refactor: port batch build gremlin examples & delete some doc related to Pipeline(old design) & refactor some operator's design and implementation & code format
diff --git a/README.md b/README.md
index 14f02ca..a495968 100644
--- a/README.md
+++ b/README.md
@@ -75,42 +75,6 @@
> [!NOTE]
> Examples assume you've activated the virtual environment with `source .venv/bin/activate`
-#### GraphRAG - Question Answering
-
-```python
-from hugegraph_llm.operators.graph_rag_task import RAGPipeline
-
-# Initialize RAG pipeline
-graph_rag = RAGPipeline()
-
-# Ask questions about your graph
-result = (graph_rag
- .extract_keywords(text="Tell me about Al Pacino.")
- .keywords_to_vid()
- .query_graphdb(max_deep=2, max_graph_items=30)
- .merge_dedup_rerank()
- .synthesize_answer()
- .run())
-```
-
-#### Knowledge Graph Construction
-
-```python
-from hugegraph_llm.models.llms.init_llm import LLMs
-from hugegraph_llm.operators.kg_construction_task import KgBuilder
-
-# Build KG from text
-TEXT = "Your text content here..."
-builder = KgBuilder(LLMs().get_chat_llm())
-
-(builder
- .import_schema(from_hugegraph="hugegraph")
- .chunk_split(TEXT)
- .extract_info(extract_type="property_graph")
- .commit_to_hugegraph()
- .run())
-```
-
#### Graph Machine Learning
```bash
diff --git a/hugegraph-llm/README.md b/hugegraph-llm/README.md
index 526320d..8b7e15c 100644
--- a/hugegraph-llm/README.md
+++ b/hugegraph-llm/README.md
@@ -89,14 +89,14 @@
# 3. Clone and setup project
git clone https://github.com/apache/incubator-hugegraph-ai.git
-cd incubator-hugegraph-ai/hugegraph-llm
+cd incubator-hugegraph-ai
# Configure environment (see config.md for detailed options), .env will auto create if not exists
# 4. Install dependencies and activate environment
# NOTE: If download is slow, uncomment mirror lines in ../pyproject.toml or use: uv config --global index.url https://pypi.tuna.tsinghua.edu.cn/simple
# Or create local uv.toml with mirror settings to avoid git diff (see uv.toml example in root)
-uv sync # Automatically creates .venv and installs dependencies
+uv sync --extra llm # Automatically creates .venv and installs dependencies
source .venv/bin/activate # Activate once - all commands below assume this environment
# 5. Launch RAG demo
@@ -146,84 +146,6 @@
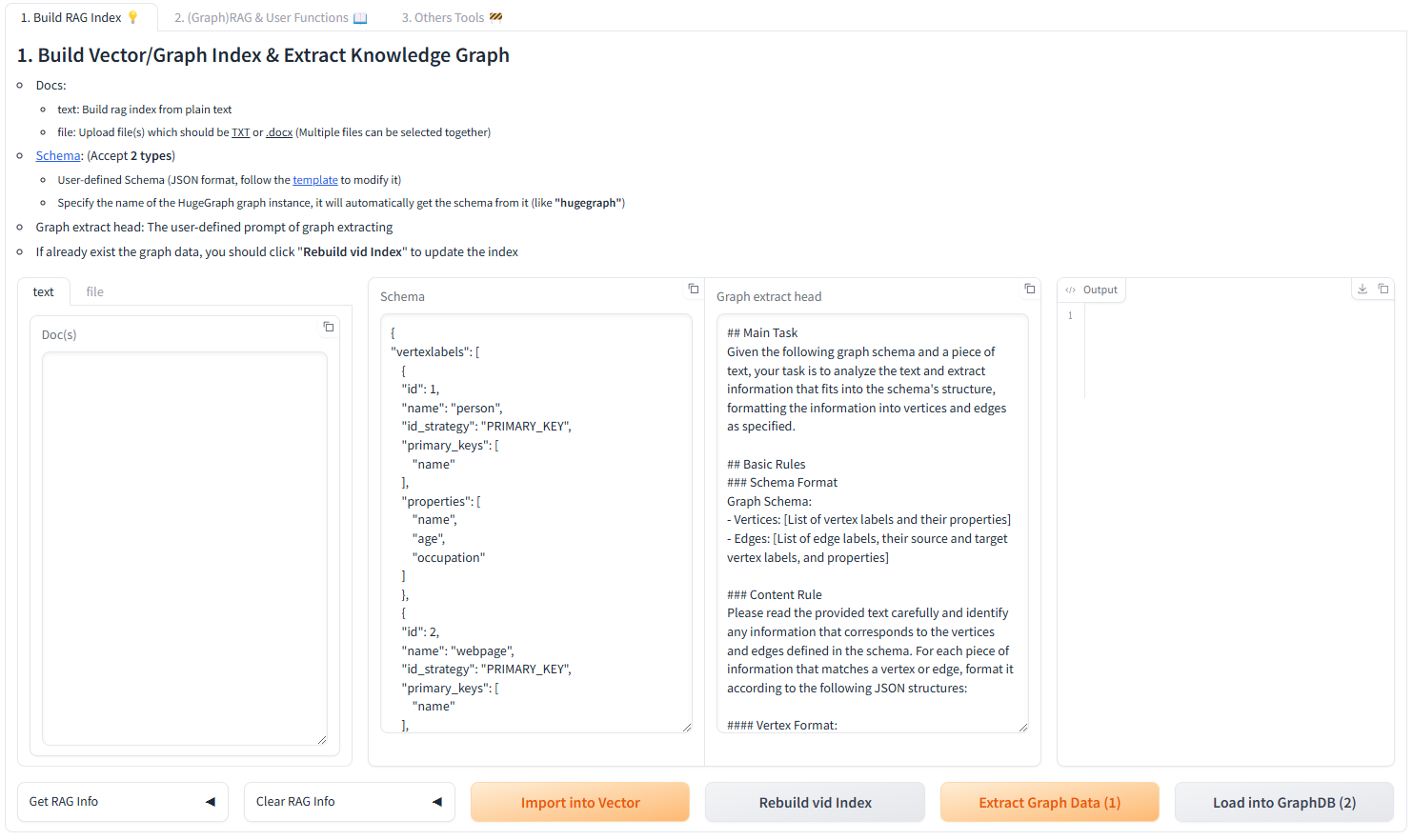
