08:00| 30.0| |
| |1970-01-01T08:00:00.052+08:00| 8.0| |
| |1970-01-01T08:00:00.054+08:00| 18.0| |
| +-----------------------------+-----------------------------------------------------------------------------------------------+ |
| Total line number = 8 |
| ``` |
| |
| 查询语句2: |
| |
| ```sql |
| select M4(s1,'windowSize'='10') from root.vehicle.d1 |
| ``` |
| |
| 输出结果2: |
| |
| ```sql |
| +-----------------------------+-----------------------------------------+ |
| | Time|M4(root.vehicle.d1.s1, "windowSize"="10")| |
| +-----------------------------+-----------------------------------------+ |
| |1970-01-01T08:00:00.001+08:00| 5.0| |
| |1970-01-01T08:00:00.030+08:00| 40.0| |
| |1970-01-01T08:00:00.033+08:00| 9.0| |
| |1970-01-01T08:00:00.035+08:00| 10.0| |
| |1970-01-01T08:00:00.045+08:00| 30.0| |
| |1970-01-01T08:00:00.052+08:00| 8.0| |
| |1970-01-01T08:00:00.054+08:00| 18.0| |
| +-----------------------------+-----------------------------------------+ |
| Total line number = 7 |
| ``` |
| |
| ##### 推荐的使用场景 |
| |
| **(1) 使用场景:保留极端点的降采样** |
| |
| 由于M4为每个窗口聚合其第一个点(`first`)、最后一个点(`last`)、最小值点(`bottom`)、最大值点(`top`),因此M4通常保留了极值点,因此比其他下采样方法(如分段聚合近似 (PAA))能更好地保留模式。如果你想对时间序列进行下采样并且希望保留极值点,你可以试试 M4。 |
| |
| **(2) 使用场景:基于M4降采样的大规模时间序列的零误差双色折线图可视化** |
| |
| 参考论文["M4: A Visualization-Oriented Time Series Data Aggregation"](http://www.vldb.org/pvldb/vol7/p797-jugel.pdf),作为大规模时间序列可视化的降采样方法,M4可以做到双色折线图的零变形。 |
| |
| 假设屏幕画布的像素宽乘高是`w*h`,假设时间序列要可视化的时间范围是`[tqs,tqe)`,并且(tqe-tqs)是w的整数倍,那么落在第i个时间跨度`Ii=[tqs+(tqe-tqs)/w*(i-1),tqs+(tqe-tqs)/w*i)` 内的点将会被画在第i个像素列中,i=1,2,...,w。于是从可视化驱动的角度出发,使用查询语句:`"select M4(s1,'timeInterval'='(tqe-tqs)/w','displayWindowBegin'='tqs','displayWindowEnd'='tqe') from root.vehicle.d1"`,来采集每个时间跨度内的第一个点(`first`)、最后一个点(`last`)、最小值点(`bottom`)、最大值点(`top`)。降采样时间序列的结果点数不会超过`4*w`个,与此同时,使用这些聚合点画出来的二色折线图与使用原始数据画出来的在像素级别上是完全一致的。 |
| |
| 为了免除参数值硬编码的麻烦,当Grafana用于可视化时,我们推荐使用Grafana的[模板变量](https://grafana.com/docs/grafana/latest/dashboards/variables/add-template-variables/#global-variables)`$ __interval_ms`,如下所示: |
| |
| ```sql |
| select M4(s1,'timeInterval'='$__interval_ms') from root.sg1.d1 |
| ``` |
| |
| 其中`timeInterval`自动设置为`(tqe-tqs)/w`。请注意,这里的时间精度假定为毫秒。 |
| |
| ##### 和其它函数的功能比较 |
| |
| | SQL | 是否支持M4聚合 | 滑动窗口类型 | 示例 | 相关文档 | |
| | ------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | |
| | 1. 带有Group By子句的内置聚合函数 | 不支持,缺少`BOTTOM_TIME`和`TOP_TIME`,即缺少最小值点和最大值点的时间戳。 | Time Window | `select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d)` | https://iotdb.apache.org/UserGuide/Master/Query-Data/Aggregate-Query.html#built-in-aggregate-functions <br />https://iotdb.apache.org/UserGuide/Master/Query-Data/Aggregate-Query.html#downsampling-aggregate-query | |
| | 2. EQUAL_SIZE_BUCKET_M4_SAMPLE (内置UDF) | 支持* | Size Window. `windowSize = 4*(int)(1/proportion)` | `select equal_size_bucket_m4_sample(temperature, 'proportion'='0.1') as M4_sample from root.ln.wf01.wt01` | https://iotdb.apache.org/UserGuide/Master/Query-Data/Select-Expression.html#time-series-generating-functions | |
| | **3. M4 (内置UDF)** | 支持* | Size Window, Time Window | (1) Size Window: `select M4(s1,'windowSize'='10') from root.vehicle.d1` <br />(2) Time Window: `select M4(s1,'timeInterval'='25','displayWindowBegin'='0','displayWindowEnd'='100') from root.vehicle.d1` | 本文档 | |
| | 4. 扩展带有Group By子句的内置聚合函数来支持M4聚合 | 未实施 | 未实施 | 未实施 | 未实施 | |
| |
| 进一步比较`EQUAL_SIZE_BUCKET_M4_SAMPLE`和`M4`: |
| |
| **(1) 不同的M4聚合函数定义:** |
| |
| 在每个窗口内,`EQUAL_SIZE_BUCKET_M4_SAMPLE`从排除了第一个点和最后一个点之后剩余的点中提取最小值点和最大值点。 |
| |
| 而`M4`则是从窗口内所有点中(包括第一个点和最后一个点)提取最小值点和最大值点,这个定义与元数据中保存的`max_value`和`min_value`的语义更加一致。 |
| |
| 值得注意的是,在一个窗口内的聚合点输出之前,`EQUAL_SIZE_BUCKET_M4_SAMPLE`和`M4`都会将它们按照时间戳递增排序并且去重。 |
| |
| **(2) 不同的滑动窗口:** |
| |
| `EQUAL_SIZE_BUCKET_M4_SAMPLE`使用SlidingSizeWindowAccessStrategy,并且通过采样比例(`proportion`)来间接控制窗口点数(`windowSize`),转换公式是`windowSize = 4*(int)(1/proportion)`。 |
| |
| `M4`支持两种滑动窗口:SlidingSizeWindowAccessStrategy和SlidingTimeWindowAccessStrategy,并且`M4`通过相应的参数直接控制窗口的点数或者时长。 |
| |
| |
| ### 选择函数 |
| |
| 目前 IoTDB 支持如下选择函数: |
| |
| | 函数名 | 输入序列类型 | 必要的属性参数 | 输出序列类型 | 功能描述 | |
| | -------- | ------------------------------------- | ------------------------------------------------- | ------------------------ | ------------------------------------------------------------ | |
| | TOP_K | INT32 / INT64 / FLOAT / DOUBLE / TEXT | `k`: 最多选择的数据点数,必须大于 0 小于等于 1000 | 与输入序列的实际类型一致 | 返回某时间序列中值最大的`k`个数据点。若多于`k`个数据点的值并列最大,则返回时间戳最小的数据点。 | |
| | BOTTOM_K | INT32 / INT64 / FLOAT / DOUBLE / TEXT | `k`: 最多选择的数据点数,必须大于 0 小于等于 1000 | 与输入序列的实际类型一致 | 返回某时间序列中值最小的`k`个数据点。若多于`k`个数据点的值并列最小,则返回时间戳最小的数据点。 | |
| |
| 例如: |
| |
| ``` sql |
| select s1, top_k(s1, 'k'='2'), bottom_k(s1, 'k'='2') from root.sg1.d2 where time > 2020-12-10T20:36:15.530+08:00; |
| ``` |
| |
| 结果: |
| |
| ``` |
| +-----------------------------+--------------------+------------------------------+---------------------------------+ |
| | Time| root.sg1.d2.s1|top_k(root.sg1.d2.s1, "k"="2")|bottom_k(root.sg1.d2.s1, "k"="2")| |
| +-----------------------------+--------------------+------------------------------+---------------------------------+ |
| |2020-12-10T20:36:15.531+08:00| 1531604122307244742| 1531604122307244742| null| |
| |2020-12-10T20:36:15.532+08:00|-7426070874923281101| null| null| |
| |2020-12-10T20:36:15.533+08:00|-7162825364312197604| -7162825364312197604| null| |
| |2020-12-10T20:36:15.534+08:00|-8581625725655917595| null| -8581625725655917595| |
| |2020-12-10T20:36:15.535+08:00|-7667364751255535391| null| -7667364751255535391| |
| +-----------------------------+--------------------+------------------------------+---------------------------------+ |
| Total line number = 5 |
| It costs 0.006s |
| ``` |
| |
| |
| ### 数据画像 |
| |
| #### ACF |
| |
| ##### 函数简介 |
| |
| 本函数用于计算时间序列的自相关函数值,即序列与自身之间的互相关函数,详情参见[XCorr](./Data-Matching.md#XCorr)函数文档。 |
| |
| **函数名:** ACF |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE。序列中共包含$2N-1$个数据点,每个值的具体含义参见[XCorr](./Data-Matching.md#XCorr)函数文档。 |
| |
| **提示:** |
| |
| + 序列中的`NaN`值会被忽略,在计算中表现为0。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:01.000+08:00| 1| |
| |2020-01-01T00:00:02.000+08:00| NaN| |
| |2020-01-01T00:00:03.000+08:00| 3| |
| |2020-01-01T00:00:04.000+08:00| NaN| |
| |2020-01-01T00:00:05.000+08:00| 5| |
| +-----------------------------+---------------+ |
| ``` |
| |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select acf(s1) from root.test.d1 where time <= 2020-01-01 00:00:05 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------+ |
| | Time|acf(root.test.d1.s1)| |
| +-----------------------------+--------------------+ |
| |1970-01-01T08:00:00.001+08:00| 1.0| |
| |1970-01-01T08:00:00.002+08:00| 0.0| |
| |1970-01-01T08:00:00.003+08:00| 3.6| |
| |1970-01-01T08:00:00.004+08:00| 0.0| |
| |1970-01-01T08:00:00.005+08:00| 7.0| |
| |1970-01-01T08:00:00.006+08:00| 0.0| |
| |1970-01-01T08:00:00.007+08:00| 3.6| |
| |1970-01-01T08:00:00.008+08:00| 0.0| |
| |1970-01-01T08:00:00.009+08:00| 1.0| |
| +-----------------------------+--------------------+ |
| ``` |
| |
| #### Distinct |
| |
| ##### 函数简介 |
| |
| 本函数可以返回输入序列中出现的所有不同的元素。 |
| |
| **函数名:** DISTINCT |
| |
| **输入序列:** 仅支持单个输入序列,类型可以是任意的 |
| |
| **输出序列:** 输出单个序列,类型与输入相同。 |
| |
| **提示:** |
| |
| + 输出序列的时间戳是无意义的。输出顺序是任意的。 |
| + 缺失值和空值将被忽略,但`NaN`不会被忽略。 |
| + 字符串区分大小写 |
| |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d2.s2| |
| +-----------------------------+---------------+ |
| |2020-01-01T08:00:00.001+08:00| Hello| |
| |2020-01-01T08:00:00.002+08:00| hello| |
| |2020-01-01T08:00:00.003+08:00| Hello| |
| |2020-01-01T08:00:00.004+08:00| World| |
| |2020-01-01T08:00:00.005+08:00| World| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select distinct(s2) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------+ |
| | Time|distinct(root.test.d2.s2)| |
| +-----------------------------+-------------------------+ |
| |1970-01-01T08:00:00.001+08:00| Hello| |
| |1970-01-01T08:00:00.002+08:00| hello| |
| |1970-01-01T08:00:00.003+08:00| World| |
| +-----------------------------+-------------------------+ |
| ``` |
| |
| #### Histogram |
| |
| ##### 函数简介 |
| |
| 本函数用于计算单列数值型数据的分布直方图。 |
| |
| **函数名:** HISTOGRAM |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `min`:表示所求数据范围的下限,默认值为 -Double.MAX_VALUE。 |
| + `max`:表示所求数据范围的上限,默认值为 Double.MAX_VALUE,`start`的值必须小于或等于`end`。 |
| + `count`: 表示直方图分桶的数量,默认值为 1,其值必须为正整数。 |
| |
| **输出序列:** 直方图分桶的值,其中第 i 个桶(从 1 开始计数)表示的数据范围下界为$min+ (i-1)\cdot\frac{max-min}{count}$,数据范围上界为$min+ i \cdot \frac{max-min}{count}$。 |
| |
| |
| **提示:** |
| |
| + 如果某个数据点的数值小于`min`,它会被放入第 1 个桶;如果某个数据点的数值大于`max`,它会被放入最后 1 个桶。 |
| + 数据中的空值、缺失值和`NaN`将会被忽略。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:00.000+08:00| 1.0| |
| |2020-01-01T00:00:01.000+08:00| 2.0| |
| |2020-01-01T00:00:02.000+08:00| 3.0| |
| |2020-01-01T00:00:03.000+08:00| 4.0| |
| |2020-01-01T00:00:04.000+08:00| 5.0| |
| |2020-01-01T00:00:05.000+08:00| 6.0| |
| |2020-01-01T00:00:06.000+08:00| 7.0| |
| |2020-01-01T00:00:07.000+08:00| 8.0| |
| |2020-01-01T00:00:08.000+08:00| 9.0| |
| |2020-01-01T00:00:09.000+08:00| 10.0| |
| |2020-01-01T00:00:10.000+08:00| 11.0| |
| |2020-01-01T00:00:11.000+08:00| 12.0| |
| |2020-01-01T00:00:12.000+08:00| 13.0| |
| |2020-01-01T00:00:13.000+08:00| 14.0| |
| |2020-01-01T00:00:14.000+08:00| 15.0| |
| |2020-01-01T00:00:15.000+08:00| 16.0| |
| |2020-01-01T00:00:16.000+08:00| 17.0| |
| |2020-01-01T00:00:17.000+08:00| 18.0| |
| |2020-01-01T00:00:18.000+08:00| 19.0| |
| |2020-01-01T00:00:19.000+08:00| 20.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select histogram(s1,"min"="1","max"="20","count"="10") from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+---------------------------------------------------------------+ |
| | Time|histogram(root.test.d1.s1, "min"="1", "max"="20", "count"="10")| |
| +-----------------------------+---------------------------------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 2| |
| |1970-01-01T08:00:00.001+08:00| 2| |
| |1970-01-01T08:00:00.002+08:00| 2| |
| |1970-01-01T08:00:00.003+08:00| 2| |
| |1970-01-01T08:00:00.004+08:00| 2| |
| |1970-01-01T08:00:00.005+08:00| 2| |
| |1970-01-01T08:00:00.006+08:00| 2| |
| |1970-01-01T08:00:00.007+08:00| 2| |
| |1970-01-01T08:00:00.008+08:00| 2| |
| |1970-01-01T08:00:00.009+08:00| 2| |
| +-----------------------------+---------------------------------------------------------------+ |
| ``` |
| |
| #### Integral |
| |
| ##### 函数简介 |
| |
| 本函数用于计算时间序列的数值积分,即以时间为横坐标、数值为纵坐标绘制的折线图中折线以下的面积。 |
| |
| **函数名:** INTEGRAL |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `unit`:积分求解所用的时间轴单位,取值为 "1S", "1s", "1m", "1H", "1d"(区分大小写),分别表示以毫秒、秒、分钟、小时、天为单位计算积分。 |
| 缺省情况下取 "1s",以秒为单位。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE,序列仅包含一个时间戳为 0、值为积分结果的数据点。 |
| |
| **提示:** |
| |
| + 积分值等于折线图中每相邻两个数据点和时间轴形成的直角梯形的面积之和,不同时间单位下相当于横轴进行不同倍数放缩,得到的积分值可直接按放缩倍数转换。 |
| |
| + 数据中`NaN`将会被忽略。折线将以临近两个有值数据点为准。 |
| |
| ##### 使用示例 |
| |
| ###### 参数缺省 |
| |
| 缺省情况下积分以1s为时间单位。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:01.000+08:00| 1| |
| |2020-01-01T00:00:02.000+08:00| 2| |
| |2020-01-01T00:00:03.000+08:00| 5| |
| |2020-01-01T00:00:04.000+08:00| 6| |
| |2020-01-01T00:00:05.000+08:00| 7| |
| |2020-01-01T00:00:08.000+08:00| 8| |
| |2020-01-01T00:00:09.000+08:00| NaN| |
| |2020-01-01T00:00:10.000+08:00| 10| |
| +-----------------------------+---------------+ |
| ``` |
| |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select integral(s1) from root.test.d1 where time <= 2020-01-01 00:00:10 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------+ |
| | Time|integral(root.test.d1.s1)| |
| +-----------------------------+-------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 57.5| |
| +-----------------------------+-------------------------+ |
| ``` |
| |
| 其计算公式为: |
| $$\frac{1}{2}[(1+2)\times 1 + (2+5) \times 1 + (5+6) \times 1 + (6+7) \times 1 + (7+8) \times 3 + (8+10) \times 2] = 57.5$$ |
| |
| |
| ##### 指定时间单位 |
| |
| 指定以分钟为时间单位。 |
| |
| |
| 输入序列同上,用于查询的 SQL 语句如下: |
| |
| ```sql |
| select integral(s1, "unit"="1m") from root.test.d1 where time <= 2020-01-01 00:00:10 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------+ |
| | Time|integral(root.test.d1.s1)| |
| +-----------------------------+-------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.958| |
| +-----------------------------+-------------------------+ |
| ``` |
| |
| 其计算公式为: |
| $$\frac{1}{2\times 60}[(1+2) \times 1 + (2+3) \times 1 + (5+6) \times 1 + (6+7) \times 1 + (7+8) \times 3 + (8+10) \times 2] = 0.958$$ |
| |
| #### IntegralAvg |
| |
| ##### 函数简介 |
| |
| 本函数用于计算时间序列的函数均值,即在相同时间单位下的数值积分除以序列总的时间跨度。更多关于数值积分计算的信息请参考`Integral`函数。 |
| |
| **函数名:** INTEGRALAVG |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE,序列仅包含一个时间戳为 0、值为时间加权平均结果的数据点。 |
| |
| **提示:** |
| |
| + 时间加权的平均值等于在任意时间单位`unit`下计算的数值积分(即折线图中每相邻两个数据点和时间轴形成的直角梯形的面积之和), |
| 除以相同时间单位下输入序列的时间跨度,其值与具体采用的时间单位无关,默认与 IoTDB 时间单位一致。 |
| |
| + 数据中的`NaN`将会被忽略。折线将以临近两个有值数据点为准。 |
| |
| + 输入序列为空时,函数输出结果为 0;仅有一个数据点时,输出结果为该点数值。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:01.000+08:00| 1| |
| |2020-01-01T00:00:02.000+08:00| 2| |
| |2020-01-01T00:00:03.000+08:00| 5| |
| |2020-01-01T00:00:04.000+08:00| 6| |
| |2020-01-01T00:00:05.000+08:00| 7| |
| |2020-01-01T00:00:08.000+08:00| 8| |
| |2020-01-01T00:00:09.000+08:00| NaN| |
| |2020-01-01T00:00:10.000+08:00| 10| |
| +-----------------------------+---------------+ |
| ``` |
| |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select integralavg(s1) from root.test.d1 where time <= 2020-01-01 00:00:10 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+----------------------------+ |
| | Time|integralavg(root.test.d1.s1)| |
| +-----------------------------+----------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 5.75| |
| +-----------------------------+----------------------------+ |
| ``` |
| |
| 其计算公式为: |
| $$\frac{1}{2}[(1+2)\times 1 + (2+5) \times 1 + (5+6) \times 1 + (6+7) \times 1 + (7+8) \times 3 + (8+10) \times 2] / 10 = 5.75$$ |
| |
| #### Mad |
| |
| ##### 函数简介 |
| |
| 本函数用于计算单列数值型数据的精确或近似绝对中位差,绝对中位差为所有数值与其中位数绝对偏移量的中位数。 |
| |
| 如有数据集$\{1,3,3,5,5,6,7,8,9\}$,其中位数为5,所有数值与中位数的偏移量的绝对值为$\{0,0,1,2,2,2,3,4,4\}$,其中位数为2,故而原数据集的绝对中位差为2。 |
| |
| **函数名:** MAD |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `error`:近似绝对中位差的基于数值的误差百分比,取值范围为 [0,1),默认值为 0。如当`error`=0.01 时,记精确绝对中位差为a,近似绝对中位差为b,不等式 $0.99a \le b \le 1.01a$ 成立。当`error`=0 时,计算结果为精确绝对中位差。 |
| |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE,序列仅包含一个时间戳为 0、值为绝对中位差的数据点。 |
| |
| **提示:** 数据中的空值、缺失值和`NaN`将会被忽略。 |
| |
| ##### 使用示例 |
| |
| ###### 精确查询 |
| |
| 当`error`参数缺省或为0时,本函数计算精确绝对中位差。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s0| |
| +-----------------------------+------------+ |
| |2021-03-17T10:32:17.054+08:00| 0.5319929| |
| |2021-03-17T10:32:18.054+08:00| 0.9304316| |
| |2021-03-17T10:32:19.054+08:00| -1.4800133| |
| |2021-03-17T10:32:20.054+08:00| 0.6114087| |
| |2021-03-17T10:32:21.054+08:00| 2.5163336| |
| |2021-03-17T10:32:22.054+08:00| -1.0845392| |
| |2021-03-17T10:32:23.054+08:00| 1.0562582| |
| |2021-03-17T10:32:24.054+08:00| 1.3867859| |
| |2021-03-17T10:32:25.054+08:00| -0.45429882| |
| |2021-03-17T10:32:26.054+08:00| 1.0353678| |
| |2021-03-17T10:32:27.054+08:00| 0.7307929| |
| |2021-03-17T10:32:28.054+08:00| 2.3167255| |
| |2021-03-17T10:32:29.054+08:00| 2.342443| |
| |2021-03-17T10:32:30.054+08:00| 1.5809103| |
| |2021-03-17T10:32:31.054+08:00| 1.4829416| |
| |2021-03-17T10:32:32.054+08:00| 1.5800357| |
