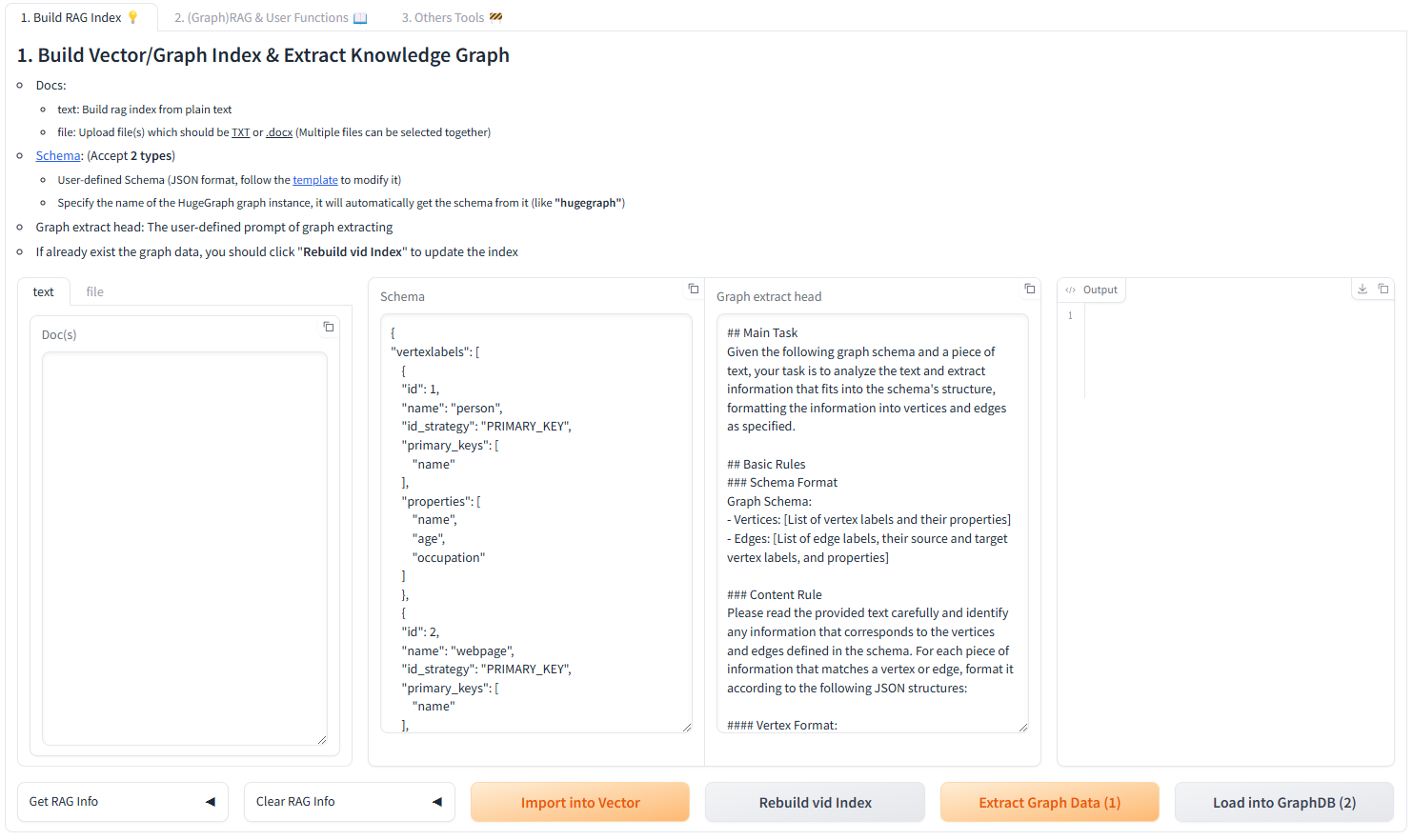
The hugegraph-llm is a tool for the implementation and research related to large language models. This project includes runnable demos, it can also be used as a third-party library.
As we know, graph systems can help large models address challenges like timeliness and hallucination, while large models can help graph systems with cost-related issues.
With this project, we aim to reduce the cost of using graph systems, and decrease the complexity of building knowledge graphs. This project will offer more applications and integration solutions for graph systems and large language models.
Start the HugeGraph database, you can run it via Docker/Binary Package.