-#### Programmatic Construction
-
-Build knowledge graphs with code using the `KgBuilder` class:
-
-```python
-from hugegraph_llm.models.llms.init_llm import LLMs
-from hugegraph_llm.operators.kg_construction_task import KgBuilder
-
-# Initialize and chain operations
-TEXT = "Your input text here..."
-builder = KgBuilder(LLMs().get_chat_llm())
-
-(
- builder
- .import_schema(from_hugegraph="talent_graph").print_result()
- .chunk_split(TEXT).print_result()
- .extract_info(extract_type="property_graph").print_result()
- .commit_to_hugegraph()
- .run()
-)
-```
-
-**Pipeline Workflow:**
-
-```mermaid
-graph LR
- A[Import Schema] --> B[Chunk Split]
- B --> C[Extract Info]
- C --> D[Commit to HugeGraph]
- D --> E[Execute Pipeline]
-
- style A fill:#fff2cc
- style B fill:#d5e8d4
- style C fill:#dae8fc
- style D fill:#f8cecc
- style E fill:#e1d5e7
-```
-
-### Graph-Enhanced RAG
-
-Leverage HugeGraph for retrieval-augmented generation:
-
-```python
-from hugegraph_llm.operators.graph_rag_task import RAGPipeline
-
-# Initialize RAG pipeline
-graph_rag = RAGPipeline()
-
-# Execute RAG workflow
-(
- graph_rag
- .extract_keywords(text="Tell me about Al Pacino.")
- .keywords_to_vid()
- .query_graphdb(max_deep=2, max_graph_items=30)
- .merge_dedup_rerank()
- .synthesize_answer(vector_only_answer=False, graph_only_answer=True)
- .run(verbose=True)
-)
-```
-
-**RAG Pipeline Flow:**
-
-```mermaid
-graph TD
- A[User Query] --> B[Extract Keywords]
- B --> C[Match Graph Nodes]
- C --> D[Retrieve Graph Context]
- D --> E[Rerank Results]
- E --> F[Generate Answer]
-
- style A fill:#e3f2fd
- style B fill:#f3e5f5
- style C fill:#e8f5e8
- style D fill:#fff3e0
- style E fill:#fce4ec
- style F fill:#e0f2f1
-```
-
## 🔧 Configuration
After running the demo, configuration files are automatically generated:
@@ -248,6 +170,79 @@
**LLM Provider Support**: This project uses [LiteLLM](https://docs.litellm.ai/docs/providers) for multi-provider LLM support.
+### Programmatic Examples (new workflow engine)
+
+If you previously used high-level classes like `RAGPipeline` or `KgBuilder`, the project now exposes stable flows through the `Scheduler` API. Use `SchedulerSingleton.get_instance().schedule_flow(...)` to invoke workflows programmatically. Below are concise, working examples that match the new architecture.