| |2021-03-17T10:32:33.054+08:00| 0.7124368| |
| |2021-03-17T10:32:34.054+08:00| -0.78597564| |
| |2021-03-17T10:32:35.054+08:00| 1.2058644| |
| |2021-03-17T10:32:36.054+08:00| 1.4215064| |
| |2021-03-17T10:32:37.054+08:00| 1.2808295| |
| |2021-03-17T10:32:38.054+08:00| -0.6173715| |
| |2021-03-17T10:32:39.054+08:00| 0.06644377| |
| |2021-03-17T10:32:40.054+08:00| 2.349338| |
| |2021-03-17T10:32:41.054+08:00| 1.7335888| |
| |2021-03-17T10:32:42.054+08:00| 1.5872132| |
| ............ |
| Total line number = 10000 |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select mad(s0) from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------+ |
| | Time| mad(root.test.s0)| |
| +-----------------------------+------------------+ |
| |1970-01-01T08:00:00.000+08:00|0.6806197166442871| |
| +-----------------------------+------------------+ |
| ``` |
| |
| ###### 近似查询 |
| |
| 当`error`参数取值不为 0 时,本函数计算近似绝对中位差。 |
| |
| 输入序列同上,用于查询的 SQL 语句如下: |
| |
| ```sql |
| select mad(s0, "error"="0.01") from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+---------------------------------+ |
| | Time|mad(root.test.s0, "error"="0.01")| |
| +-----------------------------+---------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.6806616245859518| |
| +-----------------------------+---------------------------------+ |
| ``` |
| |
| #### Median |
| |
| ##### 函数简介 |
| |
| 本函数用于计算单列数值型数据的精确或近似中位数。中位数是顺序排列的一组数据中居于中间位置的数;当序列有偶数个时,中位数为中间二者的平均数。 |
| |
| **函数名:** MEDIAN |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `error`:近似中位数的基于排名的误差百分比,取值范围 [0,1),默认值为 0。如当`error`=0.01 时,计算出的中位数的真实排名百分比在 0.49~0.51 之间。当`error`=0 时,计算结果为精确中位数。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE,序列仅包含一个时间戳为 0、值为中位数的数据点。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s0| |
| +-----------------------------+------------+ |
| |2021-03-17T10:32:17.054+08:00| 0.5319929| |
| |2021-03-17T10:32:18.054+08:00| 0.9304316| |
| |2021-03-17T10:32:19.054+08:00| -1.4800133| |
| |2021-03-17T10:32:20.054+08:00| 0.6114087| |
| |2021-03-17T10:32:21.054+08:00| 2.5163336| |
| |2021-03-17T10:32:22.054+08:00| -1.0845392| |
| |2021-03-17T10:32:23.054+08:00| 1.0562582| |
| |2021-03-17T10:32:24.054+08:00| 1.3867859| |
| |2021-03-17T10:32:25.054+08:00| -0.45429882| |
| |2021-03-17T10:32:26.054+08:00| 1.0353678| |
| |2021-03-17T10:32:27.054+08:00| 0.7307929| |
| |2021-03-17T10:32:28.054+08:00| 2.3167255| |
| |2021-03-17T10:32:29.054+08:00| 2.342443| |
| |2021-03-17T10:32:30.054+08:00| 1.5809103| |
| |2021-03-17T10:32:31.054+08:00| 1.4829416| |
| |2021-03-17T10:32:32.054+08:00| 1.5800357| |
| |2021-03-17T10:32:33.054+08:00| 0.7124368| |
| |2021-03-17T10:32:34.054+08:00| -0.78597564| |
| |2021-03-17T10:32:35.054+08:00| 1.2058644| |
| |2021-03-17T10:32:36.054+08:00| 1.4215064| |
| |2021-03-17T10:32:37.054+08:00| 1.2808295| |
| |2021-03-17T10:32:38.054+08:00| -0.6173715| |
| |2021-03-17T10:32:39.054+08:00| 0.06644377| |
| |2021-03-17T10:32:40.054+08:00| 2.349338| |
| |2021-03-17T10:32:41.054+08:00| 1.7335888| |
| |2021-03-17T10:32:42.054+08:00| 1.5872132| |
| ............ |
| Total line number = 10000 |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select median(s0, "error"="0.01") from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------+ |
| | Time|median(root.test.s0, "error"="0.01")| |
| +-----------------------------+------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 1.021884560585022| |
| +-----------------------------+------------------------------------+ |
| ``` |
| |
| #### MinMax |
| |
| ##### 函数简介 |
| |
| 本函数将输入序列使用 min-max 方法进行标准化。最小值归一至 0,最大值归一至 1. |
| |
| **函数名:** MINMAX |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `compute`:若设置为"batch",则将数据全部读入后转换;若设置为 "stream",则需用户提供最大值及最小值进行流式计算转换。默认为 "batch"。 |
| + `min`:使用流式计算时的最小值。 |
| + `max`:使用流式计算时的最大值。 |
| |
| **输出序列**:输出单个序列,类型为 DOUBLE。 |
| |
| ##### 使用示例 |
| |
| ###### 全数据计算 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s1| |
| +-----------------------------+------------+ |
| |1970-01-01T08:00:00.100+08:00| 0.0| |
| |1970-01-01T08:00:00.200+08:00| 0.0| |
| |1970-01-01T08:00:00.300+08:00| 1.0| |
| |1970-01-01T08:00:00.400+08:00| -1.0| |
| |1970-01-01T08:00:00.500+08:00| 0.0| |
| |1970-01-01T08:00:00.600+08:00| 0.0| |
| |1970-01-01T08:00:00.700+08:00| -2.0| |
| |1970-01-01T08:00:00.800+08:00| 2.0| |
| |1970-01-01T08:00:00.900+08:00| 0.0| |
| |1970-01-01T08:00:01.000+08:00| 0.0| |
| |1970-01-01T08:00:01.100+08:00| 1.0| |
| |1970-01-01T08:00:01.200+08:00| -1.0| |
| |1970-01-01T08:00:01.300+08:00| -1.0| |
| |1970-01-01T08:00:01.400+08:00| 1.0| |
| |1970-01-01T08:00:01.500+08:00| 0.0| |
| |1970-01-01T08:00:01.600+08:00| 0.0| |
| |1970-01-01T08:00:01.700+08:00| 10.0| |
| |1970-01-01T08:00:01.800+08:00| 2.0| |
| |1970-01-01T08:00:01.900+08:00| -2.0| |
| |1970-01-01T08:00:02.000+08:00| 0.0| |
| +-----------------------------+------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select minmax(s1) from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------+ |
| | Time|minmax(root.test.s1)| |
| +-----------------------------+--------------------+ |
| |1970-01-01T08:00:00.100+08:00| 0.16666666666666666| |
| |1970-01-01T08:00:00.200+08:00| 0.16666666666666666| |
| |1970-01-01T08:00:00.300+08:00| 0.25| |
| |1970-01-01T08:00:00.400+08:00| 0.08333333333333333| |
| |1970-01-01T08:00:00.500+08:00| 0.16666666666666666| |
| |1970-01-01T08:00:00.600+08:00| 0.16666666666666666| |
| |1970-01-01T08:00:00.700+08:00| 0.0| |
| |1970-01-01T08:00:00.800+08:00| 0.3333333333333333| |
| |1970-01-01T08:00:00.900+08:00| 0.16666666666666666| |
| |1970-01-01T08:00:01.000+08:00| 0.16666666666666666| |
| |1970-01-01T08:00:01.100+08:00| 0.25| |
| |1970-01-01T08:00:01.200+08:00| 0.08333333333333333| |
| |1970-01-01T08:00:01.300+08:00| 0.08333333333333333| |
| |1970-01-01T08:00:01.400+08:00| 0.25| |
| |1970-01-01T08:00:01.500+08:00| 0.16666666666666666| |
| |1970-01-01T08:00:01.600+08:00| 0.16666666666666666| |
| |1970-01-01T08:00:01.700+08:00| 1.0| |
| |1970-01-01T08:00:01.800+08:00| 0.3333333333333333| |
| |1970-01-01T08:00:01.900+08:00| 0.0| |
| |1970-01-01T08:00:02.000+08:00| 0.16666666666666666| |
| +-----------------------------+--------------------+ |
| ``` |
| |
| #### Mode |
| |
| ##### 函数简介 |
| |
| 本函数用于计算时间序列的众数,即出现次数最多的元素。 |
| |
| **函数名:** MODE |
| |
| **输入序列:** 仅支持单个输入序列,类型可以是任意的。 |
| |
| **输出序列:** 输出单个序列,类型与输入相同,序列仅包含一个时间戳为众数第一次出现的时间戳、值为众数的数据点。 |
| |
| **提示:** |
| |
| + 如果有多个出现次数最多的元素,将会输出任意一个。 |
| + 数据中的空值和缺失值将会被忽略,但`NaN`不会被忽略。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d2.s2| |
| +-----------------------------+---------------+ |
| |1970-01-01T08:00:00.001+08:00| Hello| |
| |1970-01-01T08:00:00.002+08:00| hello| |
| |1970-01-01T08:00:00.003+08:00| Hello| |
| |1970-01-01T08:00:00.004+08:00| World| |
| |1970-01-01T08:00:00.005+08:00| World| |
| |1970-01-01T08:00:01.600+08:00| World| |
| |1970-01-15T09:37:34.451+08:00| Hello| |
| |1970-01-15T09:37:34.452+08:00| hello| |
| |1970-01-15T09:37:34.453+08:00| Hello| |
| |1970-01-15T09:37:34.454+08:00| World| |
| |1970-01-15T09:37:34.455+08:00| World| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select mode(s2) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+---------------------+ |
| | Time|mode(root.test.d2.s2)| |
| +-----------------------------+---------------------+ |
| |1970-01-01T08:00:00.004+08:00| World| |
| +-----------------------------+---------------------+ |
| ``` |
| |
| #### MvAvg |
| |
| ##### 函数简介 |
| |
| 本函数计算序列的移动平均。 |
| |
| **函数名:** MVAVG |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `window`:移动窗口的长度。默认值为 10. |
| |
| **输出序列**:输出单个序列,类型为 DOUBLE。 |
| |
| ##### 使用示例 |
| |
| ###### 指定窗口长度 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s1| |
| +-----------------------------+------------+ |
| |1970-01-01T08:00:00.100+08:00| 0.0| |
| |1970-01-01T08:00:00.200+08:00| 0.0| |
| |1970-01-01T08:00:00.300+08:00| 1.0| |
| |1970-01-01T08:00:00.400+08:00| -1.0| |
| |1970-01-01T08:00:00.500+08:00| 0.0| |
| |1970-01-01T08:00:00.600+08:00| 0.0| |
| |1970-01-01T08:00:00.700+08:00| -2.0| |
| |1970-01-01T08:00:00.800+08:00| 2.0| |
| |1970-01-01T08:00:00.900+08:00| 0.0| |
| |1970-01-01T08:00:01.000+08:00| 0.0| |
| |1970-01-01T08:00:01.100+08:00| 1.0| |
| |1970-01-01T08:00:01.200+08:00| -1.0| |
| |1970-01-01T08:00:01.300+08:00| -1.0| |
| |1970-01-01T08:00:01.400+08:00| 1.0| |
| |1970-01-01T08:00:01.500+08:00| 0.0| |
| |1970-01-01T08:00:01.600+08:00| 0.0| |
| |1970-01-01T08:00:01.700+08:00| 10.0| |
| |1970-01-01T08:00:01.800+08:00| 2.0| |
| |1970-01-01T08:00:01.900+08:00| -2.0| |
| |1970-01-01T08:00:02.000+08:00| 0.0| |
| +-----------------------------+------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select mvavg(s1, "window"="3") from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+---------------------------------+ |
| | Time|mvavg(root.test.s1, "window"="3")| |
| +-----------------------------+---------------------------------+ |
| |1970-01-01T08:00:00.300+08:00| 0.3333333333333333| |
| |1970-01-01T08:00:00.400+08:00| 0.0| |
| |1970-01-01T08:00:00.500+08:00| -0.3333333333333333| |
| |1970-01-01T08:00:00.600+08:00| 0.0| |
| |1970-01-01T08:00:00.700+08:00| -0.6666666666666666| |
| |1970-01-01T08:00:00.800+08:00| 0.0| |
| |1970-01-01T08:00:00.900+08:00| 0.6666666666666666| |
| |1970-01-01T08:00:01.000+08:00| 0.0| |
| |1970-01-01T08:00:01.100+08:00| 0.3333333333333333| |
| |1970-01-01T08:00:01.200+08:00| 0.0| |
| |1970-01-01T08:00:01.300+08:00| -0.6666666666666666| |
| |1970-01-01T08:00:01.400+08:00| 0.0| |
| |1970-01-01T08:00:01.500+08:00| 0.3333333333333333| |
| |1970-01-01T08:00:01.600+08:00| 0.0| |
| |1970-01-01T08:00:01.700+08:00| 3.3333333333333335| |
| |1970-01-01T08:00:01.800+08:00| 4.0| |
| |1970-01-01T08:00:01.900+08:00| 0.0| |
| |1970-01-01T08:00:02.000+08:00| -0.6666666666666666| |
| +-----------------------------+---------------------------------+ |
| ``` |
| |
| #### PACF |
| |
| ##### 函数简介 |
| |
| 本函数通过求解 Yule-Walker 方程,计算序列的偏自相关系数。对于特殊的输入序列,方程可能没有解,此时输出`NaN`。 |
| |
| **函数名:** PACF |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `lag`:最大滞后阶数。默认值为$\min(10\log_{10}n,n-1)$,$n$表示数据点个数。 |
| |
| **输出序列**:输出单个序列,类型为 DOUBLE。 |
| |
| ##### 使用示例 |
| |
| ###### 指定滞后阶数 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s1| |
| +-----------------------------+------------+ |
| |2019-12-27T00:00:00.000+08:00| 5.0| |
| |2019-12-27T00:05:00.000+08:00| 5.0| |
| |2019-12-27T00:10:00.000+08:00| 5.0| |
| |2019-12-27T00:15:00.000+08:00| 5.0| |
| |2019-12-27T00:20:00.000+08:00| 6.0| |
| |2019-12-27T00:25:00.000+08:00| 5.0| |
| |2019-12-27T00:30:00.000+08:00| 6.0| |
| |2019-12-27T00:35:00.000+08:00| 6.0| |
| |2019-12-27T00:40:00.000+08:00| 6.0| |
| |2019-12-27T00:45:00.000+08:00| 6.0| |
| |2019-12-27T00:50:00.000+08:00| 6.0| |
| |2019-12-27T00:55:00.000+08:00| 5.982609| |
| |2019-12-27T01:00:00.000+08:00| 5.9652176| |
| |2019-12-27T01:05:00.000+08:00| 5.947826| |
| |2019-12-27T01:10:00.000+08:00| 5.9304347| |
| |2019-12-27T01:15:00.000+08:00| 5.9130435| |
| |2019-12-27T01:20:00.000+08:00| 5.8956523| |
| |2019-12-27T01:25:00.000+08:00| 5.878261| |
| |2019-12-27T01:30:00.000+08:00| 5.8608694| |
| |2019-12-27T01:35:00.000+08:00| 5.843478| |
| ............ |
| Total line number = 18066 |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select pacf(s1, "lag"="5") from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-----------------------------+ |
| | Time|pacf(root.test.s1, "lag"="5")| |
| +-----------------------------+-----------------------------+ |
| |2019-12-27T00:00:00.000+08:00| 1.0| |
| |2019-12-27T00:05:00.000+08:00| 0.3528915091942786| |
| |2019-12-27T00:10:00.000+08:00| 0.1761346122516304| |
| |2019-12-27T00:15:00.000+08:00| 0.1492391973294682| |
| |2019-12-27T00:20:00.000+08:00| 0.03560059645868398| |
| |2019-12-27T00:25:00.000+08:00| 0.0366222998995286| |
| +-----------------------------+-----------------------------+ |
| ``` |
| |
| #### Percentile |
| |
| ##### 函数简介 |
| |
| 本函数用于计算单列数值型数据的精确或近似分位数。 |
| |
| **函数名:** PERCENTILE |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `rank`:所求分位数在所有数据中的排名百分比,取值范围为 (0,1],默认值为 0.5。如当设为 0.5时则计算中位数。 |
| + `error`:近似分位数的基于排名的误差百分比,取值范围为 [0,1),默认值为0。如`rank`=0.5 且`error`=0.01,则计算出的分位数的真实排名百分比在 0.49~0.51之间。当`error`=0 时,计算结果为精确分位数。 |
| |
| **输出序列:** 输出单个序列,类型与输入序列相同。当`error`=0时,序列仅包含一个时间戳为分位数第一次出现的时间戳、值为分位数的数据点;否则,输出值的时间戳为0。 |
| |
| **提示:** 数据中的空值、缺失值和`NaN`将会被忽略。 |
| |
| ##### 使用示例 |
| |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s0| |
| +-----------------------------+------------+ |
| |2021-03-17T10:32:17.054+08:00| 0.5319929| |
| |2021-03-17T10:32:18.054+08:00| 0.9304316| |
| |2021-03-17T10:32:19.054+08:00| -1.4800133| |
| |2021-03-17T10:32:20.054+08:00| 0.6114087| |
| |2021-03-17T10:32:21.054+08:00| 2.5163336| |
| |2021-03-17T10:32:22.054+08:00| -1.0845392| |
| |2021-03-17T10:32:23.054+08:00| 1.0562582| |
| |2021-03-17T10:32:24.054+08:00| 1.3867859| |
| |2021-03-17T10:32:25.054+08:00| -0.45429882| |
| |2021-03-17T10:32:26.054+08:00| 1.0353678| |
| |2021-03-17T10:32:27.054+08:00| 0.7307929| |
| |2021-03-17T10:32:28.054+08:00| 2.3167255| |
| |2021-03-17T10:32:29.054+08:00| 2.342443| |
| |2021-03-17T10:32:30.054+08:00| 1.5809103| |
| |2021-03-17T10:32:31.054+08:00| 1.4829416| |
| |2021-03-17T10:32:32.054+08:00| 1.5800357| |
| |2021-03-17T10:32:33.054+08:00| 0.7124368| |
| |2021-03-17T10:32:34.054+08:00| -0.78597564| |
| |2021-03-17T10:32:35.054+08:00| 1.2058644| |
| |2021-03-17T10:32:36.054+08:00| 1.4215064| |
| |2021-03-17T10:32:37.054+08:00| 1.2808295| |
| |2021-03-17T10:32:38.054+08:00| -0.6173715| |
| |2021-03-17T10:32:39.054+08:00| 0.06644377| |
| |2021-03-17T10:32:40.054+08:00| 2.349338| |
| |2021-03-17T10:32:41.054+08:00| 1.7335888| |
| |2021-03-17T10:32:42.054+08:00| 1.5872132| |
| ............ |
| Total line number = 10000 |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select percentile(s0, "rank"="0.2", "error"="0.01") from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------------------------+ |
| | Time|percentile(root.test.s0, "rank"="0.2", "error"="0.01")| |
| +-----------------------------+------------------------------------------------------+ |
| |2021-03-17T10:35:02.054+08:00| 0.1801469624042511| |
| +-----------------------------+------------------------------------------------------+ |
| ``` |
| |
| #### Quantile |
| |
| ##### 函数简介 |
| |
| 本函数用于计算单列数值型数据的近似分位数。本函数基于KLL sketch算法实现。 |
| |
| **函数名:** QUANTILE |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `rank`:所求分位数在所有数据中的排名比,取值范围为 (0,1],默认值为 0.5。如当设为 0.5时则计算近似中位数。 |
| + `K`:允许维护的KLL sketch大小,最小值为100,默认值为800。如`rank`=0.5 且`K`=800,则计算出的分位数的真实排名比有至少99%的可能性在 0.49~0.51之间。 |
| |
| **输出序列:** 输出单个序列,类型与输入序列相同。输出值的时间戳为0。 |
| |
| **提示:** 数据中的空值、缺失值和`NaN`将会被忽略。 |
| |
| ##### 使用示例 |
| |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s0| |
| +-----------------------------+------------+ |
| |2021-03-17T10:32:17.054+08:00| 0.5319929| |
| |2021-03-17T10:32:18.054+08:00| 0.9304316| |
| |2021-03-17T10:32:19.054+08:00| -1.4800133| |
| |2021-03-17T10:32:20.054+08:00| 0.6114087| |
| |2021-03-17T10:32:21.054+08:00| 2.5163336| |
| |2021-03-17T10:32:22.054+08:00| -1.0845392| |
| |2021-03-17T10:32:23.054+08:00| 1.0562582| |
| |2021-03-17T10:32:24.054+08:00| 1.3867859| |
| |2021-03-17T10:32:25.054+08:00| -0.45429882| |
| |2021-03-17T10:32:26.054+08:00| 1.0353678| |
| |2021-03-17T10:32:27.054+08:00| 0.7307929| |
| |2021-03-17T10:32:28.054+08:00| 2.3167255| |
| |2021-03-17T10:32:29.054+08:00| 2.342443| |
| |2021-03-17T10:32:30.054+08:00| 1.5809103| |