Refer to detailed doc for more guidance
Configuring the poetry environment, Use the official installer to install Poetry, See the poetry documentation for other installation methods
# You could try pipx or pip to install poetry when meet network issues, refer the poetry doc for more details curl -sSL https://install.python-poetry.org | python3 - # install the latest version like 2.0+
Clone this project
git clone https://github.com/apache/incubator-hugegraph-ai.git
Install hugegraph-python-client and hugegraph_llm, poetry officially recommends using virtual environments
cd ./incubator-hugegraph-ai/hugegraph-llm poetry config --list # List/check the current configuration (Optional) # e.g: poetry config virtualenvs.in-project true # You could update the poetry configs if need poetry install # (Recommended) If you want to use the shell of the venv, you can run the following command poetry self add poetry-plugin-shell # from poetry 2.0+ poetry shell # use 'exit' to leave the shell
If poetry install fails or too slow due to network issues, it is recommended to modify tool.poetry.source of hugegraph-llm/pyproject.toml
Enter the project directory(./incubator-hugegraph-ai/hugegraph-llm/src)
cd ./src
Start the gradio interactive demo of Graph RAG, you can run with the following command, and open http://127.0.0.1:8001 after starting
python -m hugegraph_llm.demo.rag_demo.app # same as "poetry run xxx"
The default host is 0.0.0.0 and the port is 8001. You can change them by passing command line arguments--host and --port.
python -m hugegraph_llm.demo.rag_demo.app --host 127.0.0.1 --port 18001
After running the web demo, the config file .env will be automatically generated at the path hugegraph-llm/.env. Additionally, a prompt-related configuration file config_prompt.yaml will also be generated at the path hugegraph-llm/src/hugegraph_llm/resources/demo/config_prompt.yaml. You can modify the content on the web page, and it will be automatically saved to the configuration file after the corresponding feature is triggered. You can also modify the file directly without restarting the web application; refresh the page to load your latest changes.
(Optional)To regenerate the config file, you can use config.generate with -u or --update.
python -m hugegraph_llm.config.generate --update
Note: Litellm support multi-LLM provider, refer litellm.ai to config it
(Optional) You could use hugegraph-hubble to visit the graph data, could run it via Docker/Docker-Compose for guidance. (Hubble is a graph-analysis dashboard include data loading/schema management/graph traverser/display).
(Optional) offline download NLTK stopwords
python ./hugegraph_llm/operators/common_op/nltk_helper.py
Parameter description:
The KgBuilder class is used to construct a knowledge graph. Here is a brief usage guide:
Initialization: The KgBuilder class is initialized with an instance of a language model. This can be obtained from the LLMs class.