+
+1) RAG (graph-only) query example
+
+```python
+from hugegraph_llm.flows.scheduler import SchedulerSingleton
+
+scheduler = SchedulerSingleton.get_instance()
+res = scheduler.schedule_flow(
+ "rag_graph_only",
+ query="Tell me about Al Pacino.",
+ graph_only_answer=True,
+ vector_only_answer=False,
+ raw_answer=False,
+ gremlin_tmpl_num=-1,
+ gremlin_prompt=None,
+)
+
+print(res.get("graph_only_answer"))
+```
+
+2) RAG (vector-only) query example
+
+```python
+from hugegraph_llm.flows.scheduler import SchedulerSingleton
+
+scheduler = SchedulerSingleton.get_instance()
+res = scheduler.schedule_flow(
+ "rag_vector_only",
+ query="Summarize the career of Ada Lovelace.",
+ vector_only_answer=True,
+ vector_search=True
+)
+
+print(res.get("vector_only_answer"))
+```
+
+3) Text -> Gremlin (text2gremlin) example
+
+```python
+from hugegraph_llm.flows.scheduler import SchedulerSingleton
+
+scheduler = SchedulerSingleton.get_instance()
+response = scheduler.schedule_flow(
+ "text2gremlin",
+ "find people who worked with Alan Turing",
+ 2, # example_num
+ "hugegraph", # schema_input (graph name or schema)
+ None, # gremlin_prompt_input (optional)
+ ["template_gremlin", "raw_gremlin"],
+)
+
+print(response.get("template_gremlin"))
+```
+
+4) Build example index (used by text2gremlin examples)
+
+```python
+from hugegraph_llm.flows.scheduler import SchedulerSingleton
+
+examples = [{"id": "natural language query", "gremlin": "g.V().hasLabel('person').valueMap()"}]
+res = SchedulerSingleton.get_instance().schedule_flow("build_examples_index", examples)
+print(res)
+```
+
+### Migration guide: RAGPipeline / KgBuilder → Scheduler flows
+
+Why the change: the internal execution engine was refactored to a pipeline-based scheduler (GPipeline + GPipelineManager). The scheduler provides a stable entrypoint while keeping flow implementations modular.
+
+If you need help migrating a specific snippet, open a PR or issue and include the old code — we can provide a targeted conversion.
+
## 🤖 Developer Guidelines
> [!IMPORTANT] > **For developers contributing to hugegraph-llm with AI coding assistance:**
diff --git a/hugegraph-llm/pyproject.toml b/hugegraph-llm/pyproject.toml
index 2b0f29a..b3894d7 100644
--- a/hugegraph-llm/pyproject.toml
+++ b/hugegraph-llm/pyproject.toml
@@ -17,7 +17,7 @@
[project]
name = "hugegraph-llm"
-version = "1.5.0"
+version = "1.7.0"
description = "A tool for the implementation and research related to large language models."
authors = [
{ name = "Apache HugeGraph Contributors", email = "dev@hugegraph.apache.org" },
@@ -89,4 +89,6 @@
[tool.uv.sources]
hugegraph-python-client = { workspace = true }
-pycgraph = { git = "https://github.com/ChunelFeng/CGraph.git", subdirectory = "python", rev = "main", marker = "sys_platform == 'linux'" }
+# We encountered a bug in PyCGraph's latest release version, so we're using a specific commit from the main branch (without the bug) as the project dependency.
+# TODO: Replace this command in the future when a new PyCGraph release version (after 3.1.2) is available.
+pycgraph = { git = "https://github.com/ChunelFeng/CGraph.git", subdirectory = "python", rev = "248bfcfeddfa2bc23a1d585a3925c71189dba6cc"}
diff --git a/hugegraph-llm/src/hugegraph_llm/api/admin_api.py b/hugegraph-llm/src/hugegraph_llm/api/admin_api.py
index 4c192c2..109da4a 100644
--- a/hugegraph-llm/src/hugegraph_llm/api/admin_api.py
+++ b/hugegraph-llm/src/hugegraph_llm/api/admin_api.py
@@ -31,7 +31,7 @@
@router.post("/logs", status_code=status.HTTP_200_OK)
async def log_stream_api(req: LogStreamRequest):
if admin_settings.admin_token != req.admin_token:
- raise generate_response(
+ raise generate_response( # pylint: disable=raising-bad-type
RAGResponse(
status_code=status.HTTP_403_FORBIDDEN, # pylint: disable=E0702
message="Invalid admin_token",
diff --git a/hugegraph-llm/src/hugegraph_llm/api/rag_api.py b/hugegraph-llm/src/hugegraph_llm/api/rag_api.py
index 356176e..ca29cb9 100644
--- a/hugegraph-llm/src/hugegraph_llm/api/rag_api.py
+++ b/hugegraph-llm/src/hugegraph_llm/api/rag_api.py
@@ -31,9 +31,8 @@
from hugegraph_llm.api.models.rag_response import RAGResponse
from hugegraph_llm.config import huge_settings
from hugegraph_llm.config import llm_settings, prompt
+from hugegraph_llm.utils.graph_index_utils import get_vertex_details
from hugegraph_llm.utils.log import log
-from hugegraph_llm.flows.scheduler import SchedulerSingleton