| |2021-03-17T10:32:31.054+08:00| 1.4829416| |
| |2021-03-17T10:32:32.054+08:00| 1.5800357| |
| |2021-03-17T10:32:33.054+08:00| 0.7124368| |
| |2021-03-17T10:32:34.054+08:00| -0.78597564| |
| |2021-03-17T10:32:35.054+08:00| 1.2058644| |
| |2021-03-17T10:32:36.054+08:00| 1.4215064| |
| |2021-03-17T10:32:37.054+08:00| 1.2808295| |
| |2021-03-17T10:32:38.054+08:00| -0.6173715| |
| |2021-03-17T10:32:39.054+08:00| 0.06644377| |
| |2021-03-17T10:32:40.054+08:00| 2.349338| |
| |2021-03-17T10:32:41.054+08:00| 1.7335888| |
| |2021-03-17T10:32:42.054+08:00| 1.5872132| |
| ............ |
| Total line number = 10000 |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select quantile(s0, "rank"="0.2", "K"="800") from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------------------------+ |
| | Time|quantile(root.test.s0, "rank"="0.2", "K"="800")| |
| +-----------------------------+------------------------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.1801469624042511| |
| +-----------------------------+------------------------------------------------------+ |
| ``` |
| |
| #### Period |
| |
| ##### 函数简介 |
| |
| 本函数用于计算单列数值型数据的周期。 |
| |
| **函数名:** PERIOD |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **输出序列:** 输出单个序列,类型为 INT32,序列仅包含一个时间戳为 0、值为周期的数据点。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d3.s1| |
| +-----------------------------+---------------+ |
| |1970-01-01T08:00:00.001+08:00| 1.0| |
| |1970-01-01T08:00:00.002+08:00| 2.0| |
| |1970-01-01T08:00:00.003+08:00| 3.0| |
| |1970-01-01T08:00:00.004+08:00| 1.0| |
| |1970-01-01T08:00:00.005+08:00| 2.0| |
| |1970-01-01T08:00:00.006+08:00| 3.0| |
| |1970-01-01T08:00:00.007+08:00| 1.0| |
| |1970-01-01T08:00:00.008+08:00| 2.0| |
| |1970-01-01T08:00:00.009+08:00| 3.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select period(s1) from root.test.d3 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-----------------------+ |
| | Time|period(root.test.d3.s1)| |
| +-----------------------------+-----------------------+ |
| |1970-01-01T08:00:00.000+08:00| 3| |
| +-----------------------------+-----------------------+ |
| ``` |
| |
| #### QLB |
| |
| ##### 函数简介 |
| |
| 本函数对输入序列计算$Q_{LB} $统计量,并计算对应的p值。p值越小表明序列越有可能为非平稳序列。 |
| |
| **函数名:** QLB |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `lag`:计算时用到的最大延迟阶数,取值应为 1 至 n-2 之间的整数,n 为序列采样总数。默认取 n-2。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE。该序列是$Q_{LB} $统计量对应的 p 值,时间标签代表偏移阶数。 |
| |
| **提示:** $Q_{LB} $统计量由自相关系数求得,如需得到统计量而非 p 值,可以使用 ACF 函数。 |
| |
| ##### 使用示例 |
| |
| ###### 使用默认参数 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |1970-01-01T00:00:00.100+08:00| 1.22| |
| |1970-01-01T00:00:00.200+08:00| -2.78| |
| |1970-01-01T00:00:00.300+08:00| 1.53| |
| |1970-01-01T00:00:00.400+08:00| 0.70| |
| |1970-01-01T00:00:00.500+08:00| 0.75| |
| |1970-01-01T00:00:00.600+08:00| -0.72| |
| |1970-01-01T00:00:00.700+08:00| -0.22| |
| |1970-01-01T00:00:00.800+08:00| 0.28| |
| |1970-01-01T00:00:00.900+08:00| 0.57| |
| |1970-01-01T00:00:01.000+08:00| -0.22| |
| |1970-01-01T00:00:01.100+08:00| -0.72| |
| |1970-01-01T00:00:01.200+08:00| 1.34| |
| |1970-01-01T00:00:01.300+08:00| -0.25| |
| |1970-01-01T00:00:01.400+08:00| 0.17| |
| |1970-01-01T00:00:01.500+08:00| 2.51| |
| |1970-01-01T00:00:01.600+08:00| 1.42| |
| |1970-01-01T00:00:01.700+08:00| -1.34| |
| |1970-01-01T00:00:01.800+08:00| -0.01| |
| |1970-01-01T00:00:01.900+08:00| -0.49| |
| |1970-01-01T00:00:02.000+08:00| 1.63| |
| +-----------------------------+---------------+ |
| ``` |
| |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select QLB(s1) from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------+ |
| | Time|QLB(root.test.d1.s1)| |
| +-----------------------------+--------------------+ |
| |1970-01-01T00:00:00.001+08:00| 0.2168702295315677| |
| |1970-01-01T00:00:00.002+08:00| 0.3068948509261751| |
| |1970-01-01T00:00:00.003+08:00| 0.4217859150918444| |
| |1970-01-01T00:00:00.004+08:00| 0.5114539874276656| |
| |1970-01-01T00:00:00.005+08:00| 0.6560619525616759| |
| |1970-01-01T00:00:00.006+08:00| 0.7722398654053280| |
| |1970-01-01T00:00:00.007+08:00| 0.8532491661465290| |
| |1970-01-01T00:00:00.008+08:00| 0.9028575017542528| |
| |1970-01-01T00:00:00.009+08:00| 0.9434989988192729| |
| |1970-01-01T00:00:00.010+08:00| 0.8950280161464689| |
| |1970-01-01T00:00:00.011+08:00| 0.7701048398839656| |
| |1970-01-01T00:00:00.012+08:00| 0.7845536060001281| |
| |1970-01-01T00:00:00.013+08:00| 0.5943030981705825| |
| |1970-01-01T00:00:00.014+08:00| 0.4618413512531093| |
| |1970-01-01T00:00:00.015+08:00| 0.2645948244673964| |
| |1970-01-01T00:00:00.016+08:00| 0.3167530476666645| |
| |1970-01-01T00:00:00.017+08:00| 0.2330010780351453| |
| |1970-01-01T00:00:00.018+08:00| 0.0666611237622325| |
| +-----------------------------+--------------------+ |
| ``` |
| |
| #### Resample |
| |
| ##### 函数简介 |
| |
| 本函数对输入序列按照指定的频率进行重采样,包括上采样和下采样。目前,本函数支持的上采样方法包括`NaN`填充法 (NaN)、前值填充法 (FFill)、后值填充法 (BFill) 以及线性插值法 (Linear);本函数支持的下采样方法为分组聚合,聚合方法包括最大值 (Max)、最小值 (Min)、首值 (First)、末值 (Last)、平均值 (Mean)和中位数 (Median)。 |
| |
| **函数名:** RESAMPLE |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `every`:重采样频率,是一个有单位的正数。目前支持五种单位,分别是 'ms'(毫秒)、's'(秒)、'm'(分钟)、'h'(小时)和'd'(天)。该参数不允许缺省。 |
| + `interp`:上采样的插值方法,取值为 'NaN'、'FFill'、'BFill' 或 'Linear'。在缺省情况下,使用`NaN`填充法。 |
| + `aggr`:下采样的聚合方法,取值为 'Max'、'Min'、'First'、'Last'、'Mean' 或 'Median'。在缺省情况下,使用平均数聚合。 |
| + `start`:重采样的起始时间(包含),是一个格式为 'yyyy-MM-dd HH:mm:ss' 的时间字符串。在缺省情况下,使用第一个有效数据点的时间戳。 |
| + `end`:重采样的结束时间(不包含),是一个格式为 'yyyy-MM-dd HH:mm:ss' 的时间字符串。在缺省情况下,使用最后一个有效数据点的时间戳。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE。该序列按照重采样频率严格等间隔分布。 |
| |
| **提示:** 数据中的`NaN`将会被忽略。 |
| |
| ##### 使用示例 |
| |
| ###### 上采样 |
| |
| 当重采样频率高于数据原始频率时,将会进行上采样。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2021-03-06T16:00:00.000+08:00| 3.09| |
| |2021-03-06T16:15:00.000+08:00| 3.53| |
| |2021-03-06T16:30:00.000+08:00| 3.5| |
| |2021-03-06T16:45:00.000+08:00| 3.51| |
| |2021-03-06T17:00:00.000+08:00| 3.41| |
| +-----------------------------+---------------+ |
| ``` |
| |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select resample(s1,'every'='5m','interp'='linear') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+----------------------------------------------------------+ |
| | Time|resample(root.test.d1.s1, "every"="5m", "interp"="linear")| |
| +-----------------------------+----------------------------------------------------------+ |
| |2021-03-06T16:00:00.000+08:00| 3.0899999141693115| |
| |2021-03-06T16:05:00.000+08:00| 3.2366665999094644| |
| |2021-03-06T16:10:00.000+08:00| 3.3833332856496177| |
| |2021-03-06T16:15:00.000+08:00| 3.5299999713897705| |
| |2021-03-06T16:20:00.000+08:00| 3.5199999809265137| |
| |2021-03-06T16:25:00.000+08:00| 3.509999990463257| |
| |2021-03-06T16:30:00.000+08:00| 3.5| |
| |2021-03-06T16:35:00.000+08:00| 3.503333330154419| |
| |2021-03-06T16:40:00.000+08:00| 3.506666660308838| |
| |2021-03-06T16:45:00.000+08:00| 3.509999990463257| |
| |2021-03-06T16:50:00.000+08:00| 3.4766666889190674| |
| |2021-03-06T16:55:00.000+08:00| 3.443333387374878| |
| |2021-03-06T17:00:00.000+08:00| 3.4100000858306885| |
| +-----------------------------+----------------------------------------------------------+ |
| ``` |
| |
| ###### 下采样 |
| |
| 当重采样频率低于数据原始频率时,将会进行下采样。 |
| |
| 输入序列同上,用于查询的 SQL 语句如下: |
| |
| ```sql |
| select resample(s1,'every'='30m','aggr'='first') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------------------------------------------+ |
| | Time|resample(root.test.d1.s1, "every"="30m", "aggr"="first")| |
| +-----------------------------+--------------------------------------------------------+ |
| |2021-03-06T16:00:00.000+08:00| 3.0899999141693115| |
| |2021-03-06T16:30:00.000+08:00| 3.5| |
| |2021-03-06T17:00:00.000+08:00| 3.4100000858306885| |
| +-----------------------------+--------------------------------------------------------+ |
| ``` |
| |
| |
| ###### 指定重采样时间段 |
| |
| 可以使用`start`和`end`两个参数指定重采样的时间段,超出实际时间范围的部分会被插值填补。 |
| |
| 输入序列同上,用于查询的 SQL 语句如下: |
| |
| ```sql |
| select resample(s1,'every'='30m','start'='2021-03-06 15:00:00') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-----------------------------------------------------------------------+ |
| | Time|resample(root.test.d1.s1, "every"="30m", "start"="2021-03-06 15:00:00")| |
| +-----------------------------+-----------------------------------------------------------------------+ |
| |2021-03-06T15:00:00.000+08:00| NaN| |
| |2021-03-06T15:30:00.000+08:00| NaN| |
| |2021-03-06T16:00:00.000+08:00| 3.309999942779541| |
| |2021-03-06T16:30:00.000+08:00| 3.5049999952316284| |
| |2021-03-06T17:00:00.000+08:00| 3.4100000858306885| |
| +-----------------------------+-----------------------------------------------------------------------+ |
| ``` |
| |
| #### Sample |
| |
| ##### 函数简介 |
| |
| 本函数对输入序列进行采样,即从输入序列中选取指定数量的数据点并输出。目前,本函数支持三种采样方法:**蓄水池采样法 (reservoir sampling)** 对数据进行随机采样,所有数据点被采样的概率相同;**等距采样法 (isometric sampling)** 按照相等的索引间隔对数据进行采样,**最大三角采样法 (triangle sampling)** 对所有数据会按采样率分桶,每个桶内会计算数据点间三角形面积,并保留面积最大的点,该算法通常用于数据的可视化展示中,采用过程可以保证一些关键的突变点在采用中得到保留,更多抽样算法细节可以阅读论文 [here](http://skemman.is/stream/get/1946/15343/37285/3/SS_MSthesis.pdf)。 |
| |
| **函数名:** SAMPLE |
| |
| **输入序列:** 仅支持单个输入序列,类型可以是任意的。 |
| |
| **参数:** |
| |
| + `method`:采样方法,取值为 'reservoir','isometric' 或 'triangle' 。在缺省情况下,采用蓄水池采样法。 |
| + `k`:采样数,它是一个正整数,在缺省情况下为 1。 |
| |
| **输出序列:** 输出单个序列,类型与输入序列相同。该序列的长度为采样数,序列中的每一个数据点都来自于输入序列。 |
| |
| **提示:** 如果采样数大于序列长度,那么输入序列中所有的数据点都会被输出。 |
| |
| ##### 使用示例 |
| |
| |
| ###### 蓄水池采样 |
| |
| 当`method`参数为 'reservoir' 或缺省时,采用蓄水池采样法对输入序列进行采样。由于该采样方法具有随机性,下面展示的输出序列只是一种可能的结果。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:01.000+08:00| 1.0| |
| |2020-01-01T00:00:02.000+08:00| 2.0| |
| |2020-01-01T00:00:03.000+08:00| 3.0| |
| |2020-01-01T00:00:04.000+08:00| 4.0| |
| |2020-01-01T00:00:05.000+08:00| 5.0| |
| |2020-01-01T00:00:06.000+08:00| 6.0| |
| |2020-01-01T00:00:07.000+08:00| 7.0| |
| |2020-01-01T00:00:08.000+08:00| 8.0| |
| |2020-01-01T00:00:09.000+08:00| 9.0| |
| |2020-01-01T00:00:10.000+08:00| 10.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select sample(s1,'method'='reservoir','k'='5') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------------------------+ |
| | Time|sample(root.test.d1.s1, "method"="reservoir", "k"="5")| |
| +-----------------------------+------------------------------------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 2.0| |
| |2020-01-01T00:00:03.000+08:00| 3.0| |
| |2020-01-01T00:00:05.000+08:00| 5.0| |
| |2020-01-01T00:00:08.000+08:00| 8.0| |
| |2020-01-01T00:00:10.000+08:00| 10.0| |
| +-----------------------------+------------------------------------------------------+ |
| ``` |
| |
| |
| ###### 等距采样 |
| |
| 当`method`参数为 'isometric' 时,采用等距采样法对输入序列进行采样。 |
| |
| 输入序列同上,用于查询的 SQL 语句如下: |
| |
| ```sql |
| select sample(s1,'method'='isometric','k'='5') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------------------------+ |
| | Time|sample(root.test.d1.s1, "method"="isometric", "k"="5")| |
| +-----------------------------+------------------------------------------------------+ |
| |2020-01-01T00:00:01.000+08:00| 1.0| |
| |2020-01-01T00:00:03.000+08:00| 3.0| |
| |2020-01-01T00:00:05.000+08:00| 5.0| |
| |2020-01-01T00:00:07.000+08:00| 7.0| |
| |2020-01-01T00:00:09.000+08:00| 9.0| |
| +-----------------------------+------------------------------------------------------+ |
| ``` |
| |
| #### Segment |
| |
| ##### 函数简介 |
| |
| 本函数按照数据的线性变化趋势将数据划分为多个子序列,返回分段直线拟合后的子序列首值或所有拟合值。 |
| |
| **函数名:** SEGMENT |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `output`:"all" 输出所有拟合值;"first" 输出子序列起点拟合值。默认为 "first"。 |
| |
| + `error`:判定存在线性趋势的误差允许阈值。误差的定义为子序列进行线性拟合的误差的绝对值的均值。默认为 0.1. |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE。 |
| |
| **提示:** 函数默认所有数据等时间间隔分布。函数读取所有数据,若原始数据过多,请先进行降采样处理。拟合采用自底向上方法,子序列的尾值可能会被认作子序列首值输出。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s1| |
| +-----------------------------+------------+ |
| |1970-01-01T08:00:00.000+08:00| 5.0| |
| |1970-01-01T08:00:00.100+08:00| 0.0| |
| |1970-01-01T08:00:00.200+08:00| 1.0| |
| |1970-01-01T08:00:00.300+08:00| 2.0| |
| |1970-01-01T08:00:00.400+08:00| 3.0| |
| |1970-01-01T08:00:00.500+08:00| 4.0| |
| |1970-01-01T08:00:00.600+08:00| 5.0| |
| |1970-01-01T08:00:00.700+08:00| 6.0| |
| |1970-01-01T08:00:00.800+08:00| 7.0| |
| |1970-01-01T08:00:00.900+08:00| 8.0| |
| |1970-01-01T08:00:01.000+08:00| 9.0| |
| |1970-01-01T08:00:01.100+08:00| 9.1| |
| |1970-01-01T08:00:01.200+08:00| 9.2| |
| |1970-01-01T08:00:01.300+08:00| 9.3| |
| |1970-01-01T08:00:01.400+08:00| 9.4| |
| |1970-01-01T08:00:01.500+08:00| 9.5| |
| |1970-01-01T08:00:01.600+08:00| 9.6| |
| |1970-01-01T08:00:01.700+08:00| 9.7| |
| |1970-01-01T08:00:01.800+08:00| 9.8| |
| |1970-01-01T08:00:01.900+08:00| 9.9| |
| |1970-01-01T08:00:02.000+08:00| 10.0| |
| |1970-01-01T08:00:02.100+08:00| 8.0| |
| |1970-01-01T08:00:02.200+08:00| 6.0| |
| |1970-01-01T08:00:02.300+08:00| 4.0| |
| |1970-01-01T08:00:02.400+08:00| 2.0| |
| |1970-01-01T08:00:02.500+08:00| 0.0| |
| |1970-01-01T08:00:02.600+08:00| -2.0| |
| |1970-01-01T08:00:02.700+08:00| -4.0| |
| |1970-01-01T08:00:02.800+08:00| -6.0| |
| |1970-01-01T08:00:02.900+08:00| -8.0| |
| |1970-01-01T08:00:03.000+08:00| -10.0| |
| |1970-01-01T08:00:03.100+08:00| 10.0| |
| |1970-01-01T08:00:03.200+08:00| 10.0| |
| |1970-01-01T08:00:03.300+08:00| 10.0| |
| |1970-01-01T08:00:03.400+08:00| 10.0| |
| |1970-01-01T08:00:03.500+08:00| 10.0| |
| |1970-01-01T08:00:03.600+08:00| 10.0| |
| |1970-01-01T08:00:03.700+08:00| 10.0| |
| |1970-01-01T08:00:03.800+08:00| 10.0| |
| |1970-01-01T08:00:03.900+08:00| 10.0| |
| +-----------------------------+------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select segment(s1,"error"="0.1") from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------+ |
| | Time|segment(root.test.s1, "error"="0.1")| |
| +-----------------------------+------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 5.0| |
| |1970-01-01T08:00:00.200+08:00| 1.0| |
| |1970-01-01T08:00:01.000+08:00| 9.0| |
| |1970-01-01T08:00:02.000+08:00| 10.0| |
| |1970-01-01T08:00:03.000+08:00| -10.0| |
| |1970-01-01T08:00:03.200+08:00| 10.0| |
| +-----------------------------+------------------------------------+ |
| ``` |
| |
| #### Skew |
| |
| ##### 函数简介 |
| |
| 本函数用于计算单列数值型数据的总体偏度 |
| |
| **函数名:** SKEW |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE,序列仅包含一个时间戳为 0、值为总体偏度的数据点。 |
| |
| **提示:** 数据中的空值、缺失值和`NaN`将会被忽略。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:00.000+08:00| 1.0| |
| |2020-01-01T00:00:01.000+08:00| 2.0| |
| |2020-01-01T00:00:02.000+08:00| 3.0| |
| |2020-01-01T00:00:03.000+08:00| 4.0| |
| |2020-01-01T00:00:04.000+08:00| 5.0| |
| |2020-01-01T00:00:05.000+08:00| 6.0| |
| |2020-01-01T00:00:06.000+08:00| 7.0| |
| |2020-01-01T00:00:07.000+08:00| 8.0| |
| |2020-01-01T00:00:08.000+08:00| 9.0| |
| |2020-01-01T00:00:09.000+08:00| 10.0| |
| |2020-01-01T00:00:10.000+08:00| 10.0| |
| |2020-01-01T00:00:11.000+08:00| 10.0| |
| |2020-01-01T00:00:12.000+08:00| 10.0| |
| |2020-01-01T00:00:13.000+08:00| 10.0| |
| |2020-01-01T00:00:14.000+08:00| 10.0| |
| |2020-01-01T00:00:15.000+08:00| 10.0| |
| |2020-01-01T00:00:16.000+08:00| 10.0| |
| |2020-01-01T00:00:17.000+08:00| 10.0| |
| |2020-01-01T00:00:18.000+08:00| 10.0| |
| |2020-01-01T00:00:19.000+08:00| 10.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select skew(s1) from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-----------------------+ |