Initialize the LLMs instance, get the LLM, and then create a task instance KgBuilder for graph construction. KgBuilder defines multiple operators, and users can freely combine them according to their needs. (tip: print_result() can print the result of each step in the console, without affecting the overall execution logic)
from hugegraph_llm.models.llms.init_llm import LLMs from hugegraph_llm.operators.kg_construction_task import KgBuilder TEXT = "" builder = KgBuilder(LLMs().get_chat_llm()) ( builder .import_schema(from_hugegraph="talent_graph").print_result() .chunk_split(TEXT).print_result() .extract_info(extract_type="property_graph").print_result() .commit_to_hugegraph() .run() )
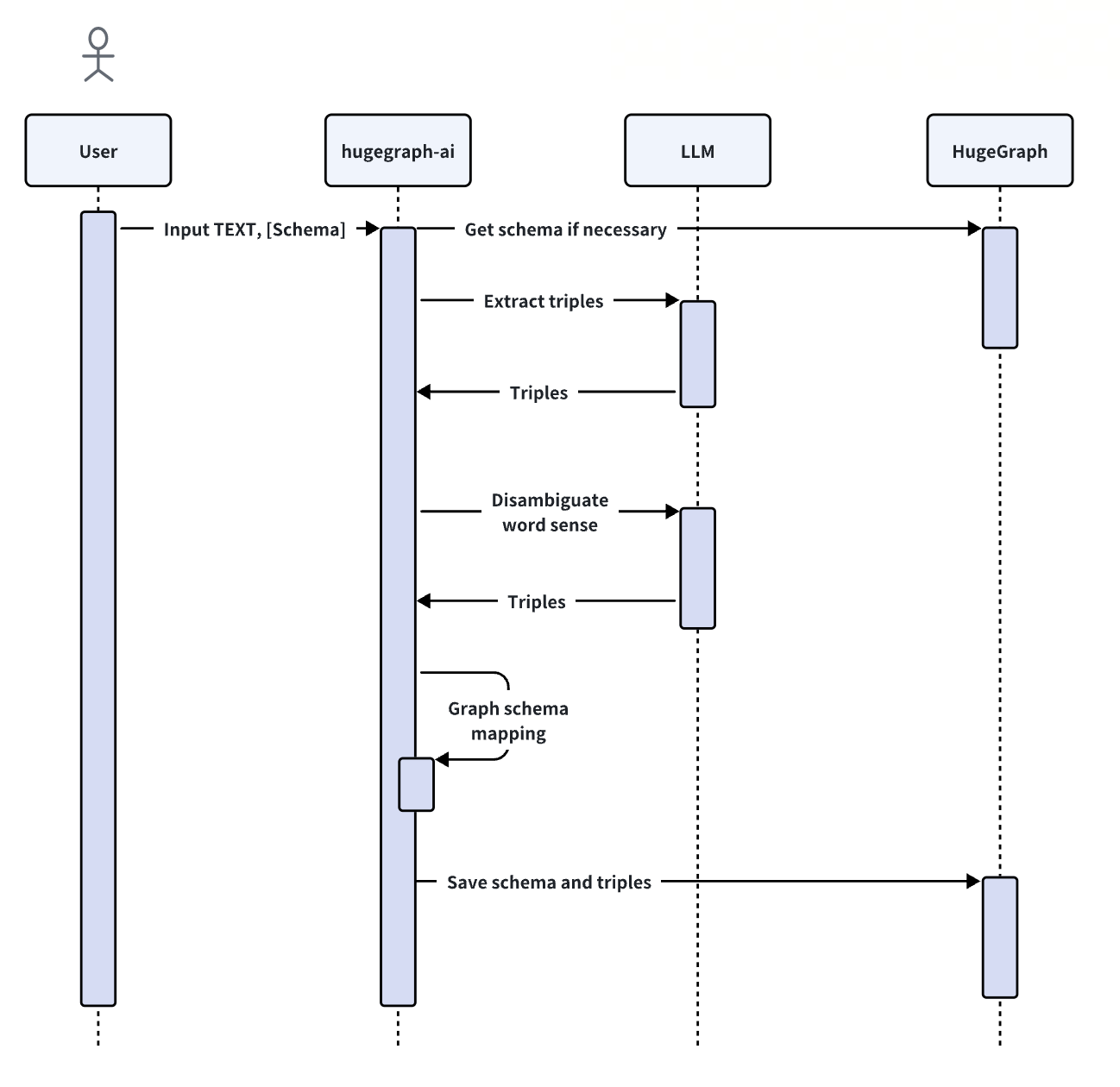
Import Schema: The import_schema method is used to import a schema from a source. The source can be a HugeGraph instance, a user-defined schema or an extraction result. The method print_result can be chained to print the result.
# Import schema from a HugeGraph instance builder.import_schema(from_hugegraph="xxx").print_result() # Import schema from an extraction result builder.import_schema(from_extraction="xxx").print_result() # Import schema from user-defined schema builder.import_schema(from_user_defined="xxx").print_result()
Chunk Split: The chunk_split method is used to split the input text into chunks. The text should be passed as a string argument to the method.
# Split the input text into documents builder.chunk_split(TEXT, split_type="document").print_result() # Split the input text into paragraphs builder.chunk_split(TEXT, split_type="paragraph").print_result() # Split the input text into sentences builder.chunk_split(TEXT, split_type="sentence").print_result()
Extract Info: The extract_info method is used to extract info from a text. The text should be passed as a string argument to the method.
TEXT = "Meet Sarah, a 30-year-old attorney, and her roommate, James, whom she's shared a home with since 2010." # extract property graph from the input text builder.extract_info(extract_type="property_graph").print_result() # extract triples from the input text builder.extract_info(extract_type="property_graph").print_result()
Commit to HugeGraph: The commit_to_hugegraph method is used to commit the constructed knowledge graph to a HugeGraph instance.
builder.commit_to_hugegraph().print_result()
Run: The run method is used to execute the chained operations.
builder.run()
The methods of the KgBuilder class can be chained together to perform a sequence of operations.
The RAGPipeline class is used to integrate HugeGraph with large language models to provide retrieval-augmented generation capabilities. Here is a brief usage guide:
from hugegraph_llm.operators.graph_rag_task import RAGPipeline graph_rag = RAGPipeline() graph_rag.extract_keywords(text="Tell me about Al Pacino.").print_result()
graph_rag.keywords_to_vid().print_result()
graph_rag.query_graphdb(max_deep=2, max_graph_items=30).print_result()
graph_rag.merge_dedup_rerank().print_result()
graph_rag.synthesize_answer(vector_only_answer=False, graph_only_answer=True).print_result()
run method is used to execute the above operations.graph_rag.run(verbose=True)