| commit | 25542e4e78b39a3c9b9426a70a92ca7c183daea3 | [log] [tgz] |
|---|---|---|
| author | runzhiwang <runzhiwang@tencent.com> | Thu Dec 19 14:29:01 2019 +0800 |
| committer | jerryshao <jerryshao@tencent.com> | Thu Dec 19 14:29:01 2019 +0800 |
| tree | b0f24055cdf6bf2deb27c380be5de0f07b701014 | |
| parent | 1c656aad3495814fb55b5c2f5be708642b6174f3 [diff] |
[LIVY-727] Fix session state always be idle though the yarn application has been killed after restart livy ## What changes were proposed in this pull request? [LIVY-727] Fix session state always be idle though the yarn application has been killed after restart livy. Follows are steps to reproduce the problem: 1. Set livy.server.recovery.mode=recovery, and create a session in yarn-cluster 2. Restart livy 3. Kill the yarn application of the session. 4. The session state will always be idle and never change to killed or dead. Just as the image, livy-session-16 has been killed in yarn, but the state is still idle. 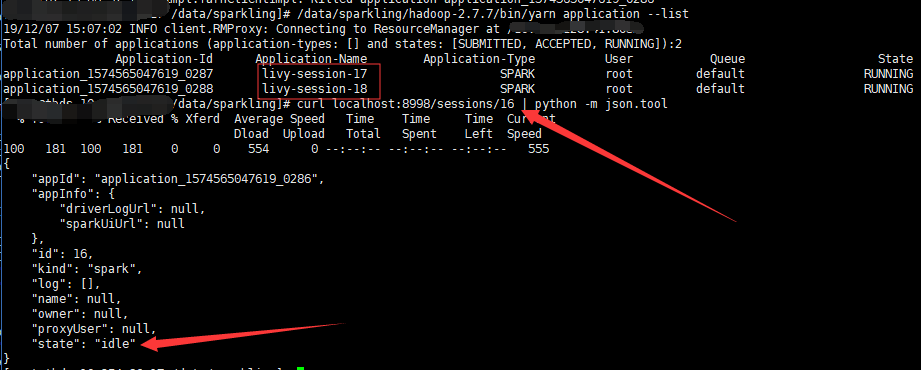 The cause of the problem are as follows: 1. Because when recover session, livy will not startDriver again, so the driverProcess is None. 2. SparkYarnApp will not be created in `driverProcess.map { _ => SparkApp.create(appTag, appId, driverProcess, livyConf, Some(this)) }` when driverProcess is None. 3. So yarnAppMonitorThread of the session will never start, and the session state will never change. How to fix the bug: 1. If livy run in yarn, SparkApp will create even though the driverProcess is None 2. If not run in yarn, SparkApp will not create, because the code require driverProcess is not None at https://github.com/apache/incubator-livy/blob/master/server/src/main/scala/org/apache/livy/utils/SparkApp.scala#L93, and I don't want to change the behavior. ## How was this patch tested? 1. Set livy.server.recovery.mode=recovery, and create a session in yarn-cluster 2. Restart livy 3. Kill the yarn application of the session. 4. The session state will change to killed Author: runzhiwang <runzhiwang@tencent.com> Closes #265 from runzhiwang/session-state.

Apache Livy is an open source REST interface for interacting with Apache Spark from anywhere. It supports executing snippets of code or programs in a Spark context that runs locally or in Apache Hadoop YARN.
Pull requests are welcomed! But before you begin, please check out the Contributing section on the Community page of our website.
Guides and documentation on getting started using Livy, example code snippets, and Livy API documentation can be found at livy.incubator.apache.org.
To build Livy, you will need:
Debian/Ubuntu:
maven package or maven3 tarball)Redhat/CentOS:
maven package or maven3 tarball)MacOS:
Required python packages for building Livy:
To run Livy, you will also need a Spark installation. You can get Spark releases at https://spark.apache.org/downloads.html.
Livy requires Spark 2.2+. You can switch to a different version of Spark by setting the SPARK_HOME environment variable in the Livy server process, without needing to rebuild Livy.
Livy is built using Apache Maven. To check out and build Livy, run:
git clone https://github.com/apache/incubator-livy.git cd incubator-livy mvn package
By default Livy is built against Apache Spark 2.2.0, but the version of Spark used when running Livy does not need to match the version used to build Livy. Livy internally handles the differences between different Spark versions.
The Livy package itself does not contain a Spark distribution. It will work with any supported version of Spark without needing to rebuild.
{kind=link}