| | Time| skew(root.test.d1.s1)| |
| +-----------------------------+-----------------------+ |
| |1970-01-01T08:00:00.000+08:00| -0.9998427402292644| |
| +-----------------------------+-----------------------+ |
| ``` |
| |
| #### Spline |
| |
| ##### 函数简介 |
| |
| 本函数提供对原始序列进行三次样条曲线拟合后的插值重采样。 |
| |
| **函数名:** SPLINE |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `points`:重采样个数。 |
| |
| **输出序列**:输出单个序列,类型为 DOUBLE。 |
| |
| **提示**:输出序列保留输入序列的首尾值,等时间间隔采样。仅当输入点个数不少于 4 个时才计算插值。 |
| |
| ##### 使用示例 |
| |
| ###### 指定插值个数 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s1| |
| +-----------------------------+------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.0| |
| |1970-01-01T08:00:00.300+08:00| 1.2| |
| |1970-01-01T08:00:00.500+08:00| 1.7| |
| |1970-01-01T08:00:00.700+08:00| 2.0| |
| |1970-01-01T08:00:00.900+08:00| 2.1| |
| |1970-01-01T08:00:01.100+08:00| 2.0| |
| |1970-01-01T08:00:01.200+08:00| 1.8| |
| |1970-01-01T08:00:01.300+08:00| 1.2| |
| |1970-01-01T08:00:01.400+08:00| 1.0| |
| |1970-01-01T08:00:01.500+08:00| 1.6| |
| +-----------------------------+------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select spline(s1, "points"="151") from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------+ |
| | Time|spline(root.test.s1, "points"="151")| |
| +-----------------------------+------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.0| |
| |1970-01-01T08:00:00.010+08:00| 0.04870000251134237| |
| |1970-01-01T08:00:00.020+08:00| 0.09680000495910646| |
| |1970-01-01T08:00:00.030+08:00| 0.14430000734329226| |
| |1970-01-01T08:00:00.040+08:00| 0.19120000966389972| |
| |1970-01-01T08:00:00.050+08:00| 0.23750001192092896| |
| |1970-01-01T08:00:00.060+08:00| 0.2832000141143799| |
| |1970-01-01T08:00:00.070+08:00| 0.32830001624425253| |
| |1970-01-01T08:00:00.080+08:00| 0.3728000183105469| |
| |1970-01-01T08:00:00.090+08:00| 0.416700020313263| |
| |1970-01-01T08:00:00.100+08:00| 0.4600000222524008| |
| |1970-01-01T08:00:00.110+08:00| 0.5027000241279602| |
| |1970-01-01T08:00:00.120+08:00| 0.5448000259399414| |
| |1970-01-01T08:00:00.130+08:00| 0.5863000276883443| |
| |1970-01-01T08:00:00.140+08:00| 0.627200029373169| |
| |1970-01-01T08:00:00.150+08:00| 0.6675000309944153| |
| |1970-01-01T08:00:00.160+08:00| 0.7072000325520833| |
| |1970-01-01T08:00:00.170+08:00| 0.7463000340461731| |
| |1970-01-01T08:00:00.180+08:00| 0.7848000354766846| |
| |1970-01-01T08:00:00.190+08:00| 0.8227000368436178| |
| |1970-01-01T08:00:00.200+08:00| 0.8600000381469728| |
| |1970-01-01T08:00:00.210+08:00| 0.8967000393867494| |
| |1970-01-01T08:00:00.220+08:00| 0.9328000405629477| |
| |1970-01-01T08:00:00.230+08:00| 0.9683000416755676| |
| |1970-01-01T08:00:00.240+08:00| 1.0032000427246095| |
| |1970-01-01T08:00:00.250+08:00| 1.037500043710073| |
| |1970-01-01T08:00:00.260+08:00| 1.071200044631958| |
| |1970-01-01T08:00:00.270+08:00| 1.1043000454902647| |
| |1970-01-01T08:00:00.280+08:00| 1.1368000462849934| |
| |1970-01-01T08:00:00.290+08:00| 1.1687000470161437| |
| |1970-01-01T08:00:00.300+08:00| 1.2000000476837158| |
| |1970-01-01T08:00:00.310+08:00| 1.2307000483103594| |
| |1970-01-01T08:00:00.320+08:00| 1.2608000489139557| |
| |1970-01-01T08:00:00.330+08:00| 1.2903000494873524| |
| |1970-01-01T08:00:00.340+08:00| 1.3192000500233967| |
| |1970-01-01T08:00:00.350+08:00| 1.3475000505149364| |
| |1970-01-01T08:00:00.360+08:00| 1.3752000509548186| |
| |1970-01-01T08:00:00.370+08:00| 1.402300051335891| |
| |1970-01-01T08:00:00.380+08:00| 1.4288000516510009| |
| |1970-01-01T08:00:00.390+08:00| 1.4547000518929958| |
| |1970-01-01T08:00:00.400+08:00| 1.480000052054723| |
| |1970-01-01T08:00:00.410+08:00| 1.5047000521290301| |
| |1970-01-01T08:00:00.420+08:00| 1.5288000521087646| |
| |1970-01-01T08:00:00.430+08:00| 1.5523000519867738| |
| |1970-01-01T08:00:00.440+08:00| 1.575200051755905| |
| |1970-01-01T08:00:00.450+08:00| 1.597500051409006| |
| |1970-01-01T08:00:00.460+08:00| 1.619200050938924| |
| |1970-01-01T08:00:00.470+08:00| 1.6403000503385066| |
| |1970-01-01T08:00:00.480+08:00| 1.660800049600601| |
| |1970-01-01T08:00:00.490+08:00| 1.680700048718055| |
| |1970-01-01T08:00:00.500+08:00| 1.7000000476837158| |
| |1970-01-01T08:00:00.510+08:00| 1.7188475466453037| |
| |1970-01-01T08:00:00.520+08:00| 1.7373800457262996| |
| |1970-01-01T08:00:00.530+08:00| 1.7555825448831923| |
| |1970-01-01T08:00:00.540+08:00| 1.7734400440724702| |
| |1970-01-01T08:00:00.550+08:00| 1.790937543250622| |
| |1970-01-01T08:00:00.560+08:00| 1.8080600423741364| |
| |1970-01-01T08:00:00.570+08:00| 1.8247925413995016| |
| |1970-01-01T08:00:00.580+08:00| 1.8411200402832066| |
| |1970-01-01T08:00:00.590+08:00| 1.8570275389817397| |
| |1970-01-01T08:00:00.600+08:00| 1.8725000374515897| |
| |1970-01-01T08:00:00.610+08:00| 1.8875225356492449| |
| |1970-01-01T08:00:00.620+08:00| 1.902080033531194| |
| |1970-01-01T08:00:00.630+08:00| 1.9161575310539258| |
| |1970-01-01T08:00:00.640+08:00| 1.9297400281739288| |
| |1970-01-01T08:00:00.650+08:00| 1.9428125248476913| |
| |1970-01-01T08:00:00.660+08:00| 1.9553600210317021| |
| |1970-01-01T08:00:00.670+08:00| 1.96736751668245| |
| |1970-01-01T08:00:00.680+08:00| 1.9788200117564232| |
| |1970-01-01T08:00:00.690+08:00| 1.9897025062101101| |
| |1970-01-01T08:00:00.700+08:00| 2.0| |
| |1970-01-01T08:00:00.710+08:00| 2.0097024933913334| |
| |1970-01-01T08:00:00.720+08:00| 2.0188199867081615| |
| |1970-01-01T08:00:00.730+08:00| 2.027367479995188| |
| |1970-01-01T08:00:00.740+08:00| 2.0353599732971155| |
| |1970-01-01T08:00:00.750+08:00| 2.0428124666586482| |
| |1970-01-01T08:00:00.760+08:00| 2.049739960124489| |
| |1970-01-01T08:00:00.770+08:00| 2.056157453739342| |
| |1970-01-01T08:00:00.780+08:00| 2.06207994754791| |
| |1970-01-01T08:00:00.790+08:00| 2.067522441594897| |
| |1970-01-01T08:00:00.800+08:00| 2.072499935925006| |
| |1970-01-01T08:00:00.810+08:00| 2.07702743058294| |
| |1970-01-01T08:00:00.820+08:00| 2.081119925613404| |
| |1970-01-01T08:00:00.830+08:00| 2.0847924210611| |
| |1970-01-01T08:00:00.840+08:00| 2.0880599169707317| |
| |1970-01-01T08:00:00.850+08:00| 2.0909374133870027| |
| |1970-01-01T08:00:00.860+08:00| 2.0934399103546166| |
| |1970-01-01T08:00:00.870+08:00| 2.0955824079182768| |
| |1970-01-01T08:00:00.880+08:00| 2.0973799061226863| |
| |1970-01-01T08:00:00.890+08:00| 2.098847405012549| |
| |1970-01-01T08:00:00.900+08:00| 2.0999999046325684| |
| |1970-01-01T08:00:00.910+08:00| 2.1005574051201332| |
| |1970-01-01T08:00:00.920+08:00| 2.1002599065303778| |
| |1970-01-01T08:00:00.930+08:00| 2.0991524087846245| |
| |1970-01-01T08:00:00.940+08:00| 2.0972799118041947| |
| |1970-01-01T08:00:00.950+08:00| 2.0946874155104105| |
| |1970-01-01T08:00:00.960+08:00| 2.0914199198245944| |
| |1970-01-01T08:00:00.970+08:00| 2.0875224246680673| |
| |1970-01-01T08:00:00.980+08:00| 2.083039929962151| |
| |1970-01-01T08:00:00.990+08:00| 2.0780174356281687| |
| |1970-01-01T08:00:01.000+08:00| 2.0724999415874406| |
| |1970-01-01T08:00:01.010+08:00| 2.06653244776129| |
| |1970-01-01T08:00:01.020+08:00| 2.060159954071038| |
| |1970-01-01T08:00:01.030+08:00| 2.053427460438006| |
| |1970-01-01T08:00:01.040+08:00| 2.046379966783517| |
| |1970-01-01T08:00:01.050+08:00| 2.0390624730288924| |
| |1970-01-01T08:00:01.060+08:00| 2.031519979095454| |
| |1970-01-01T08:00:01.070+08:00| 2.0237974849045237| |
| |1970-01-01T08:00:01.080+08:00| 2.015939990377423| |
| |1970-01-01T08:00:01.090+08:00| 2.0079924954354746| |
| |1970-01-01T08:00:01.100+08:00| 2.0| |
| |1970-01-01T08:00:01.110+08:00| 1.9907018211101906| |
| |1970-01-01T08:00:01.120+08:00| 1.9788509124245144| |
| |1970-01-01T08:00:01.130+08:00| 1.9645127287932083| |
| |1970-01-01T08:00:01.140+08:00| 1.9477527250665083| |
| |1970-01-01T08:00:01.150+08:00| 1.9286363560946513| |
| |1970-01-01T08:00:01.160+08:00| 1.9072290767278735| |
| |1970-01-01T08:00:01.170+08:00| 1.8835963418164114| |
| |1970-01-01T08:00:01.180+08:00| 1.8578036062105014| |
| |1970-01-01T08:00:01.190+08:00| 1.8299163247603802| |
| |1970-01-01T08:00:01.200+08:00| 1.7999999523162842| |
| |1970-01-01T08:00:01.210+08:00| 1.7623635841923329| |
| |1970-01-01T08:00:01.220+08:00| 1.7129696477516976| |
| |1970-01-01T08:00:01.230+08:00| 1.6543635959181928| |
| |1970-01-01T08:00:01.240+08:00| 1.5890908816156328| |
| |1970-01-01T08:00:01.250+08:00| 1.5196969577678319| |
| |1970-01-01T08:00:01.260+08:00| 1.4487272772986044| |
| |1970-01-01T08:00:01.270+08:00| 1.3787272931317647| |
| |1970-01-01T08:00:01.280+08:00| 1.3122424581911272| |
| |1970-01-01T08:00:01.290+08:00| 1.251818225400506| |
| |1970-01-01T08:00:01.300+08:00| 1.2000000476837158| |
| |1970-01-01T08:00:01.310+08:00| 1.1548000470995912| |
| |1970-01-01T08:00:01.320+08:00| 1.1130667107899999| |
| |1970-01-01T08:00:01.330+08:00| 1.0756000393033045| |
| |1970-01-01T08:00:01.340+08:00| 1.043200033187868| |
| |1970-01-01T08:00:01.350+08:00| 1.016666692992053| |
| |1970-01-01T08:00:01.360+08:00| 0.9968000192642223| |
| |1970-01-01T08:00:01.370+08:00| 0.9844000125527389| |
| |1970-01-01T08:00:01.380+08:00| 0.9802666734059655| |
| |1970-01-01T08:00:01.390+08:00| 0.9852000023722649| |
| |1970-01-01T08:00:01.400+08:00| 1.0| |
| |1970-01-01T08:00:01.410+08:00| 1.023999999165535| |
| |1970-01-01T08:00:01.420+08:00| 1.0559999990463256| |
| |1970-01-01T08:00:01.430+08:00| 1.0959999996423722| |
| |1970-01-01T08:00:01.440+08:00| 1.1440000009536744| |
| |1970-01-01T08:00:01.450+08:00| 1.2000000029802322| |
| |1970-01-01T08:00:01.460+08:00| 1.264000005722046| |
| |1970-01-01T08:00:01.470+08:00| 1.3360000091791153| |
| |1970-01-01T08:00:01.480+08:00| 1.4160000133514405| |
| |1970-01-01T08:00:01.490+08:00| 1.5040000182390214| |
| |1970-01-01T08:00:01.500+08:00| 1.600000023841858| |
| +-----------------------------+------------------------------------+ |
| ``` |
| |
| #### Spread |
| |
| ##### 函数简介 |
| |
| 本函数用于计算时间序列的极差,即最大值减去最小值的结果。 |
| |
| **函数名:** SPREAD |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **输出序列:** 输出单个序列,类型与输入相同,序列仅包含一个时间戳为 0 、值为极差的数据点。 |
| |
| **提示:** 数据中的空值、缺失值和`NaN`将会被忽略。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select spread(s1) from root.test.d1 where time <= 2020-01-01 00:00:30 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-----------------------+ |
| | Time|spread(root.test.d1.s1)| |
| +-----------------------------+-----------------------+ |
| |1970-01-01T08:00:00.000+08:00| 26.0| |
| +-----------------------------+-----------------------+ |
| ``` |
| |
| #### Stddev |
| |
| ##### 函数简介 |
| |
| 本函数用于计算单列数值型数据的总体标准差。 |
| |
| **函数名:** STDDEV |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE。序列仅包含一个时间戳为 0、值为总体标准差的数据点。 |
| |
| **提示:** 数据中的空值、缺失值和`NaN`将会被忽略。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:00.000+08:00| 1.0| |
| |2020-01-01T00:00:01.000+08:00| 2.0| |
| |2020-01-01T00:00:02.000+08:00| 3.0| |
| |2020-01-01T00:00:03.000+08:00| 4.0| |
| |2020-01-01T00:00:04.000+08:00| 5.0| |
| |2020-01-01T00:00:05.000+08:00| 6.0| |
| |2020-01-01T00:00:06.000+08:00| 7.0| |
| |2020-01-01T00:00:07.000+08:00| 8.0| |
| |2020-01-01T00:00:08.000+08:00| 9.0| |
| |2020-01-01T00:00:09.000+08:00| 10.0| |
| |2020-01-01T00:00:10.000+08:00| 11.0| |
| |2020-01-01T00:00:11.000+08:00| 12.0| |
| |2020-01-01T00:00:12.000+08:00| 13.0| |
| |2020-01-01T00:00:13.000+08:00| 14.0| |
| |2020-01-01T00:00:14.000+08:00| 15.0| |
| |2020-01-01T00:00:15.000+08:00| 16.0| |
| |2020-01-01T00:00:16.000+08:00| 17.0| |
| |2020-01-01T00:00:17.000+08:00| 18.0| |
| |2020-01-01T00:00:18.000+08:00| 19.0| |
| |2020-01-01T00:00:19.000+08:00| 20.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select stddev(s1) from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-----------------------+ |
| | Time|stddev(root.test.d1.s1)| |
| +-----------------------------+-----------------------+ |
| |1970-01-01T08:00:00.000+08:00| 5.7662812973353965| |
| +-----------------------------+-----------------------+ |
| ``` |
| |
| #### ZScore |
| |
| ##### 函数简介 |
| |
| 本函数将输入序列使用z-score方法进行归一化。 |
| |
| **函数名:** ZSCORE |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `compute`:若设置为 "batch",则将数据全部读入后转换;若设置为 "stream",则需用户提供均值及方差进行流式计算转换。默认为 "batch"。 |
| + `avg`:使用流式计算时的均值。 |
| + `sd`:使用流式计算时的标准差。 |
| |
| **输出序列**:输出单个序列,类型为 DOUBLE。 |
| |
| ##### 使用示例 |
| |
| ###### 全数据计算 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s1| |
| +-----------------------------+------------+ |
| |1970-01-01T08:00:00.100+08:00| 0.0| |
| |1970-01-01T08:00:00.200+08:00| 0.0| |
| |1970-01-01T08:00:00.300+08:00| 1.0| |
| |1970-01-01T08:00:00.400+08:00| -1.0| |
| |1970-01-01T08:00:00.500+08:00| 0.0| |
| |1970-01-01T08:00:00.600+08:00| 0.0| |
| |1970-01-01T08:00:00.700+08:00| -2.0| |
| |1970-01-01T08:00:00.800+08:00| 2.0| |
| |1970-01-01T08:00:00.900+08:00| 0.0| |
| |1970-01-01T08:00:01.000+08:00| 0.0| |
| |1970-01-01T08:00:01.100+08:00| 1.0| |
| |1970-01-01T08:00:01.200+08:00| -1.0| |
| |1970-01-01T08:00:01.300+08:00| -1.0| |
| |1970-01-01T08:00:01.400+08:00| 1.0| |
| |1970-01-01T08:00:01.500+08:00| 0.0| |
| |1970-01-01T08:00:01.600+08:00| 0.0| |
| |1970-01-01T08:00:01.700+08:00| 10.0| |
| |1970-01-01T08:00:01.800+08:00| 2.0| |
| |1970-01-01T08:00:01.900+08:00| -2.0| |
| |1970-01-01T08:00:02.000+08:00| 0.0| |
| +-----------------------------+------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select zscore(s1) from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------+ |
| | Time|zscore(root.test.s1)| |
| +-----------------------------+--------------------+ |
| |1970-01-01T08:00:00.100+08:00|-0.20672455764868078| |
| |1970-01-01T08:00:00.200+08:00|-0.20672455764868078| |
| |1970-01-01T08:00:00.300+08:00| 0.20672455764868078| |
| |1970-01-01T08:00:00.400+08:00| -0.6201736729460423| |
| |1970-01-01T08:00:00.500+08:00|-0.20672455764868078| |
| |1970-01-01T08:00:00.600+08:00|-0.20672455764868078| |
| |1970-01-01T08:00:00.700+08:00| -1.033622788243404| |
| |1970-01-01T08:00:00.800+08:00| 0.6201736729460423| |
| |1970-01-01T08:00:00.900+08:00|-0.20672455764868078| |
| |1970-01-01T08:00:01.000+08:00|-0.20672455764868078| |
| |1970-01-01T08:00:01.100+08:00| 0.20672455764868078| |
| |1970-01-01T08:00:01.200+08:00| -0.6201736729460423| |
| |1970-01-01T08:00:01.300+08:00| -0.6201736729460423| |
| |1970-01-01T08:00:01.400+08:00| 0.20672455764868078| |
| |1970-01-01T08:00:01.500+08:00|-0.20672455764868078| |
| |1970-01-01T08:00:01.600+08:00|-0.20672455764868078| |
| |1970-01-01T08:00:01.700+08:00| 3.9277665953249348| |
| |1970-01-01T08:00:01.800+08:00| 0.6201736729460423| |
| |1970-01-01T08:00:01.900+08:00| -1.033622788243404| |
| |1970-01-01T08:00:02.000+08:00|-0.20672455764868078| |
| +-----------------------------+--------------------+ |
| ``` |
| |
| ### 异常检测 |
| |
| #### IQR |
| |
| ##### 函数简介 |
| |
| 本函数用于检验超出上下四分位数1.5倍IQR的数据分布异常。 |
| |
| **函数名:** IQR |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `method`:若设置为 "batch",则将数据全部读入后检测;若设置为 "stream",则需用户提供上下四分位数进行流式检测。默认为 "batch"。 |
| + `q1`:使用流式计算时的下四分位数。 |
| + `q3`:使用流式计算时的上四分位数。 |
| |
| **输出序列**:输出单个序列,类型为 DOUBLE。 |
| |
| **说明**:$IQR=Q_3-Q_1$ |
| |
| ##### 使用示例 |
| |
| ###### 全数据计算 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s1| |
| +-----------------------------+------------+ |
| |1970-01-01T08:00:00.100+08:00| 0.0| |
| |1970-01-01T08:00:00.200+08:00| 0.0| |
| |1970-01-01T08:00:00.300+08:00| 1.0| |
| |1970-01-01T08:00:00.400+08:00| -1.0| |
| |1970-01-01T08:00:00.500+08:00| 0.0| |
| |1970-01-01T08:00:00.600+08:00| 0.0| |
| |1970-01-01T08:00:00.700+08:00| -2.0| |