-
# pylint: disable=too-many-statements
@@ -51,6 +50,13 @@
def rag_answer_api(req: RAGRequest):
set_graph_config(req)
+ # Basic parameter validation: empty query => 400
+ if not req.query or not str(req.query).strip():
+ raise HTTPException(
+ status_code=status.HTTP_400_BAD_REQUEST,
+ detail="Query must not be empty.",
+ )
+
result = rag_answer_func(
text=req.query,
raw_answer=req.raw_answer,
@@ -68,7 +74,8 @@
# Keep prompt params in the end
custom_related_information=req.custom_priority_info,
answer_prompt=req.answer_prompt or prompt.answer_prompt,
- keywords_extract_prompt=req.keywords_extract_prompt or prompt.keywords_extract_prompt,
+ keywords_extract_prompt=req.keywords_extract_prompt
+ or prompt.keywords_extract_prompt,
gremlin_prompt=req.gremlin_prompt or prompt.gremlin_generate_prompt,
)
# TODO: we need more info in the response for users to understand the query logic
@@ -77,7 +84,8 @@
**{
key: value
for key, value in zip(
- ["raw_answer", "vector_only", "graph_only", "graph_vector_answer"], result
+ ["raw_answer", "vector_only", "graph_only", "graph_vector_answer"],
+ result,
)
if getattr(req, key)
},
@@ -96,6 +104,13 @@
try:
set_graph_config(req)
+ # Basic parameter validation: empty query => 400
+ if not req.query or not str(req.query).strip():
+ raise HTTPException(
+ status_code=status.HTTP_400_BAD_REQUEST,
+ detail="Query must not be empty.",
+ )
+
result = graph_rag_recall_func(
query=req.query,
max_graph_items=req.max_graph_items,
@@ -111,12 +126,7 @@
)
if req.get_vertex_only:
- from hugegraph_llm.operators.hugegraph_op.graph_rag_query import GraphRAGQuery
-
- graph_rag = GraphRAGQuery()
- graph_rag.init_client(result)
- vertex_details = graph_rag.get_vertex_details(result["match_vids"])
-
+ vertex_details = get_vertex_details(result["match_vids"], result)
if vertex_details:
result["match_vids"] = vertex_details
@@ -136,7 +146,9 @@
except TypeError as e:
log.error("TypeError in graph_rag_recall_api: %s", e)
- raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST, detail=str(e)) from e
+ raise HTTPException(
+ status_code=status.HTTP_400_BAD_REQUEST, detail=str(e)
+ ) from e
except Exception as e:
log.error("Unexpected error occurred: %s", e)
raise HTTPException(
@@ -147,7 +159,9 @@
@router.post("/config/graph", status_code=status.HTTP_201_CREATED)
def graph_config_api(req: GraphConfigRequest):
# Accept status code
- res = apply_graph_conf(req.url, req.name, req.user, req.pwd, req.gs, origin_call="http")
+ res = apply_graph_conf(
+ req.url, req.name, req.user, req.pwd, req.gs, origin_call="http"
+ )
return generate_response(RAGResponse(status_code=res, message="Missing Value"))
# TODO: restructure the implement of llm to three types, like "/config/chat_llm"
@@ -157,10 +171,16 @@
if req.llm_type == "openai":
res = apply_llm_conf(
- req.api_key, req.api_base, req.language_model, req.max_tokens, origin_call="http"
+ req.api_key,
+ req.api_base,
+ req.language_model,
+ req.max_tokens,
+ origin_call="http",
)
else:
- res = apply_llm_conf(req.host, req.port, req.language_model, None, origin_call="http")
+ res = apply_llm_conf(
+ req.host, req.port, req.language_model, None, origin_call="http"
+ )
return generate_response(RAGResponse(status_code=res, message="Missing Value"))
@router.post("/config/embedding", status_code=status.HTTP_201_CREATED)
@@ -172,7 +192,9 @@
req.api_key, req.api_base, req.language_model, origin_call="http"
)
else:
- res = apply_embedding_conf(req.host, req.port, req.language_model, origin_call="http")
+ res = apply_embedding_conf(
+ req.host, req.port, req.language_model, origin_call="http"
+ )
return generate_response(RAGResponse(status_code=res, message="Missing Value"))
@router.post("/config/rerank", status_code=status.HTTP_201_CREATED)
@@ -184,7 +206,9 @@
req.api_key, req.reranker_model, req.cohere_base_url, origin_call="http"
)
elif req.reranker_type == "siliconflow":
- res = apply_reranker_conf(req.api_key, req.reranker_model, None, origin_call="http")
+ res = apply_reranker_conf(
+ req.api_key, req.reranker_model, None, origin_call="http"
+ )
else:
res = status.HTTP_501_NOT_IMPLEMENTED
return generate_response(RAGResponse(status_code=res, message="Missing Value"))
@@ -197,20 +221,20 @@
# Basic parameter validation: empty query => 400
if not req.query or not str(req.query).strip():
raise HTTPException(
- status_code=status.HTTP_400_BAD_REQUEST, detail="Query must not be empty."
