We will briefly go through the example of building movie recommendation service using the public dataset from Movielens.
There are plenty of materials on the collaborative filtering algorithm and process to build recommendation dataset,
so we will focus on how to integrate your trained machine learning model with property graph model.
The graph database that stores all movielens dataset. Also, S2Graph provide S2GraphQL which is unified REST Interface for not only graph query, but also serving trained model.
We process movielens dataset with Apache Spark and most importantly, Apache Spark's MLLib is used to build the model by training movielens data.
After Spark build model by running ALS algorithm, use annoy4s to build the index to find approximate nearest neighbors.
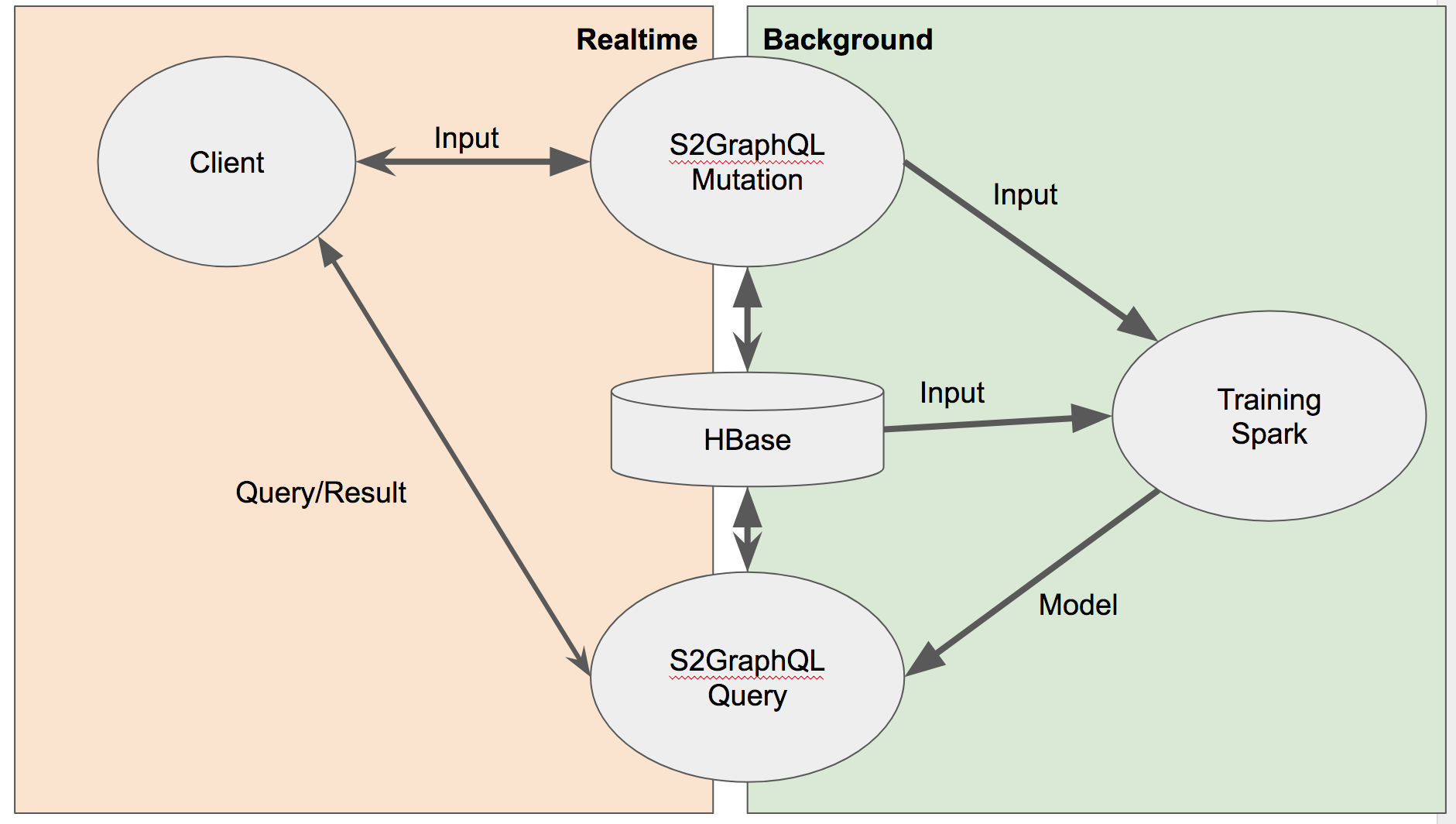
This example will set up local HBase, local Spark, local S2GraphQL server as the environment, and use graphiql as the client.
Followings are the representation of movielens dataset as property graph model.
Service represent namespace or database for this example. In this example, we will use movielens as service and all schema and data will be under this namespace.
mutation{ Management{ createService( name:"movielens" ){ isSuccess message object{ id name } } } }
Represent Node in movielens dataset. Each Node can store multiple properties on it if properties are configured on vertex schema.
Schemas must be registered under service correctly to mutate and query actual vertex/edge from S2Graph.