| |1970-01-01T08:00:00.800+08:00| 2.0| |
| |1970-01-01T08:00:00.900+08:00| 0.0| |
| |1970-01-01T08:00:01.000+08:00| 0.0| |
| |1970-01-01T08:00:01.100+08:00| 1.0| |
| |1970-01-01T08:00:01.200+08:00| -1.0| |
| |1970-01-01T08:00:01.300+08:00| -1.0| |
| |1970-01-01T08:00:01.400+08:00| 1.0| |
| |1970-01-01T08:00:01.500+08:00| 0.0| |
| |1970-01-01T08:00:01.600+08:00| 0.0| |
| |1970-01-01T08:00:01.700+08:00| 10.0| |
| |1970-01-01T08:00:01.800+08:00| 2.0| |
| |1970-01-01T08:00:01.900+08:00| -2.0| |
| |1970-01-01T08:00:02.000+08:00| 0.0| |
| +-----------------------------+------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select iqr(s1) from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-----------------+ |
| | Time|iqr(root.test.s1)| |
| +-----------------------------+-----------------+ |
| |1970-01-01T08:00:01.700+08:00| 10.0| |
| +-----------------------------+-----------------+ |
| ``` |
| |
| #### KSigma |
| |
| ##### 函数简介 |
| |
| 本函数利用动态 K-Sigma 算法进行异常检测。在一个窗口内,与平均值的差距超过k倍标准差的数据将被视作异常并输出。 |
| |
| **函数名:** KSIGMA |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `k`:在动态 K-Sigma 算法中,分布异常的标准差倍数阈值,默认值为 3。 |
| + `window`:动态 K-Sigma 算法的滑动窗口大小,默认值为 10000。 |
| |
| |
| **输出序列:** 输出单个序列,类型与输入序列相同。 |
| |
| **提示:** k 应大于 0,否则将不做输出。 |
| |
| ##### 使用示例 |
| |
| ###### 指定k |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 0.0| |
| |2020-01-01T00:00:03.000+08:00| 50.0| |
| |2020-01-01T00:00:04.000+08:00| 100.0| |
| |2020-01-01T00:00:06.000+08:00| 150.0| |
| |2020-01-01T00:00:08.000+08:00| 200.0| |
| |2020-01-01T00:00:10.000+08:00| 200.0| |
| |2020-01-01T00:00:14.000+08:00| 200.0| |
| |2020-01-01T00:00:15.000+08:00| 200.0| |
| |2020-01-01T00:00:16.000+08:00| 200.0| |
| |2020-01-01T00:00:18.000+08:00| 200.0| |
| |2020-01-01T00:00:20.000+08:00| 150.0| |
| |2020-01-01T00:00:22.000+08:00| 100.0| |
| |2020-01-01T00:00:26.000+08:00| 50.0| |
| |2020-01-01T00:00:28.000+08:00| 0.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select ksigma(s1,"k"="1.0") from root.test.d1 where time <= 2020-01-01 00:00:30 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+---------------------------------+ |
| |Time |ksigma(root.test.d1.s1,"k"="3.0")| |
| +-----------------------------+---------------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 0.0| |
| |2020-01-01T00:00:03.000+08:00| 50.0| |
| |2020-01-01T00:00:26.000+08:00| 50.0| |
| |2020-01-01T00:00:28.000+08:00| 0.0| |
| +-----------------------------+---------------------------------+ |
| ``` |
| |
| #### LOF |
| |
| ##### 函数简介 |
| |
| 本函数使用局部离群点检测方法用于查找序列的密度异常。将根据提供的第k距离数及局部离群点因子(lof)阈值,判断输入数据是否为离群点,即异常,并输出各点的 LOF 值。 |
| |
| **函数名:** LOF |
| |
| **输入序列:** 多个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `method`:使用的检测方法。默认为 default,以高维数据计算。设置为 series,将一维时间序列转换为高维数据计算。 |
| + `k`:使用第k距离计算局部离群点因子.默认为 3。 |
| + `window`:每次读取数据的窗口长度。默认为 10000. |
| + `windowsize`:使用series方法时,转化高维数据的维数,即单个窗口的大小。默认为 5。 |
| |
| **输出序列:** 输出单时间序列,类型为DOUBLE。 |
| |
| **提示:** 不完整的数据行会被忽略,不参与计算,也不标记为离群点。 |
| |
| |
| ##### 使用示例 |
| |
| ###### 默认参数 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+---------------+ |
| | Time|root.test.d1.s1|root.test.d1.s2| |
| +-----------------------------+---------------+---------------+ |
| |1970-01-01T08:00:00.100+08:00| 0.0| 0.0| |
| |1970-01-01T08:00:00.200+08:00| 0.0| 1.0| |
| |1970-01-01T08:00:00.300+08:00| 1.0| 1.0| |
| |1970-01-01T08:00:00.400+08:00| 1.0| 0.0| |
| |1970-01-01T08:00:00.500+08:00| 0.0| -1.0| |
| |1970-01-01T08:00:00.600+08:00| -1.0| -1.0| |
| |1970-01-01T08:00:00.700+08:00| -1.0| 0.0| |
| |1970-01-01T08:00:00.800+08:00| 2.0| 2.0| |
| |1970-01-01T08:00:00.900+08:00| 0.0| null| |
| +-----------------------------+---------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select lof(s1,s2) from root.test.d1 where time<1000 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------------------+ |
| | Time|lof(root.test.d1.s1, root.test.d1.s2)| |
| +-----------------------------+-------------------------------------+ |
| |1970-01-01T08:00:00.100+08:00| 3.8274824267668244| |
| |1970-01-01T08:00:00.200+08:00| 3.0117631741126156| |
| |1970-01-01T08:00:00.300+08:00| 2.838155437762879| |
| |1970-01-01T08:00:00.400+08:00| 3.0117631741126156| |
| |1970-01-01T08:00:00.500+08:00| 2.73518261244453| |
| |1970-01-01T08:00:00.600+08:00| 2.371440975708148| |
| |1970-01-01T08:00:00.700+08:00| 2.73518261244453| |
| |1970-01-01T08:00:00.800+08:00| 1.7561416374270742| |
| +-----------------------------+-------------------------------------+ |
| ``` |
| |
| ###### 诊断一维时间序列 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |1970-01-01T08:00:00.100+08:00| 1.0| |
| |1970-01-01T08:00:00.200+08:00| 2.0| |
| |1970-01-01T08:00:00.300+08:00| 3.0| |
| |1970-01-01T08:00:00.400+08:00| 4.0| |
| |1970-01-01T08:00:00.500+08:00| 5.0| |
| |1970-01-01T08:00:00.600+08:00| 6.0| |
| |1970-01-01T08:00:00.700+08:00| 7.0| |
| |1970-01-01T08:00:00.800+08:00| 8.0| |
| |1970-01-01T08:00:00.900+08:00| 9.0| |
| |1970-01-01T08:00:01.000+08:00| 10.0| |
| |1970-01-01T08:00:01.100+08:00| 11.0| |
| |1970-01-01T08:00:01.200+08:00| 12.0| |
| |1970-01-01T08:00:01.300+08:00| 13.0| |
| |1970-01-01T08:00:01.400+08:00| 14.0| |
| |1970-01-01T08:00:01.500+08:00| 15.0| |
| |1970-01-01T08:00:01.600+08:00| 16.0| |
| |1970-01-01T08:00:01.700+08:00| 17.0| |
| |1970-01-01T08:00:01.800+08:00| 18.0| |
| |1970-01-01T08:00:01.900+08:00| 19.0| |
| |1970-01-01T08:00:02.000+08:00| 20.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select lof(s1, "method"="series") from root.test.d1 where time<1000 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------+ |
| | Time|lof(root.test.d1.s1)| |
| +-----------------------------+--------------------+ |
| |1970-01-01T08:00:00.100+08:00| 3.77777777777778| |
| |1970-01-01T08:00:00.200+08:00| 4.32727272727273| |
| |1970-01-01T08:00:00.300+08:00| 4.85714285714286| |
| |1970-01-01T08:00:00.400+08:00| 5.40909090909091| |
| |1970-01-01T08:00:00.500+08:00| 5.94999999999999| |
| |1970-01-01T08:00:00.600+08:00| 6.43243243243243| |
| |1970-01-01T08:00:00.700+08:00| 6.79999999999999| |
| |1970-01-01T08:00:00.800+08:00| 7.0| |
| |1970-01-01T08:00:00.900+08:00| 7.0| |
| |1970-01-01T08:00:01.000+08:00| 6.79999999999999| |
| |1970-01-01T08:00:01.100+08:00| 6.43243243243243| |
| |1970-01-01T08:00:01.200+08:00| 5.94999999999999| |
| |1970-01-01T08:00:01.300+08:00| 5.40909090909091| |
| |1970-01-01T08:00:01.400+08:00| 4.85714285714286| |
| |1970-01-01T08:00:01.500+08:00| 4.32727272727273| |
| |1970-01-01T08:00:01.600+08:00| 3.77777777777778| |
| +-----------------------------+--------------------+ |
| ``` |
| |
| #### MissDetect |
| |
| ##### 函数简介 |
| |
| 本函数用于检测数据中的缺失异常。在一些数据中,缺失数据会被线性插值填补,在数据中出现完美的线性片段,且这些片段往往长度较大。本函数通过在数据中发现这些完美线性片段来检测缺失异常。 |
| |
| **函数名:** MISSDETECT |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `minlen`:被标记为异常的完美线性片段的最小长度,是一个大于等于 10 的整数,默认值为 10。 |
| |
| **输出序列:** 输出单个序列,类型为 BOOLEAN,即该数据点是否为缺失异常。 |
| |
| **提示:** 数据中的`NaN`将会被忽略。 |
| |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d2.s2| |
| +-----------------------------+---------------+ |
| |2021-07-01T12:00:00.000+08:00| 0.0| |
| |2021-07-01T12:00:01.000+08:00| 1.0| |
| |2021-07-01T12:00:02.000+08:00| 0.0| |
| |2021-07-01T12:00:03.000+08:00| 1.0| |
| |2021-07-01T12:00:04.000+08:00| 0.0| |
| |2021-07-01T12:00:05.000+08:00| 0.0| |
| |2021-07-01T12:00:06.000+08:00| 0.0| |
| |2021-07-01T12:00:07.000+08:00| 0.0| |
| |2021-07-01T12:00:08.000+08:00| 0.0| |
| |2021-07-01T12:00:09.000+08:00| 0.0| |
| |2021-07-01T12:00:10.000+08:00| 0.0| |
| |2021-07-01T12:00:11.000+08:00| 0.0| |
| |2021-07-01T12:00:12.000+08:00| 0.0| |
| |2021-07-01T12:00:13.000+08:00| 0.0| |
| |2021-07-01T12:00:14.000+08:00| 0.0| |
| |2021-07-01T12:00:15.000+08:00| 0.0| |
| |2021-07-01T12:00:16.000+08:00| 1.0| |
| |2021-07-01T12:00:17.000+08:00| 0.0| |
| |2021-07-01T12:00:18.000+08:00| 1.0| |
| |2021-07-01T12:00:19.000+08:00| 0.0| |
| |2021-07-01T12:00:20.000+08:00| 1.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select missdetect(s2,'minlen'='10') from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------------+ |
| | Time|missdetect(root.test.d2.s2, "minlen"="10")| |
| +-----------------------------+------------------------------------------+ |
| |2021-07-01T12:00:00.000+08:00| false| |
| |2021-07-01T12:00:01.000+08:00| false| |
| |2021-07-01T12:00:02.000+08:00| false| |
| |2021-07-01T12:00:03.000+08:00| false| |
| |2021-07-01T12:00:04.000+08:00| true| |
| |2021-07-01T12:00:05.000+08:00| true| |
| |2021-07-01T12:00:06.000+08:00| true| |
| |2021-07-01T12:00:07.000+08:00| true| |
| |2021-07-01T12:00:08.000+08:00| true| |
| |2021-07-01T12:00:09.000+08:00| true| |
| |2021-07-01T12:00:10.000+08:00| true| |
| |2021-07-01T12:00:11.000+08:00| true| |
| |2021-07-01T12:00:12.000+08:00| true| |
| |2021-07-01T12:00:13.000+08:00| true| |
| |2021-07-01T12:00:14.000+08:00| true| |
| |2021-07-01T12:00:15.000+08:00| true| |
| |2021-07-01T12:00:16.000+08:00| false| |
| |2021-07-01T12:00:17.000+08:00| false| |
| |2021-07-01T12:00:18.000+08:00| false| |
| |2021-07-01T12:00:19.000+08:00| false| |
| |2021-07-01T12:00:20.000+08:00| false| |
| +-----------------------------+------------------------------------------+ |
| ``` |
| |
| #### Range |
| |
| ##### 函数简介 |
| |
| 本函数用于查找时间序列的范围异常。将根据提供的上界与下界,判断输入数据是否越界,即异常,并输出所有异常点为新的时间序列。 |
| |
| **函数名:** RANGE |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `lower_bound`:范围异常检测的下界。 |
| + `upper_bound`:范围异常检测的上界。 |
| |
| **输出序列:** 输出单个序列,类型与输入序列相同。 |
| |
| **提示:** 应满足`upper_bound`大于`lower_bound`,否则将不做输出。 |
| |
| |
| ##### 使用示例 |
| |
| ###### 指定上界与下界 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select range(s1,"lower_bound"="101.0","upper_bound"="125.0") from root.test.d1 where time <= 2020-01-01 00:00:30 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------------------------------------+ |
| |Time |range(root.test.d1.s1,"lower_bound"="101.0","upper_bound"="125.0")| |
| +-----------------------------+------------------------------------------------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| +-----------------------------+------------------------------------------------------------------+ |
| ``` |
| |
| #### TwoSidedFilter |
| |
| ##### 函数简介 |
| |
| 本函数基于双边窗口检测法对输入序列中的异常点进行过滤。 |
| |
| **函数名:** TWOSIDEDFILTER |
| |
| **输出序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **输出序列:** 输出单个序列,类型与输入相同,是输入序列去除异常点后的结果。 |
| |
| **参数:** |
| |
| - `len`:双边窗口检测法中的窗口大小,取值范围为正整数,默认值为 5.如当`len`=3 时,算法向前、向后各取长度为3的窗口,在窗口中计算异常度。 |
| - `threshold`:异常度的阈值,取值范围为(0,1),默认值为 0.3。阈值越高,函数对于异常度的判定标准越严格。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s0| |
| +-----------------------------+------------+ |
| |1970-01-01T08:00:00.000+08:00| 2002.0| |
| |1970-01-01T08:00:01.000+08:00| 1946.0| |
| |1970-01-01T08:00:02.000+08:00| 1958.0| |
| |1970-01-01T08:00:03.000+08:00| 2012.0| |
| |1970-01-01T08:00:04.000+08:00| 2051.0| |
| |1970-01-01T08:00:05.000+08:00| 1898.0| |
| |1970-01-01T08:00:06.000+08:00| 2014.0| |
| |1970-01-01T08:00:07.000+08:00| 2052.0| |
| |1970-01-01T08:00:08.000+08:00| 1935.0| |
| |1970-01-01T08:00:09.000+08:00| 1901.0| |
| |1970-01-01T08:00:10.000+08:00| 1972.0| |
| |1970-01-01T08:00:11.000+08:00| 1969.0| |
| |1970-01-01T08:00:12.000+08:00| 1984.0| |
| |1970-01-01T08:00:13.000+08:00| 2018.0| |
| |1970-01-01T08:00:37.000+08:00| 1484.0| |
| |1970-01-01T08:00:38.000+08:00| 1055.0| |
| |1970-01-01T08:00:39.000+08:00| 1050.0| |
| |1970-01-01T08:01:05.000+08:00| 1023.0| |
| |1970-01-01T08:01:06.000+08:00| 1056.0| |
| |1970-01-01T08:01:07.000+08:00| 978.0| |
| |1970-01-01T08:01:08.000+08:00| 1050.0| |
| |1970-01-01T08:01:09.000+08:00| 1123.0| |
| |1970-01-01T08:01:10.000+08:00| 1150.0| |
| |1970-01-01T08:01:11.000+08:00| 1034.0| |
| |1970-01-01T08:01:12.000+08:00| 950.0| |
| |1970-01-01T08:01:13.000+08:00| 1059.0| |
| +-----------------------------+------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select TwoSidedFilter(s0, 'len'='5', 'threshold'='0.3') from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s0| |
| +-----------------------------+------------+ |
| |1970-01-01T08:00:00.000+08:00| 2002.0| |
| |1970-01-01T08:00:01.000+08:00| 1946.0| |
| |1970-01-01T08:00:02.000+08:00| 1958.0| |
| |1970-01-01T08:00:03.000+08:00| 2012.0| |
| |1970-01-01T08:00:04.000+08:00| 2051.0| |
| |1970-01-01T08:00:05.000+08:00| 1898.0| |
| |1970-01-01T08:00:06.000+08:00| 2014.0| |
| |1970-01-01T08:00:07.000+08:00| 2052.0| |
| |1970-01-01T08:00:08.000+08:00| 1935.0| |
| |1970-01-01T08:00:09.000+08:00| 1901.0| |
| |1970-01-01T08:00:10.000+08:00| 1972.0| |
| |1970-01-01T08:00:11.000+08:00| 1969.0| |
| |1970-01-01T08:00:12.000+08:00| 1984.0| |
| |1970-01-01T08:00:13.000+08:00| 2018.0| |
| |1970-01-01T08:01:05.000+08:00| 1023.0| |
| |1970-01-01T08:01:06.000+08:00| 1056.0| |
| |1970-01-01T08:01:07.000+08:00| 978.0| |
| |1970-01-01T08:01:08.000+08:00| 1050.0| |
| |1970-01-01T08:01:09.000+08:00| 1123.0| |
| |1970-01-01T08:01:10.000+08:00| 1150.0| |
| |1970-01-01T08:01:11.000+08:00| 1034.0| |
| |1970-01-01T08:01:12.000+08:00| 950.0| |
| |1970-01-01T08:01:13.000+08:00| 1059.0| |
| +-----------------------------+------------+ |
| ``` |
| |
| #### Outlier |
| |
| ##### 函数简介 |
| |
| 本函数用于检测基于距离的异常点。在当前窗口中,如果一个点距离阈值范围内的邻居数量(包括它自己)少于密度阈值,则该点是异常点。 |
| |
| **函数名:** OUTLIER |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `r`:基于距离异常检测中的距离阈值。 |
| + `k`:基于距离异常检测中的密度阈值。 |
| + `w`:用于指定滑动窗口的大小。 |
| + `s`:用于指定滑动窗口的步长。 |
| |
| **输出序列**:输出单个序列,类型与输入序列相同。 |
| |
| ##### 使用示例 |
| |
| ###### 指定查询参数 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+ |
| | Time|root.test.s1| |
| +-----------------------------+------------+ |
| |2020-01-04T23:59:55.000+08:00| 56.0| |
| |2020-01-04T23:59:56.000+08:00| 55.1| |
| |2020-01-04T23:59:57.000+08:00| 54.2| |
| |2020-01-04T23:59:58.000+08:00| 56.3| |
| |2020-01-04T23:59:59.000+08:00| 59.0| |
| |2020-01-05T00:00:00.000+08:00| 60.0| |
| |2020-01-05T00:00:01.000+08:00| 60.5| |
| |2020-01-05T00:00:02.000+08:00| 64.5| |
| |2020-01-05T00:00:03.000+08:00| 69.0| |
| |2020-01-05T00:00:04.000+08:00| 64.2| |
| |2020-01-05T00:00:05.000+08:00| 62.3| |
| |2020-01-05T00:00:06.000+08:00| 58.0| |
| |2020-01-05T00:00:07.000+08:00| 58.9| |
| |2020-01-05T00:00:08.000+08:00| 52.0| |
| |2020-01-05T00:00:09.000+08:00| 62.3| |
| |2020-01-05T00:00:10.000+08:00| 61.0| |
| |2020-01-05T00:00:11.000+08:00| 64.2| |
| |2020-01-05T00:00:12.000+08:00| 61.8| |
| |2020-01-05T00:00:13.000+08:00| 64.0| |
| |2020-01-05T00:00:14.000+08:00| 63.0| |
| +-----------------------------+------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select outlier(s1,"r"="5.0","k"="4","w"="10","s"="5") from root.test |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------------------------------------------+ |
| | Time|outlier(root.test.s1,"r"="5.0","k"="4","w"="10","s"="5")| |
| +-----------------------------+--------------------------------------------------------+ |
| |2020-01-05T00:00:03.000+08:00| 69.0| |
| +-----------------------------+--------------------------------------------------------+ |
| |2020-01-05T00:00:08.000+08:00| 52.0| |
| +-----------------------------+--------------------------------------------------------+ |
| ``` |
| |
| ### 频域分析 |
| |
| #### Conv |
| |
| ##### 函数简介 |
| |
| 本函数对两个输入序列进行卷积,即多项式乘法。 |
| |
| |
| **函数名:** CONV |
| |
| **输入序列:** 仅支持两个输入序列,类型均为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE,它是两个序列卷积的结果。序列的时间戳从0开始,仅用于表示顺序。 |
| |
| **提示:** 输入序列中的`NaN`将被忽略。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+---------------+ |