+ status_code=status.HTTP_400_BAD_REQUEST,
+ detail="Query must not be empty.",
)
output_types_str_list = None
if req.output_types:
output_types_str_list = [ot.value for ot in req.output_types]
- response_dict = SchedulerSingleton.get_instance().schedule_flow(
- "text2gremlin",
- req.query,
- req.example_num,
- huge_settings.graph_name,
- req.gremlin_prompt,
- output_types_str_list,
+ response_dict = gremlin_generate_selective_func(
+ inp=req.query,
+ example_num=req.example_num,
+ schema_input=huge_settings.graph_name,
+ gremlin_prompt_input=req.gremlin_prompt,
+ requested_outputs=output_types_str_list,
)
return response_dict
except HTTPException as e:
diff --git a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/rag_block.py b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/rag_block.py
index ca36867..9bf04b5 100644
--- a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/rag_block.py
+++ b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/rag_block.py
@@ -19,12 +19,12 @@
import os
from typing import AsyncGenerator, Literal, Optional, Tuple
-
-import gradio as gr
-from hugegraph_llm.flows.scheduler import SchedulerSingleton
import pandas as pd
+import gradio as gr
from gradio.utils import NamedString
+from hugegraph_llm.flows import FlowName
+from hugegraph_llm.flows.scheduler import SchedulerSingleton
from hugegraph_llm.config import resource_path, prompt, llm_settings
from hugegraph_llm.utils.decorators import with_task_id
from hugegraph_llm.utils.log import log
@@ -51,11 +51,7 @@
) -> Tuple:
"""
Generate an answer using the RAG (Retrieval-Augmented Generation) pipeline.
- 1. Initialize the RAGPipeline.
- 2. Select vector search or graph search based on parameters.
- 3. Merge, deduplicate, and rerank the results.
- 4. Synthesize the final answer.
- 5. Run the pipeline and return the results.
+ Fetch the Scheduler to deal with the request
"""
graph_search, gremlin_prompt, vector_search = update_ui_configs(
answer_prompt,
@@ -75,13 +71,13 @@
try:
# Select workflow by mode to avoid fetching the wrong pipeline from the pool
if graph_vector_answer or (graph_only_answer and vector_only_answer):
- flow_key = "rag_graph_vector"
+ flow_key = FlowName.RAG_GRAPH_VECTOR
elif vector_only_answer:
- flow_key = "rag_vector_only"
+ flow_key = FlowName.RAG_VECTOR_ONLY
elif graph_only_answer:
- flow_key = "rag_graph_only"
+ flow_key = FlowName.RAG_GRAPH_ONLY
elif raw_answer:
- flow_key = "rag_raw"
+ flow_key = FlowName.RAG_RAW
else:
raise RuntimeError("Unsupported flow type")
@@ -172,11 +168,7 @@
) -> AsyncGenerator[Tuple[str, str, str, str], None]:
"""
Generate an answer using the RAG (Retrieval-Augmented Generation) pipeline.
- 1. Initialize the RAGPipeline.
- 2. Select vector search or graph search based on parameters.
- 3. Merge, deduplicate, and rerank the results.
- 4. Synthesize the final answer.
- 5. Run the pipeline and return the results.
+ Fetch the Scheduler to deal with the request
"""
graph_search, gremlin_prompt, vector_search = update_ui_configs(
answer_prompt,
@@ -197,13 +189,13 @@
# Select the specific streaming workflow
scheduler = SchedulerSingleton.get_instance()
if graph_vector_answer or (graph_only_answer and vector_only_answer):
- flow_key = "rag_graph_vector"
+ flow_key = FlowName.RAG_GRAPH_VECTOR
elif vector_only_answer:
- flow_key = "rag_vector_only"
+ flow_key = FlowName.RAG_VECTOR_ONLY
elif graph_only_answer:
- flow_key = "rag_graph_only"
+ flow_key = FlowName.RAG_GRAPH_ONLY
elif raw_answer:
- flow_key = "rag_raw"
+ flow_key = FlowName.RAG_RAW
else:
raise RuntimeError("Unsupported flow type")
@@ -367,7 +359,7 @@
)
gr.Markdown(
- """## 2. (Batch) Back-testing )
+ """## 2. (Batch) Back-testing
> 1. Download the template file & fill in the questions you want to test.