Data is under movies.csv file and followings are an example of data.
movieId,title,genres 1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy 2,Jumanji (1995),Adventure|Children|Fantasy 3,Grumpier Old Men (1995),Comedy|Romance ...
Following is mutation defined as S2GraphQL.
mutation{ Management{ createServiceColumn( serviceName:movielens columnName:"Movie" columnType: long props: [ { name: "title" dataType: string defaultValue: "" storeInGlobalIndex: true }, { name: "genres" dataType: string defaultValue: "" storeInGlobalIndex: true } ] ){ isSuccess message object{ id name } } } }
Note that S2Graph use user provided id, which is usually primary key in RDBMS, as vertexId.
S2Graph guarantee the uniqueness of vertexId by using composite of (service, serviceColumn, vertexId).
Also, note that “storeInGlobalIndex” which let S2Graph build the global index on “title” property.
When the user does not know vertexId in advance and still want to start graph query on vertices that meet certain search criteria, then this global index can be helpful.
In the real world, User vertex can have various property, such as age, gender, occupation, location, etc, but in movielens dataset, userId is only available.
mutation{ Management{ createServiceColumn( serviceName:movielens columnName:"User" columnType: long ){ isSuccess message object{ id name } } } }
Once we create vertex schema for Movie and User, it is time to create edge schema to model the relation between User and Movie.
The data is under ratings.csv file and this data represent which user rated which movie.
userId,movieId,rating,timestamp 1,31,2.5,1260759144 1,1029,3.0,1260759179 1,1061,3.0,1260759182 ...
mutation{ Management{ createLabel( name:"rated" sourceService: { movielens: { columnName: User } } targetService: { movielens: { columnName: Movie } } serviceName: movielens consistencyLevel: strong props:[ { name: "score" dataType: double defaultValue: "0.0" storeInGlobalIndex: true } ] indices:{ name:"_PK" propNames:["score"] } ) { isSuccess message object{ id name props{ name } } } } }
Since S2Graph support vertex-centric index, which is specific to a vertex, we create primary vertex-centric index “_PK” to be sorted by their score.
tags.csv file contains following data.
userId,movieId,tag,timestamp 15,339,sandra 'boring' bullock,1138537770 15,1955,dentist,1193435061 ...
mutation{ Management{ createLabel( name:"tagged" sourceService: { movielens: { columnName: User } } targetService: { movielens: { columnName: Movie } } serviceName: movielens consistencyLevel: weak props:[ { name: "tag" dataType: string defaultValue: "" storeInGlobalIndex: true } ] ) { isSuccess message object{ id name props{ name } } } } }
This represents similar movie relation, which actually not stored in S2Graph, but obtained by asking ALS model.
Since S2Graph provide pluggable interface how to fetch/mutate from storage, it is possible to provide the custom model implementation.
S2GRAPH-206 issue contains few popular implementations on this interface, such as Annoy, FastText, TensorFlow.
mutation{ Management{ createLabel( name:"similar_movie" sourceService: { movielens: { columnName: Movie } } targetService: { movielens: { columnName: Movie } } serviceName: movielens consistencyLevel: strong props:[ { name: "score" dataType: double defaultValue: "0.0" storeInGlobalIndex: false } ] indices:{ name:"_PK" propNames:["score"] } ) { isSuccess message object{ id name props{ name } } } } }
Note that there are no actual edges exist in the S2Graph system, but S2Graph knows which model to ask when user query “similar_movie” edges.
Also note that instead of considering entire ALS model, we use Annoy to support k approximate nearest neighbor search to make prediction fast.

cd example; sh run.shPrepare all pre-requisites to run this example.
S2GraphQL server start
target/apache-s2graph-*-incubating-bin/conf/target/apache-s2graph-*-incubating-bin/log/S2Jobs jar build
sbt project/s2jobs assemblys2jobs/target/scala-2.11/check SPARK_HOME is setup correctly
example/movielens/input/ratings.csv.itemFactors in trained ALS model.We provide few example queries that can show how to traverse not only graph data but also serving trained model.
This is the very basic kind of item-based collaborative filtering recommendation.
Recommendations are similar movies to movies that each user rated.
Note that we ask our model to find k nearest neighbor on the trained model to get similar_movie.
query { movielens { User(id: 1) { rated { Movie { title similar_movie(limit: 5) { Movie { title } } } } } } }
This shows S2Graph's global index feature, which answer “movies that contain Toy in their title”.
Note how intuitive the GraphQL syntax represent graph traversal.
query { movielens { Movie(search: "title: *Toy*", limit: 5) { title tagged(limit: 10) { User { id rated(limit: 5) { Movie { title } } } } } } }
We can mix model serving and graph traversal as follow.
query { movielens { Movie(search: "genres: *Comedy* AND title: *1995*", limit: 5) { title genres similar_movie(limit: 5) { Movie { title genres } } } } }
Note that we only need the trained model to traverse “similar_movie” relation.
We show how to serving not only graph data that is actually stored in the graph database but also data that can be obtained from the pre-trained model.
In general, S2Graph abstract the pre-trained model as an immutable graph that can produce vertices/edges for input vertex.
By using this abstraction, there is no distinction between model serving and graph data from client side.