| | Time|root.test.d2.s1|root.test.d2.s2| |
| +-----------------------------+---------------+---------------+ |
| |1970-01-01T08:00:00.000+08:00| 1.0| 7.0| |
| |1970-01-01T08:00:00.001+08:00| 0.0| 2.0| |
| |1970-01-01T08:00:00.002+08:00| 1.0| null| |
| +-----------------------------+---------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select conv(s1,s2) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------------------------+ |
| | Time|conv(root.test.d2.s1, root.test.d2.s2)| |
| +-----------------------------+--------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 7.0| |
| |1970-01-01T08:00:00.001+08:00| 2.0| |
| |1970-01-01T08:00:00.002+08:00| 7.0| |
| |1970-01-01T08:00:00.003+08:00| 2.0| |
| +-----------------------------+--------------------------------------+ |
| ``` |
| |
| #### Deconv |
| |
| ##### 函数简介 |
| |
| 本函数对两个输入序列进行去卷积,即多项式除法运算。 |
| |
| **函数名:** DECONV |
| |
| **输入序列:** 仅支持两个输入序列,类型均为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `result`:去卷积的结果,取值为'quotient'或'remainder',分别对应于去卷积的商和余数。在缺省情况下,输出去卷积的商。 |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE。它是将第二个序列从第一个序列中去卷积(第一个序列除以第二个序列)的结果。序列的时间戳从0开始,仅用于表示顺序。 |
| |
| **提示:** 输入序列中的`NaN`将被忽略。 |
| |
| ##### 使用示例 |
| |
| ###### 计算去卷积的商 |
| |
| 当`result`参数缺省或为'quotient'时,本函数计算去卷积的商。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+---------------+ |
| | Time|root.test.d2.s3|root.test.d2.s2| |
| +-----------------------------+---------------+---------------+ |
| |1970-01-01T08:00:00.000+08:00| 8.0| 7.0| |
| |1970-01-01T08:00:00.001+08:00| 2.0| 2.0| |
| |1970-01-01T08:00:00.002+08:00| 7.0| null| |
| |1970-01-01T08:00:00.003+08:00| 2.0| null| |
| +-----------------------------+---------------+---------------+ |
| ``` |
| |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select deconv(s3,s2) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+----------------------------------------+ |
| | Time|deconv(root.test.d2.s3, root.test.d2.s2)| |
| +-----------------------------+----------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 1.0| |
| |1970-01-01T08:00:00.001+08:00| 0.0| |
| |1970-01-01T08:00:00.002+08:00| 1.0| |
| +-----------------------------+----------------------------------------+ |
| ``` |
| |
| ###### 计算去卷积的余数 |
| |
| 当`result`参数为'remainder'时,本函数计算去卷积的余数。输入序列同上,用于查询的SQL语句如下: |
| |
| ```sql |
| select deconv(s3,s2,'result'='remainder') from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------------------------------------------------+ |
| | Time|deconv(root.test.d2.s3, root.test.d2.s2, "result"="remainder")| |
| +-----------------------------+--------------------------------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 1.0| |
| |1970-01-01T08:00:00.001+08:00| 0.0| |
| |1970-01-01T08:00:00.002+08:00| 0.0| |
| |1970-01-01T08:00:00.003+08:00| 0.0| |
| +-----------------------------+--------------------------------------------------------------+ |
| ``` |
| |
| #### DWT |
| |
| ##### 函数简介 |
| |
| 本函数对输入序列进行一维离散小波变换。 |
| |
| **函数名:** DWT |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `method`:小波滤波的类型,提供'Haar', 'DB4', 'DB6', 'DB8',其中DB指代Daubechies。若不设置该参数,则用户需提供小波滤波的系数。不区分大小写。 |
| + `coef`:小波滤波的系数。若提供该参数,请使用英文逗号','分割各项,不添加空格或其它符号。 |
| + `layer`:进行变换的次数,最终输出的向量个数等同于$layer+1$.默认取1。 |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE,长度与输入相等。 |
| |
| **提示:** 输入序列长度必须为2的整数次幂。 |
| |
| ##### 使用示例 |
| |
| ###### Haar变换 |
| |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.0| |
| |1970-01-01T08:00:00.100+08:00| 0.2| |
| |1970-01-01T08:00:00.200+08:00| 1.5| |
| |1970-01-01T08:00:00.300+08:00| 1.2| |
| |1970-01-01T08:00:00.400+08:00| 0.6| |
| |1970-01-01T08:00:00.500+08:00| 1.7| |
| |1970-01-01T08:00:00.600+08:00| 0.8| |
| |1970-01-01T08:00:00.700+08:00| 2.0| |
| |1970-01-01T08:00:00.800+08:00| 2.5| |
| |1970-01-01T08:00:00.900+08:00| 2.1| |
| |1970-01-01T08:00:01.000+08:00| 0.0| |
| |1970-01-01T08:00:01.100+08:00| 2.0| |
| |1970-01-01T08:00:01.200+08:00| 1.8| |
| |1970-01-01T08:00:01.300+08:00| 1.2| |
| |1970-01-01T08:00:01.400+08:00| 1.0| |
| |1970-01-01T08:00:01.500+08:00| 1.6| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select dwt(s1,"method"="haar") from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------------------+ |
| | Time|dwt(root.test.d1.s1, "method"="haar")| |
| +-----------------------------+-------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.14142135834465192| |
| |1970-01-01T08:00:00.100+08:00| 1.909188342921157| |
| |1970-01-01T08:00:00.200+08:00| 1.6263456473052773| |
| |1970-01-01T08:00:00.300+08:00| 1.9798989957517026| |
| |1970-01-01T08:00:00.400+08:00| 3.252691126023161| |
| |1970-01-01T08:00:00.500+08:00| 1.414213562373095| |
| |1970-01-01T08:00:00.600+08:00| 2.1213203435596424| |
| |1970-01-01T08:00:00.700+08:00| 1.8384776479437628| |
| |1970-01-01T08:00:00.800+08:00| -0.14142135834465192| |
| |1970-01-01T08:00:00.900+08:00| 0.21213200063848547| |
| |1970-01-01T08:00:01.000+08:00| -0.7778174761639416| |
| |1970-01-01T08:00:01.100+08:00| -0.8485281289944873| |
| |1970-01-01T08:00:01.200+08:00| 0.2828427799095765| |
| |1970-01-01T08:00:01.300+08:00| -1.414213562373095| |
| |1970-01-01T08:00:01.400+08:00| 0.42426400127697095| |
| |1970-01-01T08:00:01.500+08:00| -0.42426408557066786| |
| +-----------------------------+-------------------------------------+ |
| ``` |
| |
| #### FFT |
| |
| ##### 函数简介 |
| |
| 本函数对输入序列进行快速傅里叶变换。 |
| |
| **函数名:** FFT |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `method`:傅里叶变换的类型,取值为'uniform'或'nonuniform',缺省情况下为'uniform'。当取值为'uniform'时,时间戳将被忽略,所有数据点都将被视作等距的,并应用等距快速傅里叶算法;当取值为'nonuniform'时,将根据时间戳应用非等距快速傅里叶算法(未实现)。 |
| + `result`:傅里叶变换的结果,取值为'real'、'imag'、'abs'或'angle',分别对应于变换结果的实部、虚部、模和幅角。在缺省情况下,输出变换的模。 |
| + `compress`:压缩参数,取值范围(0,1],是有损压缩时保留的能量比例。在缺省情况下,不进行压缩。 |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE,长度与输入相等。序列的时间戳从0开始,仅用于表示顺序。 |
| |
| **提示:** 输入序列中的`NaN`将被忽略。 |
| |
| ##### 使用示例 |
| |
| ###### 等距傅里叶变换 |
| |
| 当`type`参数缺省或为'uniform'时,本函数进行等距傅里叶变换。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |1970-01-01T08:00:00.000+08:00| 2.902113| |
| |1970-01-01T08:00:01.000+08:00| 1.1755705| |
| |1970-01-01T08:00:02.000+08:00| -2.1755705| |
| |1970-01-01T08:00:03.000+08:00| -1.9021131| |
| |1970-01-01T08:00:04.000+08:00| 1.0| |
| |1970-01-01T08:00:05.000+08:00| 1.9021131| |
| |1970-01-01T08:00:06.000+08:00| 0.1755705| |
| |1970-01-01T08:00:07.000+08:00| -1.1755705| |
| |1970-01-01T08:00:08.000+08:00| -0.902113| |
| |1970-01-01T08:00:09.000+08:00| 0.0| |
| |1970-01-01T08:00:10.000+08:00| 0.902113| |
| |1970-01-01T08:00:11.000+08:00| 1.1755705| |
| |1970-01-01T08:00:12.000+08:00| -0.1755705| |
| |1970-01-01T08:00:13.000+08:00| -1.9021131| |
| |1970-01-01T08:00:14.000+08:00| -1.0| |
| |1970-01-01T08:00:15.000+08:00| 1.9021131| |
| |1970-01-01T08:00:16.000+08:00| 2.1755705| |
| |1970-01-01T08:00:17.000+08:00| -1.1755705| |
| |1970-01-01T08:00:18.000+08:00| -2.902113| |
| |1970-01-01T08:00:19.000+08:00| 0.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select fft(s1) from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+----------------------+ |
| | Time| fft(root.test.d1.s1)| |
| +-----------------------------+----------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.0| |
| |1970-01-01T08:00:00.001+08:00| 1.2727111142703152E-8| |
| |1970-01-01T08:00:00.002+08:00| 2.385520799101839E-7| |
| |1970-01-01T08:00:00.003+08:00| 8.723291723972645E-8| |
| |1970-01-01T08:00:00.004+08:00| 19.999999960195904| |
| |1970-01-01T08:00:00.005+08:00| 9.999999850988388| |
| |1970-01-01T08:00:00.006+08:00| 3.2260694930700566E-7| |
| |1970-01-01T08:00:00.007+08:00| 8.723291605373329E-8| |
| |1970-01-01T08:00:00.008+08:00| 1.108657103979944E-7| |
| |1970-01-01T08:00:00.009+08:00| 1.2727110997246171E-8| |
| |1970-01-01T08:00:00.010+08:00|1.9852334701272664E-23| |
| |1970-01-01T08:00:00.011+08:00| 1.2727111194499847E-8| |
| |1970-01-01T08:00:00.012+08:00| 1.108657103979944E-7| |
| |1970-01-01T08:00:00.013+08:00| 8.723291785769131E-8| |
| |1970-01-01T08:00:00.014+08:00| 3.226069493070057E-7| |
| |1970-01-01T08:00:00.015+08:00| 9.999999850988388| |
| |1970-01-01T08:00:00.016+08:00| 19.999999960195904| |
| |1970-01-01T08:00:00.017+08:00| 8.723291747109068E-8| |
| |1970-01-01T08:00:00.018+08:00| 2.3855207991018386E-7| |
| |1970-01-01T08:00:00.019+08:00| 1.2727112069910878E-8| |
| +-----------------------------+----------------------+ |
| ``` |
| |
| 注:输入序列服从$y=sin(2\pi t/4)+2sin(2\pi t/5)$,长度为20,因此在输出序列中$k=4$和$k=5$处有尖峰。 |
| |
| ###### 等距傅里叶变换并压缩 |
| |
| 输入序列同上,用于查询的SQL语句如下: |
| |
| ```sql |
| select fft(s1, 'result'='real', 'compress'='0.99'), fft(s1, 'result'='imag','compress'='0.99') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+----------------------+----------------------+ |
| | Time| fft(root.test.d1.s1,| fft(root.test.d1.s1,| |
| | | "result"="real",| "result"="imag",| |
| | | "compress"="0.99")| "compress"="0.99")| |
| +-----------------------------+----------------------+----------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.0| 0.0| |
| |1970-01-01T08:00:00.001+08:00| -3.932894010461041E-9| 1.2104201863039066E-8| |
| |1970-01-01T08:00:00.002+08:00|-1.4021739447490164E-7| 1.9299268669082926E-7| |
| |1970-01-01T08:00:00.003+08:00| -7.057291240286645E-8| 5.127422242345858E-8| |
| |1970-01-01T08:00:00.004+08:00| 19.021130288047125| -6.180339875198807| |
| |1970-01-01T08:00:00.005+08:00| 9.999999850988388| 3.501852745067114E-16| |
| |1970-01-01T08:00:00.019+08:00| -3.932894898639461E-9|-1.2104202549376264E-8| |
| +-----------------------------+----------------------+----------------------+ |
| ``` |
| |
| 注:基于傅里叶变换结果的共轭性质,压缩结果只保留前一半;根据给定的压缩参数,从低频到高频保留数据点,直到保留的能量比例超过该值;保留最后一个数据点以表示序列长度。 |
| |
| #### HighPass |
| |
| ##### 函数简介 |
| |
| 本函数对输入序列进行高通滤波,提取高于截止频率的分量。输入序列的时间戳将被忽略,所有数据点都将被视作等距的。 |
| |
| **函数名:** HIGHPASS |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `wpass`:归一化后的截止频率,取值为(0,1),不可缺省。 |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE,它是滤波后的序列,长度与时间戳均与输入一致。 |
| |
| **提示:** 输入序列中的`NaN`将被忽略。 |
| |
| ##### 使用示例 |
| |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |1970-01-01T08:00:00.000+08:00| 2.902113| |
| |1970-01-01T08:00:01.000+08:00| 1.1755705| |
| |1970-01-01T08:00:02.000+08:00| -2.1755705| |
| |1970-01-01T08:00:03.000+08:00| -1.9021131| |
| |1970-01-01T08:00:04.000+08:00| 1.0| |
| |1970-01-01T08:00:05.000+08:00| 1.9021131| |
| |1970-01-01T08:00:06.000+08:00| 0.1755705| |
| |1970-01-01T08:00:07.000+08:00| -1.1755705| |
| |1970-01-01T08:00:08.000+08:00| -0.902113| |
| |1970-01-01T08:00:09.000+08:00| 0.0| |
| |1970-01-01T08:00:10.000+08:00| 0.902113| |
| |1970-01-01T08:00:11.000+08:00| 1.1755705| |
| |1970-01-01T08:00:12.000+08:00| -0.1755705| |
| |1970-01-01T08:00:13.000+08:00| -1.9021131| |
| |1970-01-01T08:00:14.000+08:00| -1.0| |
| |1970-01-01T08:00:15.000+08:00| 1.9021131| |
| |1970-01-01T08:00:16.000+08:00| 2.1755705| |
| |1970-01-01T08:00:17.000+08:00| -1.1755705| |
| |1970-01-01T08:00:18.000+08:00| -2.902113| |
| |1970-01-01T08:00:19.000+08:00| 0.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select highpass(s1,'wpass'='0.45') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-----------------------------------------+ |
| | Time|highpass(root.test.d1.s1, "wpass"="0.45")| |
| +-----------------------------+-----------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.9999999534830373| |
| |1970-01-01T08:00:01.000+08:00| 1.7462829277628608E-8| |
| |1970-01-01T08:00:02.000+08:00| -0.9999999593178128| |
| |1970-01-01T08:00:03.000+08:00| -4.1115269056426626E-8| |
| |1970-01-01T08:00:04.000+08:00| 0.9999999925494194| |
| |1970-01-01T08:00:05.000+08:00| 3.328126513330016E-8| |
| |1970-01-01T08:00:06.000+08:00| -1.0000000183304454| |
| |1970-01-01T08:00:07.000+08:00| 6.260191433311374E-10| |
| |1970-01-01T08:00:08.000+08:00| 1.0000000018134796| |
| |1970-01-01T08:00:09.000+08:00| -3.097210911744423E-17| |
| |1970-01-01T08:00:10.000+08:00| -1.0000000018134794| |
| |1970-01-01T08:00:11.000+08:00| -6.260191627862097E-10| |
| |1970-01-01T08:00:12.000+08:00| 1.0000000183304454| |
| |1970-01-01T08:00:13.000+08:00| -3.328126501424346E-8| |
| |1970-01-01T08:00:14.000+08:00| -0.9999999925494196| |
| |1970-01-01T08:00:15.000+08:00| 4.111526915498874E-8| |
| |1970-01-01T08:00:16.000+08:00| 0.9999999593178128| |
| |1970-01-01T08:00:17.000+08:00| -1.7462829341296528E-8| |
| |1970-01-01T08:00:18.000+08:00| -0.9999999534830369| |
| |1970-01-01T08:00:19.000+08:00| -1.035237222742873E-16| |
| +-----------------------------+-----------------------------------------+ |
| ``` |
| |
| 注:输入序列服从$y=sin(2\pi t/4)+2sin(2\pi t/5)$,长度为20,因此高通滤波之后的输出序列服从$y=sin(2\pi t/4)$。 |
| |
| #### IFFT |
| |
| ##### 函数简介 |
| |
| 本函数将输入的两个序列作为实部和虚部视作一个复数,进行逆快速傅里叶变换,并输出结果的实部。输入数据的格式参见`FFT`函数的输出,并支持以`FFT`函数压缩后的输出作为本函数的输入。 |
| |
| **函数名:** IFFT |
| |
| **输入序列:** 仅支持两个输入序列,类型均为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `start`:输出序列的起始时刻,是一个格式为'yyyy-MM-dd HH:mm:ss'的时间字符串。在缺省情况下,为'1970-01-01 08:00:00'。 |
| + `interval`:输出序列的时间间隔,是一个有单位的正数。目前支持五种单位,分别是'ms'(毫秒)、's'(秒)、'm'(分钟)、'h'(小时)和'd'(天)。在缺省情况下,为1s。 |
| |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE。该序列是一个等距时间序列,它的值是将两个输入序列依次作为实部和虚部进行逆快速傅里叶变换的结果。 |
| |
| **提示:** 如果某行数据中包含空值或`NaN`,该行数据将会被忽略。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+----------------------+----------------------+ |
| | Time| root.test.d1.re| root.test.d1.im| |
| +-----------------------------+----------------------+----------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.0| 0.0| |
| |1970-01-01T08:00:00.001+08:00| -3.932894010461041E-9| 1.2104201863039066E-8| |
| |1970-01-01T08:00:00.002+08:00|-1.4021739447490164E-7| 1.9299268669082926E-7| |
| |1970-01-01T08:00:00.003+08:00| -7.057291240286645E-8| 5.127422242345858E-8| |
| |1970-01-01T08:00:00.004+08:00| 19.021130288047125| -6.180339875198807| |
| |1970-01-01T08:00:00.005+08:00| 9.999999850988388| 3.501852745067114E-16| |
| |1970-01-01T08:00:00.019+08:00| -3.932894898639461E-9|-1.2104202549376264E-8| |
| +-----------------------------+----------------------+----------------------+ |
| ``` |
| |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select ifft(re, im, 'interval'='1m', 'start'='2021-01-01 00:00:00') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------------------------------------+ |
| | Time|ifft(root.test.d1.re, root.test.d1.im, "interval"="1m",| |
| | | "start"="2021-01-01 00:00:00")| |
| +-----------------------------+-------------------------------------------------------+ |
| |2021-01-01T00:00:00.000+08:00| 2.902112992431231| |
| |2021-01-01T00:01:00.000+08:00| 1.1755704705132448| |
| |2021-01-01T00:02:00.000+08:00| -2.175570513757101| |
| |2021-01-01T00:03:00.000+08:00| -1.9021130389094498| |
| |2021-01-01T00:04:00.000+08:00| 0.9999999925494194| |
| |2021-01-01T00:05:00.000+08:00| 1.902113046743454| |
| |2021-01-01T00:06:00.000+08:00| 0.17557053610884188| |
| |2021-01-01T00:07:00.000+08:00| -1.1755704886020932| |
| |2021-01-01T00:08:00.000+08:00| -0.9021130371347148| |
| |2021-01-01T00:09:00.000+08:00| 3.552713678800501E-16| |
| |2021-01-01T00:10:00.000+08:00| 0.9021130371347154| |
| |2021-01-01T00:11:00.000+08:00| 1.1755704886020932| |
| |2021-01-01T00:12:00.000+08:00| -0.17557053610884144| |
| |2021-01-01T00:13:00.000+08:00| -1.902113046743454| |
| |2021-01-01T00:14:00.000+08:00| -0.9999999925494196| |
| |2021-01-01T00:15:00.000+08:00| 1.9021130389094498| |
| |2021-01-01T00:16:00.000+08:00| 2.1755705137571004| |
| |2021-01-01T00:17:00.000+08:00| -1.1755704705132448| |