> 2. Upload the file & click the button to generate answers. (Preview shows the first 40 lines)
> 3. The answer options are the same as the above RAG/Q&A frame
diff --git a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/text2gremlin_block.py b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/text2gremlin_block.py
index 6600d7c..aa9c2f0 100644
--- a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/text2gremlin_block.py
+++ b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/text2gremlin_block.py
@@ -25,11 +25,7 @@
import pandas as pd
from hugegraph_llm.config import prompt, resource_path, huge_settings
-from hugegraph_llm.models.embeddings.init_embedding import Embeddings
-from hugegraph_llm.models.llms.init_llm import LLMs
-from hugegraph_llm.operators.graph_rag_task import RAGPipeline
-from hugegraph_llm.operators.gremlin_generate_task import GremlinGenerator
-from hugegraph_llm.operators.hugegraph_op.schema_manager import SchemaManager
+from hugegraph_llm.flows import FlowName
from hugegraph_llm.utils.embedding_utils import get_index_folder_name
from hugegraph_llm.utils.hugegraph_utils import run_gremlin_query
from hugegraph_llm.utils.log import log
@@ -86,7 +82,9 @@
def build_example_vector_index(temp_file) -> dict:
- folder_name = get_index_folder_name(huge_settings.graph_name, huge_settings.graph_space)
+ folder_name = get_index_folder_name(
+ huge_settings.graph_name, huge_settings.graph_space
+ )
index_path = os.path.join(resource_path, folder_name, "gremlin_examples")
if not os.path.exists(index_path):
os.makedirs(index_path)
@@ -98,7 +96,9 @@
timestamp = datetime.now().strftime("%Y%m%d%H%M%S")
_, file_name = os.path.split(f"{name}_{timestamp}{ext}")
log.info("Copying file to: %s", file_name)
- target_file = os.path.join(resource_path, folder_name, "gremlin_examples", file_name)
+ target_file = os.path.join(
+ resource_path, folder_name, "gremlin_examples", file_name
+ )
try:
import shutil
@@ -116,11 +116,10 @@
else:
log.critical("Unsupported file format. Please input a JSON or CSV file.")
return {"error": "Unsupported file format. Please input a JSON or CSV file."}
- builder = GremlinGenerator(
- llm=LLMs().get_text2gql_llm(),
- embedding=Embeddings().get_embedding(),
+
+ return SchedulerSingleton.get_instance().schedule_flow(
+ FlowName.BUILD_EXAMPLES_INDEX, examples
)
- return builder.example_index_build(examples).run()
def _process_schema(schema, generator, sm):
@@ -182,43 +181,6 @@
context["raw_exec_res"] = ""
-def gremlin_generate(
- inp, example_num, schema, gremlin_prompt, requested_outputs: Optional[List[str]] = None
-) -> GremlinResult:
- generator = GremlinGenerator(
- llm=LLMs().get_text2gql_llm(), embedding=Embeddings().get_embedding()
- )
- sm = SchemaManager(graph_name=schema)
-
- processed_schema, short_schema = _process_schema(schema, generator, sm)
- if processed_schema is None and short_schema is None:
- return GremlinResult.error("Invalid JSON schema, please check the format carefully.")
-
- updated_schema = sm.simple_schema(processed_schema) if short_schema else processed_schema
- store_schema(str(updated_schema), inp, gremlin_prompt)
-
- output_types = _configure_output_types(requested_outputs)
-
- context = (
- generator.example_index_query(example_num)
- .gremlin_generate_synthesize(updated_schema, gremlin_prompt)
- .run(query=inp)
- )
-
- _execute_queries(context, output_types)
-
- match_result = json.dumps(
- context.get("match_result", "No Results"), ensure_ascii=False, indent=2
- )
- return GremlinResult.success_result(
- match_result=match_result,
- template_gremlin=context["result"],
- raw_gremlin=context["raw_result"],
- template_exec=context["template_exec_res"],
- raw_exec=context["raw_exec_res"],
- )
-
-
def simple_schema(schema: Dict[str, Any]) -> Dict[str, Any]:
mini_schema = {}
@@ -226,7 +188,11 @@
if "vertexlabels" in schema:
mini_schema["vertexlabels"] = []
for vertex in schema["vertexlabels"]:
- new_vertex = {key: vertex[key] for key in ["id", "name", "properties"] if key in vertex}
+ new_vertex = {
+ key: vertex[key]
+ for key in ["id", "name", "properties"]
+ if key in vertex
+ }
mini_schema["vertexlabels"].append(new_vertex)
# Add necessary edgelabels items (4)
@@ -248,7 +214,7 @@
# Execute via scheduler
try:
res = SchedulerSingleton.get_instance().schedule_flow(
- "text2gremlin",
+ FlowName.TEXT2GREMLIN,
inp,
int(example_num) if isinstance(example_num, (int, float, str)) else 2,
schema,
@@ -305,15 +271,21 @@
with gr.Row():
with gr.Column(scale=1):
input_box = gr.Textbox(
- value=prompt.default_question, label="Nature Language Query", show_copy_button=True
+ value=prompt.default_question,
+ label="Nature Language Query",
+ show_copy_button=True,
)
match = gr.Code(
label="Similar Template (TopN)",
language="javascript",
elem_classes="code-container-show",
)
- initialized_out = gr.Textbox(label="Gremlin With Template", show_copy_button=True)
- raw_out = gr.Textbox(label="Gremlin Without Template", show_copy_button=True)
+ initialized_out = gr.Textbox(
+ label="Gremlin With Template", show_copy_button=True
+ )
+ raw_out = gr.Textbox(
+ label="Gremlin Without Template", show_copy_button=True
+ )
tmpl_exec_out = gr.Code(
label="Query With Template Output",
language="json",
@@ -330,7 +302,10 @@
minimum=0, maximum=10, step=1, value=2, label="Number of refer examples"
)
schema_box = gr.Textbox(
- value=prompt.text2gql_graph_schema, label="Schema", lines=2, show_copy_button=True
+ value=prompt.text2gql_graph_schema,
+ label="Schema",
+ lines=2,
+ show_copy_button=True,
)
prompt_box = gr.Textbox(
value=prompt.gremlin_generate_prompt,
@@ -362,24 +337,21 @@
get_vertex_only: bool = False,
) -> dict:
store_schema(prompt.text2gql_graph_schema, query, gremlin_prompt)
- rag = RAGPipeline()
- rag.extract_keywords().keywords_to_vid(
+ context = SchedulerSingleton.get_instance().schedule_flow(
+ FlowName.RAG_GRAPH_ONLY,
+ query=query,
+ gremlin_tmpl_num=gremlin_tmpl_num,
+ rerank_method=rerank_method,
+ near_neighbor_first=near_neighbor_first,
+ custom_related_information=custom_related_information,
+ gremlin_prompt=gremlin_prompt,
+ max_graph_items=max_graph_items,
+ topk_return_results=topk_return_results,
vector_dis_threshold=vector_dis_threshold,
topk_per_keyword=topk_per_keyword,
+ is_graph_rag_recall=True,
+ is_vector_only=get_vertex_only,
)
-
- if not get_vertex_only:
- rag.import_schema(huge_settings.graph_name).query_graphdb(
- num_gremlin_generate_example=gremlin_tmpl_num,
- gremlin_prompt=gremlin_prompt,
- max_graph_items=max_graph_items,
- ).merge_dedup_rerank(
- rerank_method=rerank_method,
- near_neighbor_first=near_neighbor_first,
- custom_related_information=custom_related_information,
- topk_return_results=topk_return_results,
- )
- context = rag.run(verbose=True, query=query, graph_search=True)
return context
@@ -390,45 +362,13 @@
gremlin_prompt_input: str,
requested_outputs: Optional[List[str]] = None,
) -> Dict[str, Any]:
- """
- Wraps the gremlin_generate function to return a dictionary of outputs
- based on the requested_outputs list of strings.
- """
- output_keys = [
- "match_result",
- "template_gremlin",
- "raw_gremlin",
- "template_execution_result",
- "raw_execution_result",
- ]
- if not requested_outputs: # None or empty list
- requested_outputs = output_keys
-
- result = gremlin_generate(
- inp, example_num, schema_input, gremlin_prompt_input, requested_outputs
+ response_dict = SchedulerSingleton.get_instance().schedule_flow(
+ FlowName.TEXT2GREMLIN,
+ inp,
+ example_num,
+ schema_input,
+ gremlin_prompt_input,
+ requested_outputs,
)
- outputs_dict: Dict[str, Any] = {}
-
- if not result.success:
- # Handle error case
- if "match_result" in requested_outputs:
- outputs_dict["match_result"] = result.match_result
- if result.error_message:
- outputs_dict["error_detail"] = result.error_message
- return outputs_dict
-
- # Handle successful case
- output_mapping = {
- "match_result": result.match_result,
- "template_gremlin": result.template_gremlin,
- "raw_gremlin": result.raw_gremlin,
- "template_execution_result": result.template_exec_result,
- "raw_execution_result": result.raw_exec_result,
- }
-
- for key in requested_outputs:
- if key in output_mapping:
- outputs_dict[key] = output_mapping[key]
-
- return outputs_dict
+ return response_dict
diff --git a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/vector_graph_block.py b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/vector_graph_block.py
index 56b5de4..84d60df 100644
--- a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/vector_graph_block.py
+++ b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/vector_graph_block.py
@@ -26,6 +26,7 @@
from hugegraph_llm.config import huge_settings
from hugegraph_llm.config import prompt
from hugegraph_llm.config import resource_path
+from hugegraph_llm.flows import FlowName
from hugegraph_llm.flows.scheduler import SchedulerSingleton
from hugegraph_llm.utils.graph_index_utils import (
get_graph_index_info,
@@ -63,12 +64,16 @@
Handles the UI logic for generating a new prompt using the new workflow architecture.