| |2021-01-01T00:18:00.000+08:00| -2.902112992431231| |
| |2021-01-01T00:19:00.000+08:00| -3.552713678800501E-16| |
| +-----------------------------+-------------------------------------------------------+ |
| ``` |
| |
| #### LowPass |
| |
| ##### 函数简介 |
| |
| 本函数对输入序列进行低通滤波,提取低于截止频率的分量。输入序列的时间戳将被忽略,所有数据点都将被视作等距的。 |
| |
| **函数名:** LOWPASS |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `wpass`:归一化后的截止频率,取值为(0,1),不可缺省。 |
| |
| **输出序列:** 输出单个序列,类型为DOUBLE,它是滤波后的序列,长度与时间戳均与输入一致。 |
| |
| **提示:** 输入序列中的`NaN`将被忽略。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s1| |
| +-----------------------------+---------------+ |
| |1970-01-01T08:00:00.000+08:00| 2.902113| |
| |1970-01-01T08:00:01.000+08:00| 1.1755705| |
| |1970-01-01T08:00:02.000+08:00| -2.1755705| |
| |1970-01-01T08:00:03.000+08:00| -1.9021131| |
| |1970-01-01T08:00:04.000+08:00| 1.0| |
| |1970-01-01T08:00:05.000+08:00| 1.9021131| |
| |1970-01-01T08:00:06.000+08:00| 0.1755705| |
| |1970-01-01T08:00:07.000+08:00| -1.1755705| |
| |1970-01-01T08:00:08.000+08:00| -0.902113| |
| |1970-01-01T08:00:09.000+08:00| 0.0| |
| |1970-01-01T08:00:10.000+08:00| 0.902113| |
| |1970-01-01T08:00:11.000+08:00| 1.1755705| |
| |1970-01-01T08:00:12.000+08:00| -0.1755705| |
| |1970-01-01T08:00:13.000+08:00| -1.9021131| |
| |1970-01-01T08:00:14.000+08:00| -1.0| |
| |1970-01-01T08:00:15.000+08:00| 1.9021131| |
| |1970-01-01T08:00:16.000+08:00| 2.1755705| |
| |1970-01-01T08:00:17.000+08:00| -1.1755705| |
| |1970-01-01T08:00:18.000+08:00| -2.902113| |
| |1970-01-01T08:00:19.000+08:00| 0.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select lowpass(s1,'wpass'='0.45') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+----------------------------------------+ |
| | Time|lowpass(root.test.d1.s1, "wpass"="0.45")| |
| +-----------------------------+----------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 1.9021130073323922| |
| |1970-01-01T08:00:01.000+08:00| 1.1755704705132448| |
| |1970-01-01T08:00:02.000+08:00| -1.1755705286582614| |
| |1970-01-01T08:00:03.000+08:00| -1.9021130389094498| |
| |1970-01-01T08:00:04.000+08:00| 7.450580419288145E-9| |
| |1970-01-01T08:00:05.000+08:00| 1.902113046743454| |
| |1970-01-01T08:00:06.000+08:00| 1.1755705212076808| |
| |1970-01-01T08:00:07.000+08:00| -1.1755704886020932| |
| |1970-01-01T08:00:08.000+08:00| -1.9021130222335536| |
| |1970-01-01T08:00:09.000+08:00| 3.552713678800501E-16| |
| |1970-01-01T08:00:10.000+08:00| 1.9021130222335536| |
| |1970-01-01T08:00:11.000+08:00| 1.1755704886020932| |
| |1970-01-01T08:00:12.000+08:00| -1.1755705212076801| |
| |1970-01-01T08:00:13.000+08:00| -1.902113046743454| |
| |1970-01-01T08:00:14.000+08:00| -7.45058112983088E-9| |
| |1970-01-01T08:00:15.000+08:00| 1.9021130389094498| |
| |1970-01-01T08:00:16.000+08:00| 1.1755705286582616| |
| |1970-01-01T08:00:17.000+08:00| -1.1755704705132448| |
| |1970-01-01T08:00:18.000+08:00| -1.9021130073323924| |
| |1970-01-01T08:00:19.000+08:00| -2.664535259100376E-16| |
| +-----------------------------+----------------------------------------+ |
| ``` |
| |
| 注:输入序列服从$y=sin(2\pi t/4)+2sin(2\pi t/5)$,长度为20,因此低通滤波之后的输出序列服从$y=2sin(2\pi t/5)$。 |
| |
| ### 数据匹配 |
| |
| #### Cov |
| |
| ##### 函数简介 |
| |
| 本函数用于计算两列数值型数据的总体协方差。 |
| |
| **函数名:** COV |
| |
| **输入序列:** 仅支持两个输入序列,类型均为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE。序列仅包含一个时间戳为 0、值为总体协方差的数据点。 |
| |
| **提示:** |
| |
| + 如果某行数据中包含空值、缺失值或`NaN`,该行数据将会被忽略; |
| + 如果数据中所有的行都被忽略,函数将会输出`NaN`。 |
| |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+---------------+ |
| | Time|root.test.d2.s1|root.test.d2.s2| |
| +-----------------------------+---------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| 101.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| null| |
| |2020-01-01T00:00:04.000+08:00| 102.0| 101.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| 102.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| 102.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| 103.0| |
| |2020-01-01T00:00:12.000+08:00| null| 103.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| 104.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| null| |
| |2020-01-01T00:00:16.000+08:00| 114.0| 104.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| 105.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| 105.0| |
| |2020-01-01T00:00:22.000+08:00| 100.0| 106.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| 108.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| 108.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| 108.0| |
| +-----------------------------+---------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select cov(s1,s2) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------------------+ |
| | Time|cov(root.test.d2.s1, root.test.d2.s2)| |
| +-----------------------------+-------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 12.291666666666666| |
| +-----------------------------+-------------------------------------+ |
| ``` |
| |
| #### Dtw |
| |
| ##### 函数简介 |
| |
| 本函数用于计算两列数值型数据的 DTW 距离。 |
| |
| **函数名:** DTW |
| |
| **输入序列:** 仅支持两个输入序列,类型均为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE。序列仅包含一个时间戳为 0、值为两个时间序列的 DTW 距离值。 |
| |
| **提示:** |
| |
| + 如果某行数据中包含空值、缺失值或`NaN`,该行数据将会被忽略; |
| + 如果数据中所有的行都被忽略,函数将会输出 0。 |
| |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+---------------+ |
| | Time|root.test.d2.s1|root.test.d2.s2| |
| +-----------------------------+---------------+---------------+ |
| |1970-01-01T08:00:00.001+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.002+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.003+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.004+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.005+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.006+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.007+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.008+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.009+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.010+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.011+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.012+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.013+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.014+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.015+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.016+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.017+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.018+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.019+08:00| 1.0| 2.0| |
| |1970-01-01T08:00:00.020+08:00| 1.0| 2.0| |
| +-----------------------------+---------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select dtw(s1,s2) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------------------+ |
| | Time|dtw(root.test.d2.s1, root.test.d2.s2)| |
| +-----------------------------+-------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 20.0| |
| +-----------------------------+-------------------------------------+ |
| ``` |
| |
| #### Pearson |
| |
| ##### 函数简介 |
| |
| 本函数用于计算两列数值型数据的皮尔森相关系数。 |
| |
| **函数名:** PEARSON |
| |
| **输入序列:** 仅支持两个输入序列,类型均为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE。序列仅包含一个时间戳为 0、值为皮尔森相关系数的数据点。 |
| |
| **提示:** |
| |
| + 如果某行数据中包含空值、缺失值或`NaN`,该行数据将会被忽略; |
| + 如果数据中所有的行都被忽略,函数将会输出`NaN`。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+---------------+ |
| | Time|root.test.d2.s1|root.test.d2.s2| |
| +-----------------------------+---------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| 101.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| null| |
| |2020-01-01T00:00:04.000+08:00| 102.0| 101.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| 102.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| 102.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| 103.0| |
| |2020-01-01T00:00:12.000+08:00| null| 103.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| 104.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| null| |
| |2020-01-01T00:00:16.000+08:00| 114.0| 104.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| 105.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| 105.0| |
| |2020-01-01T00:00:22.000+08:00| 100.0| 106.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| 108.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| 108.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| 108.0| |
| +-----------------------------+---------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select pearson(s1,s2) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-----------------------------------------+ |
| | Time|pearson(root.test.d2.s1, root.test.d2.s2)| |
| +-----------------------------+-----------------------------------------+ |
| |1970-01-01T08:00:00.000+08:00| 0.5630881927754872| |
| +-----------------------------+-----------------------------------------+ |
| ``` |
| |
| #### PtnSym |
| |
| ##### 函数简介 |
| |
| 本函数用于寻找序列中所有对称度小于阈值的对称子序列。对称度通过 DTW 计算,值越小代表序列对称性越高。 |
| |
| **函数名:** PTNSYM |
| |
| **输入序列:** 仅支持一个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `window`:对称子序列的长度,是一个正整数,默认值为 10。 |
| + `threshold`:对称度阈值,是一个非负数,只有对称度小于等于该值的对称子序列才会被输出。在缺省情况下,所有的子序列都会被输出。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE。序列中的每一个数据点对应于一个对称子序列,时间戳为子序列的起始时刻,值为对称度。 |
| |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d1.s4| |
| +-----------------------------+---------------+ |
| |2021-01-01T12:00:00.000+08:00| 1.0| |
| |2021-01-01T12:00:01.000+08:00| 2.0| |
| |2021-01-01T12:00:02.000+08:00| 3.0| |
| |2021-01-01T12:00:03.000+08:00| 2.0| |
| |2021-01-01T12:00:04.000+08:00| 1.0| |
| |2021-01-01T12:00:05.000+08:00| 1.0| |
| |2021-01-01T12:00:06.000+08:00| 1.0| |
| |2021-01-01T12:00:07.000+08:00| 1.0| |
| |2021-01-01T12:00:08.000+08:00| 2.0| |
| |2021-01-01T12:00:09.000+08:00| 3.0| |
| |2021-01-01T12:00:10.000+08:00| 2.0| |
| |2021-01-01T12:00:11.000+08:00| 1.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select ptnsym(s4, 'window'='5', 'threshold'='0') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------------------------+ |
| | Time|ptnsym(root.test.d1.s4, "window"="5", "threshold"="0")| |
| +-----------------------------+------------------------------------------------------+ |
| |2021-01-01T12:00:00.000+08:00| 0.0| |
| |2021-01-01T12:00:07.000+08:00| 0.0| |
| +-----------------------------+------------------------------------------------------+ |
| ``` |
| |
| #### XCorr |
| |
| ##### 函数简介 |
| |
| 本函数用于计算两条时间序列的互相关函数值, |
| 对离散序列而言,互相关函数可以表示为 |
| $$CR(n) = \frac{1}{N} \sum_{m=1}^N S_1[m]S_2[m+n]$$ |
| 常用于表征两条序列在不同对齐条件下的相似度。 |
| |
| **函数名:** XCORR |
| |
| **输入序列:** 仅支持两个输入序列,类型均为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **输出序列:** 输出单个序列,类型为 DOUBLE。序列中共包含$2N-1$个数据点, |
| 其中正中心的值为两条序列按照预先对齐的结果计算的互相关系数(即等于以上公式的$CR(0)$), |
| 前半部分的值表示将后一条输入序列向前平移时计算的互相关系数, |
| 直至两条序列没有重合的数据点(不包含完全分离时的结果$CR(-N)=0.0$), |
| 后半部分类似。 |
| 用公式可表示为(所有序列的索引从1开始计数): |
| $$OS[i] = CR(-N+i) = \frac{1}{N} \sum_{m=1}^{i} S_1[m]S_2[N-i+m],\ if\ i <= N$$ |
| $$OS[i] = CR(i-N) = \frac{1}{N} \sum_{m=1}^{2N-i} S_1[i-N+m]S_2[m],\ if\ i > N$$ |
| |
| **提示:** |
| |
| + 两条序列中的`null` 和`NaN` 值会被忽略,在计算中表现为 0。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+---------------+ |
| | Time|root.test.d1.s1|root.test.d1.s2| |
| +-----------------------------+---------------+---------------+ |
| |2020-01-01T00:00:01.000+08:00| null| 6| |
| |2020-01-01T00:00:02.000+08:00| 2| 7| |
| |2020-01-01T00:00:03.000+08:00| 3| NaN| |
| |2020-01-01T00:00:04.000+08:00| 4| 9| |
| |2020-01-01T00:00:05.000+08:00| 5| 10| |
| +-----------------------------+---------------+---------------+ |
| ``` |
| |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select xcorr(s1, s2) from root.test.d1 where time <= 2020-01-01 00:00:05 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+---------------------------------------+ |
| | Time|xcorr(root.test.d1.s1, root.test.d1.s2)| |
| +-----------------------------+---------------------------------------+ |
| |1970-01-01T08:00:00.001+08:00| 0.0| |
| |1970-01-01T08:00:00.002+08:00| 4.0| |
| |1970-01-01T08:00:00.003+08:00| 9.6| |
| |1970-01-01T08:00:00.004+08:00| 13.4| |
| |1970-01-01T08:00:00.005+08:00| 20.0| |
| |1970-01-01T08:00:00.006+08:00| 15.6| |
| |1970-01-01T08:00:00.007+08:00| 9.2| |
| |1970-01-01T08:00:00.008+08:00| 11.8| |
| |1970-01-01T08:00:00.009+08:00| 6.0| |
| +-----------------------------+---------------------------------------+ |
| ``` |
| |
| ### 数据修复 |
| |
| #### TimestampRepair |
| |
| ##### 函数简介 |
| |
| 本函数用于时间戳修复。根据给定的标准时间间隔,采用最小化修复代价的方法,通过对数据时间戳的微调,将原本时间戳间隔不稳定的数据修复为严格等间隔的数据。在未给定标准时间间隔的情况下,本函数将使用时间间隔的中位数 (median)、众数 (mode) 或聚类中心 (cluster) 来推算标准时间间隔。 |
| |
| |
| **函数名:** TIMESTAMPREPAIR |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `interval`: 标准时间间隔(单位是毫秒),是一个正整数。在缺省情况下,将根据指定的方法推算。 |
| + `method`:推算标准时间间隔的方法,取值为 'median', 'mode' 或 'cluster',仅在`interval`缺省时有效。在缺省情况下,将使用中位数方法进行推算。 |
| |
| **输出序列:** 输出单个序列,类型与输入序列相同。该序列是修复后的输入序列。 |
| |
| ##### 使用示例 |
| |
| ###### 指定标准时间间隔 |
| |
| 在给定`interval`参数的情况下,本函数将按照指定的标准时间间隔进行修复。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d2.s1| |
| +-----------------------------+---------------+ |
| |2021-07-01T12:00:00.000+08:00| 1.0| |
| |2021-07-01T12:00:10.000+08:00| 2.0| |
| |2021-07-01T12:00:19.000+08:00| 3.0| |
| |2021-07-01T12:00:30.000+08:00| 4.0| |
| |2021-07-01T12:00:40.000+08:00| 5.0| |
| |2021-07-01T12:00:50.000+08:00| 6.0| |
| |2021-07-01T12:01:01.000+08:00| 7.0| |
| |2021-07-01T12:01:11.000+08:00| 8.0| |
| |2021-07-01T12:01:21.000+08:00| 9.0| |
| |2021-07-01T12:01:31.000+08:00| 10.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select timestamprepair(s1,'interval'='10000') from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+----------------------------------------------------+ |
| | Time|timestamprepair(root.test.d2.s1, "interval"="10000")| |
| +-----------------------------+----------------------------------------------------+ |
| |2021-07-01T12:00:00.000+08:00| 1.0| |
| |2021-07-01T12:00:10.000+08:00| 2.0| |
| |2021-07-01T12:00:20.000+08:00| 3.0| |
| |2021-07-01T12:00:30.000+08:00| 4.0| |
| |2021-07-01T12:00:40.000+08:00| 5.0| |
| |2021-07-01T12:00:50.000+08:00| 6.0| |
| |2021-07-01T12:01:00.000+08:00| 7.0| |
| |2021-07-01T12:01:10.000+08:00| 8.0| |
| |2021-07-01T12:01:20.000+08:00| 9.0| |
| |2021-07-01T12:01:30.000+08:00| 10.0| |
| +-----------------------------+----------------------------------------------------+ |
| ``` |
| |
| ###### 自动推算标准时间间隔 |
| |
| 如果`interval`参数没有给定,本函数将按照推算的标准时间间隔进行修复。 |
| |
| 输入序列同上,用于查询的 SQL 语句如下: |
| |
| ```sql |
| select timestamprepair(s1) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------------------+ |
| | Time|timestamprepair(root.test.d2.s1)| |
| +-----------------------------+--------------------------------+ |
| |2021-07-01T12:00:00.000+08:00| 1.0| |
| |2021-07-01T12:00:10.000+08:00| 2.0| |
| |2021-07-01T12:00:20.000+08:00| 3.0| |
| |2021-07-01T12:00:30.000+08:00| 4.0| |
| |2021-07-01T12:00:40.000+08:00| 5.0| |
| |2021-07-01T12:00:50.000+08:00| 6.0| |
| |2021-07-01T12:01:00.000+08:00| 7.0| |
| |2021-07-01T12:01:10.000+08:00| 8.0| |
| |2021-07-01T12:01:20.000+08:00| 9.0| |
| |2021-07-01T12:01:30.000+08:00| 10.0| |
| +-----------------------------+--------------------------------+ |
| ``` |
| |
| #### ValueFill |
| |
| ##### 函数简介 |
| |
| **函数名:** ValueFill |
| |
| **输入序列:** 单列时序数据,类型为INT32 / INT64 / FLOAT / DOUBLE |
| |
| **参数:** |
| |
| + `method`: {"mean", "previous", "linear", "likelihood", "AR", "MA", "SCREEN"}, 默认为 "linear"。其中,“mean” 指使用均值填补的方法; “previous" 指使用前值填补方法;“linear" 指使用线性插值填补方法;“likelihood” 为基于速度的正态分布的极大似然估计方法;“AR” 指自回归的填补方法;“MA” 指滑动平均的填补方法;"SCREEN" 指约束填补方法;缺省情况下使用 “linear”。 |
| |
| **输出序列:** 填补后的单维序列。 |
| |
| **备注:** AR 模型采用 AR(1),时序列需满足自相关条件,否则将输出单个数据点 (0, 0.0). |
| |
| ##### 使用示例 |
| ###### 使用 linear 方法进行填补 |
| |
| 当`method`缺省或取值为 'linear' 时,本函数将使用线性插值方法进行填补。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d2.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| NaN| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| NaN| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| NaN| |
| |2020-01-01T00:00:22.000+08:00| NaN| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| 128.0| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select valuefill(s1) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| |
| |
| ``` |
| +-----------------------------+-----------------------+ |
| | Time|valuefill(root.test.d2)| |
| +-----------------------------+-----------------------+ |
| |2020-01-01T00:00:02.000+08:00| NaN| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 108.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.7| |
| |2020-01-01T00:00:22.000+08:00| 121.3| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| 128.0| |
| +-----------------------------+-----------------------+ |
| ``` |
| |
| ###### 使用 previous 方法进行填补 |
| |
| 当`method`取值为 'previous' 时,本函数将使前值填补方法进行数值填补。 |
| |
| 输入序列同上,用于查询的 SQL 语句如下: |
| |
| ```sql |
| select valuefill(s1,"method"="previous") from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------------------------+ |
| | Time|valuefill(root.test.d2,"method"="previous")| |
| +-----------------------------+-------------------------------------------+ |
| |2020-01-01T00:00:02.000+08:00| NaN| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 110.5| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 116.0| |
| |2020-01-01T00:00:22.000+08:00| 116.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| 128.0| |
| +-----------------------------+-------------------------------------------+ |
| ``` |
| |
| #### ValueRepair |
| |
| ##### 函数简介 |
| |
| 本函数用于对时间序列的数值进行修复。目前,本函数支持两种修复方法:**Screen** 是一种基于速度阈值的方法,在最小改动的前提下使得所有的速度符合阈值要求;**LsGreedy** 是一种基于速度变化似然的方法,将速度变化建模为高斯分布,并采用贪心算法极大化似然函数。 |
| |
| **函数名:** VALUEREPAIR |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `method`:修复时采用的方法,取值为 'Screen' 或 'LsGreedy'. 在缺省情况下,使用 Screen 方法进行修复。 |
| + `minSpeed`:该参数仅在使用 Screen 方法时有效。当速度小于该值时会被视作数值异常点加以修复。在缺省情况下为中位数减去三倍绝对中位差。 |
| + `maxSpeed`:该参数仅在使用 Screen 方法时有效。当速度大于该值时会被视作数值异常点加以修复。在缺省情况下为中位数加上三倍绝对中位差。 |
| + `center`:该参数仅在使用 LsGreedy 方法时有效。对速度变化分布建立的高斯模型的中心。在缺省情况下为 0。 |
| + `sigma` :该参数仅在使用 LsGreedy 方法时有效。对速度变化分布建立的高斯模型的标准差。在缺省情况下为绝对中位差。 |
| |
| **输出序列:** 输出单个序列,类型与输入序列相同。该序列是修复后的输入序列。 |
| |
| **提示:** 输入序列中的`NaN`在修复之前会先进行线性插值填补。 |
| |
| ##### 使用示例 |
| |
| ###### 使用 Screen 方法进行修复 |
| |
| 当`method`缺省或取值为 'Screen' 时,本函数将使用 Screen 方法进行数值修复。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d2.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 126.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 100.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| NaN| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select valuerepair(s1) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+----------------------------+ |
| | Time|valuerepair(root.test.d2.s1)| |
| +-----------------------------+----------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 106.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| 128.0| |
| +-----------------------------+----------------------------+ |
| ``` |
| |
| ###### 使用 LsGreedy 方法进行修复 |
| |
| 当`method`取值为 'LsGreedy' 时,本函数将使用 LsGreedy 方法进行数值修复。 |
| |
| 输入序列同上,用于查询的 SQL 语句如下: |
| |
| ```sql |
| select valuerepair(s1,'method'='LsGreedy') from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------------------------------+ |
| | Time|valuerepair(root.test.d2.s1, "method"="LsGreedy")| |
| +-----------------------------+-------------------------------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:03.000+08:00| 101.0| |
| |2020-01-01T00:00:04.000+08:00| 102.0| |
| |2020-01-01T00:00:06.000+08:00| 104.0| |
| |2020-01-01T00:00:08.000+08:00| 106.0| |
| |2020-01-01T00:00:10.000+08:00| 108.0| |
| |2020-01-01T00:00:14.000+08:00| 112.0| |
| |2020-01-01T00:00:15.000+08:00| 113.0| |
| |2020-01-01T00:00:16.000+08:00| 114.0| |
| |2020-01-01T00:00:18.000+08:00| 116.0| |
| |2020-01-01T00:00:20.000+08:00| 118.0| |
| |2020-01-01T00:00:22.000+08:00| 120.0| |
| |2020-01-01T00:00:26.000+08:00| 124.0| |
| |2020-01-01T00:00:28.000+08:00| 126.0| |
| |2020-01-01T00:00:30.000+08:00| 128.0| |
| +-----------------------------+-------------------------------------------------+ |
| ``` |
| |
| #### MasterRepair |
| |
| ##### 函数简介 |
| |
| 本函数实现基于主数据的时间序列数据修复。 |
| |
| **函数名:**MasterRepair |
| |
| **输入序列:** 支持多个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| - `omega`:算法窗口大小,非负整数(单位为毫秒), 在缺省情况下,算法根据不同时间差下的两个元组距离自动估计该参数。 |
| - `eta`:算法距离阈值,正数, 在缺省情况下,算法根据窗口中元组的距离分布自动估计该参数。 |
| - `k`:主数据中的近邻数量,正整数, 在缺省情况下,算法根据主数据中的k个近邻的元组距离自动估计该参数。 |
| - `output_column`:输出列的序号,默认输出第一列的修复结果。 |
| |
| **输出序列:**输出单个序列,类型与输入数据中对应列的类型相同,序列为输入列修复后的结果。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+------------+------------+------------+------------+------------+------------+ |
| | Time|root.test.t1|root.test.t2|root.test.t3|root.test.m1|root.test.m2|root.test.m3| |
| +-----------------------------+------------+------------+------------+------------+------------+------------+ |
| |2021-07-01T12:00:01.000+08:00| 1704| 1154.55| 0.195| 1704| 1154.55| 0.195| |
| |2021-07-01T12:00:02.000+08:00| 1702| 1152.30| 0.193| 1702| 1152.30| 0.193| |
| |2021-07-01T12:00:03.000+08:00| 1702| 1148.65| 0.192| 1702| 1148.65| 0.192| |
| |2021-07-01T12:00:04.000+08:00| 1701| 1145.20| 0.194| 1701| 1145.20| 0.194| |
| |2021-07-01T12:00:07.000+08:00| 1703| 1150.55| 0.195| 1703| 1150.55| 0.195| |
| |2021-07-01T12:00:08.000+08:00| 1694| 1151.55| 0.193| 1704| 1151.55| 0.193| |
| |2021-07-01T12:01:09.000+08:00| 1705| 1153.55| 0.194| 1705| 1153.55| 0.194| |
| |2021-07-01T12:01:10.000+08:00| 1706| 1152.30| 0.190| 1706| 1152.30| 0.190| |
| +-----------------------------+------------+------------+------------+------------+------------+------------+ |
| ``` |
| |
| 用于查询的 SQL 语句: |
| |
| ```sql |
| select MasterRepair(t1,t2,t3,m1,m2,m3) from root.test |
| ``` |
| |
| 输出序列: |
| |
| |
| ``` |
| +-----------------------------+-------------------------------------------------------------------------------------------+ |
| | Time|MasterRepair(root.test.t1,root.test.t2,root.test.t3,root.test.m1,root.test.m2,root.test.m3)| |
| +-----------------------------+-------------------------------------------------------------------------------------------+ |
| |2021-07-01T12:00:01.000+08:00| 1704| |
| |2021-07-01T12:00:02.000+08:00| 1702| |
| |2021-07-01T12:00:03.000+08:00| 1702| |
| |2021-07-01T12:00:04.000+08:00| 1701| |
| |2021-07-01T12:00:07.000+08:00| 1703| |
| |2021-07-01T12:00:08.000+08:00| 1704| |
| |2021-07-01T12:01:09.000+08:00| 1705| |
| |2021-07-01T12:01:10.000+08:00| 1706| |
| +-----------------------------+-------------------------------------------------------------------------------------------+ |
| ``` |
| |
| #### SeasonalRepair |
| |
| ##### 函数简介 |
| 本函数用于对周期性时间序列的数值进行基于分解的修复。目前,本函数支持两种方法:**Classical**使用经典分解方法得到的残差项检测数值的异常波动,并使用滑动平均修复序列;**Improved**使用改进的分解方法得到的残差项检测数值的异常波动,并使用滑动中值修复序列。 |
| |
| **函数名:** SEASONALREPAIR |
| |
| **输入序列:** 仅支持单个输入序列,类型为 INT32 / INT64 / FLOAT / DOUBLE。 |
| |
| **参数:** |
| |
| + `method`:修复时采用的分解方法,取值为'Classical'或'Improved'。在缺省情况下,使用经典分解方法进行修复。 |
| + `period`:序列的周期。 |
| + `k`:残差项的范围阈值,用来限制残差项偏离中心的程度。在缺省情况下为9。 |
| + `max_iter`:算法的最大迭代次数。在缺省情况下为10。 |
| |
| **输出序列:** 输出单个序列,类型与输入序列相同。该序列是修复后的输入序列。 |
| |
| **提示:** 输入序列中的`NaN`在修复之前会先进行线性插值填补。 |
| |
| ##### 使用示例 |
| ###### 使用经典分解方法进行修复 |
| 当`method`缺省或取值为'Classical'时,本函数将使用经典分解方法进行数值修复。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+ |
| | Time|root.test.d2.s1| |
| +-----------------------------+---------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:04.000+08:00| 120.0| |
| |2020-01-01T00:00:06.000+08:00| 80.0| |
| |2020-01-01T00:00:08.000+08:00| 100.5| |
| |2020-01-01T00:00:10.000+08:00| 119.5| |
| |2020-01-01T00:00:12.000+08:00| 101.0| |
| |2020-01-01T00:00:14.000+08:00| 99.5| |
| |2020-01-01T00:00:16.000+08:00| 119.0| |
| |2020-01-01T00:00:18.000+08:00| 80.5| |
| |2020-01-01T00:00:20.000+08:00| 99.0| |
| |2020-01-01T00:00:22.000+08:00| 121.0| |
| |2020-01-01T00:00:24.000+08:00| 79.5| |
| +-----------------------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select seasonalrepair(s1,'period'=3,'k'=2) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------------------------------------+ |
| | Time|seasonalrepair(root.test.d2.s1, 'period'=4, 'k'=2)| |
| +-----------------------------+--------------------------------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:04.000+08:00| 120.0| |
| |2020-01-01T00:00:06.000+08:00| 80.0| |
| |2020-01-01T00:00:08.000+08:00| 100.5| |
| |2020-01-01T00:00:10.000+08:00| 119.5| |
| |2020-01-01T00:00:12.000+08:00| 87.0| |
| |2020-01-01T00:00:14.000+08:00| 99.5| |
| |2020-01-01T00:00:16.000+08:00| 119.0| |
| |2020-01-01T00:00:18.000+08:00| 80.5| |
| |2020-01-01T00:00:20.000+08:00| 99.0| |
| |2020-01-01T00:00:22.000+08:00| 121.0| |
| |2020-01-01T00:00:24.000+08:00| 79.5| |
| +-----------------------------+--------------------------------------------------+ |
| ``` |
| |
| ###### 使用改进的分解方法进行修复 |
| 当`method`取值为'Improved'时,本函数将使用改进的分解方法进行数值修复。 |
| |
| 输入序列同上,用于查询的SQL语句如下: |
| |
| ```sql |
| select seasonalrepair(s1,'method'='improved','period'=3) from root.test.d2 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+-------------------------------------------------------------+ |
| | Time|valuerepair(root.test.d2.s1, 'method'='improved', 'period'=3)| |
| +-----------------------------+-------------------------------------------------------------+ |
| |2020-01-01T00:00:02.000+08:00| 100.0| |
| |2020-01-01T00:00:04.000+08:00| 120.0| |
| |2020-01-01T00:00:06.000+08:00| 80.0| |
| |2020-01-01T00:00:08.000+08:00| 100.5| |
| |2020-01-01T00:00:10.000+08:00| 119.5| |
| |2020-01-01T00:00:12.000+08:00| 81.5| |
| |2020-01-01T00:00:14.000+08:00| 99.5| |
| |2020-01-01T00:00:16.000+08:00| 119.0| |
| |2020-01-01T00:00:18.000+08:00| 80.5| |
| |2020-01-01T00:00:20.000+08:00| 99.0| |
| |2020-01-01T00:00:22.000+08:00| 121.0| |
| |2020-01-01T00:00:24.000+08:00| 79.5| |
| +-----------------------------+-------------------------------------------------------------+ |
| ``` |
| |
| ### 序列发现 |
| |
| #### ConsecutiveSequences |
| |
| ##### 函数简介 |
| |
| 本函数用于在多维严格等间隔数据中发现局部最长连续子序列。 |
| |
| 严格等间隔数据是指数据的时间间隔是严格相等的,允许存在数据缺失(包括行缺失和值缺失),但不允许存在数据冗余和时间戳偏移。 |
| |
| 连续子序列是指严格按照标准时间间隔等距排布,不存在任何数据缺失的子序列。如果某个连续子序列不是任何连续子序列的真子序列,那么它是局部最长的。 |
| |
| |
| **函数名:** CONSECUTIVESEQUENCES |
| |
| **输入序列:** 支持多个输入序列,类型可以是任意的,但要满足严格等间隔的要求。 |
| |
| **参数:** |
| |
| + `gap`:标准时间间隔,是一个有单位的正数。目前支持五种单位,分别是'ms'(毫秒)、's'(秒)、'm'(分钟)、'h'(小时)和'd'(天)。在缺省情况下,函数会利用众数估计标准时间间隔。 |
| |
| **输出序列:** 输出单个序列,类型为 INT32。输出序列中的每一个数据点对应一个局部最长连续子序列,时间戳为子序列的起始时刻,值为子序列包含的数据点个数。 |
| |
| **提示:** 对于不符合要求的输入,本函数不对输出做任何保证。 |
| |
| ##### 使用示例 |
| |
| ###### 手动指定标准时间间隔 |
| |
| 本函数可以通过`gap`参数手动指定标准时间间隔。需要注意的是,错误的参数设置会导致输出产生严重错误。 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+---------------+ |
| | Time|root.test.d1.s1|root.test.d1.s2| |
| +-----------------------------+---------------+---------------+ |
| |2020-01-01T00:00:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:05:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:10:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:20:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:25:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:30:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:35:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:40:00.000+08:00| 1.0| null| |
| |2020-01-01T00:45:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:50:00.000+08:00| 1.0| 1.0| |
| +-----------------------------+---------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select consecutivesequences(s1,s2,'gap'='5m') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------------------------------------+ |
| | Time|consecutivesequences(root.test.d1.s1, root.test.d1.s2, "gap"="5m")| |
| +-----------------------------+------------------------------------------------------------------+ |
| |2020-01-01T00:00:00.000+08:00| 3| |
| |2020-01-01T00:20:00.000+08:00| 4| |
| |2020-01-01T00:45:00.000+08:00| 2| |
| +-----------------------------+------------------------------------------------------------------+ |
| ``` |
| |
| ###### 自动估计标准时间间隔 |
| |
| 当`gap`参数缺省时,本函数可以利用众数估计标准时间间隔,得到同样的结果。因此,这种用法更受推荐。 |
| |
| 输入序列同上,用于查询的SQL语句如下: |
| |
| ```sql |
| select consecutivesequences(s1,s2) from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+------------------------------------------------------+ |
| | Time|consecutivesequences(root.test.d1.s1, root.test.d1.s2)| |
| +-----------------------------+------------------------------------------------------+ |
| |2020-01-01T00:00:00.000+08:00| 3| |
| |2020-01-01T00:20:00.000+08:00| 4| |
| |2020-01-01T00:45:00.000+08:00| 2| |
| +-----------------------------+------------------------------------------------------+ |
| ``` |
| |
| #### ConsecutiveWindows |
| |
| ##### 函数简介 |
| |
| 本函数用于在多维严格等间隔数据中发现指定长度的连续窗口。 |
| |
| 严格等间隔数据是指数据的时间间隔是严格相等的,允许存在数据缺失(包括行缺失和值缺失),但不允许存在数据冗余和时间戳偏移。 |
| |
| 连续窗口是指严格按照标准时间间隔等距排布,不存在任何数据缺失的子序列。 |
| |
| |
| **函数名:** CONSECUTIVEWINDOWS |
| |
| **输入序列:** 支持多个输入序列,类型可以是任意的,但要满足严格等间隔的要求。 |
| |
| **参数:** |
| |
| + `gap`:标准时间间隔,是一个有单位的正数。目前支持五种单位,分别是 'ms'(毫秒)、's'(秒)、'm'(分钟)、'h'(小时)和'd'(天)。在缺省情况下,函数会利用众数估计标准时间间隔。 |
| + `length`:序列长度,是一个有单位的正数。目前支持五种单位,分别是 'ms'(毫秒)、's'(秒)、'm'(分钟)、'h'(小时)和'd'(天)。该参数不允许缺省。 |
| |
| **输出序列:** 输出单个序列,类型为 INT32。输出序列中的每一个数据点对应一个指定长度连续子序列,时间戳为子序列的起始时刻,值为子序列包含的数据点个数。 |
| |
| **提示:** 对于不符合要求的输入,本函数不对输出做任何保证。 |
| |
| ##### 使用示例 |
| |
| 输入序列: |
| |
| ``` |
| +-----------------------------+---------------+---------------+ |
| | Time|root.test.d1.s1|root.test.d1.s2| |
| +-----------------------------+---------------+---------------+ |
| |2020-01-01T00:00:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:05:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:10:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:20:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:25:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:30:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:35:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:40:00.000+08:00| 1.0| null| |
| |2020-01-01T00:45:00.000+08:00| 1.0| 1.0| |
| |2020-01-01T00:50:00.000+08:00| 1.0| 1.0| |
| +-----------------------------+---------------+---------------+ |
| ``` |
| |
| 用于查询的SQL语句: |
| |
| ```sql |
| select consecutivewindows(s1,s2,'length'='10m') from root.test.d1 |
| ``` |
| |
| 输出序列: |
| |
| ``` |
| +-----------------------------+--------------------------------------------------------------------+ |
| | Time|consecutivewindows(root.test.d1.s1, root.test.d1.s2, "length"="10m")| |
| +-----------------------------+--------------------------------------------------------------------+ |
| |2020-01-01T00:00:00.000+08:00| 3| |
| |2020-01-01T00:20:00.000+08:00| 3| |
| |2020-01-01T00:25:00.000+08:00| 3| |
| +-----------------------------+--------------------------------------------------------------------+ |
| ``` |