"""
if not all([source_text, scenario, example_name]):
- gr.Warning("Please provide original text, expected scenario, and select an example!")
+ gr.Warning(
+ "Please provide original text, expected scenario, and select an example!"
+ )
return gr.update()
try:
# using new architecture
scheduler = SchedulerSingleton.get_instance()
- result = scheduler.schedule_flow("prompt_generate", source_text, scenario, example_name)
+ result = scheduler.schedule_flow(
+ FlowName.PROMPT_GENERATE, source_text, scenario, example_name
+ )
gr.Info("Prompt generated successfully!")
return result
except Exception as e:
@@ -79,7 +84,9 @@
def load_example_names():
"""Load all candidate examples"""
try:
- examples_path = os.path.join(resource_path, "prompt_examples", "prompt_examples.json")
+ examples_path = os.path.join(
+ resource_path, "prompt_examples", "prompt_examples.json"
+ )
with open(examples_path, "r", encoding="utf-8") as f:
examples = json.load(f)
return [example.get("name", "Unnamed example") for example in examples]
@@ -100,16 +107,22 @@
),
)
if language.upper() == "CN":
- examples_path = os.path.join(resource_path, "prompt_examples", "query_examples_CN.json")
+ examples_path = os.path.join(
+ resource_path, "prompt_examples", "query_examples_CN.json"
+ )
else:
- examples_path = os.path.join(resource_path, "prompt_examples", "query_examples.json")
+ examples_path = os.path.join(
+ resource_path, "prompt_examples", "query_examples.json"
+ )
with open(examples_path, "r", encoding="utf-8") as f:
examples = json.load(f)
return json.dumps(examples, indent=2, ensure_ascii=False)
except (FileNotFoundError, json.JSONDecodeError):
try:
- examples_path = os.path.join(resource_path, "prompt_examples", "query_examples.json")
+ examples_path = os.path.join(
+ resource_path, "prompt_examples", "query_examples.json"
+ )
with open(examples_path, "r", encoding="utf-8") as f:
examples = json.load(f)
return json.dumps(examples, indent=2, ensure_ascii=False)
@@ -120,7 +133,9 @@
def load_schema_fewshot_examples():
"""Load few-shot examples from a JSON file"""
try:
- examples_path = os.path.join(resource_path, "prompt_examples", "schema_examples.json")
+ examples_path = os.path.join(
+ resource_path, "prompt_examples", "schema_examples.json"
+ )
with open(examples_path, "r", encoding="utf-8") as f:
examples = json.load(f)
return json.dumps(examples, indent=2, ensure_ascii=False)
@@ -131,10 +146,14 @@
def update_example_preview(example_name):
"""Update the display content based on the selected example name."""
try:
- examples_path = os.path.join(resource_path, "prompt_examples", "prompt_examples.json")
+ examples_path = os.path.join(
+ resource_path, "prompt_examples", "prompt_examples.json"
+ )
with open(examples_path, "r", encoding="utf-8") as f:
all_examples = json.load(f)
- selected_example = next((ex for ex in all_examples if ex.get("name") == example_name), None)
+ selected_example = next(
+ (ex for ex in all_examples if ex.get("name") == example_name), None
+ )
if selected_example:
return (
@@ -179,7 +198,9 @@
interactive=False,
)
- generate_prompt_btn = gr.Button("🚀 Auto-generate Graph Extract Prompt", variant="primary")
+ generate_prompt_btn = gr.Button(
+ "🚀 Auto-generate Graph Extract Prompt", variant="primary"
+ )
# Bind the change event of the dropdown menu
few_shot_dropdown.change(
fn=update_example_preview,
@@ -271,7 +292,9 @@
lines=15,
max_lines=29,
)
- out = gr.Code(label="Output Info", language="json", elem_classes="code-container-edit")
+ out = gr.Code(
+ label="Output Info", language="json", elem_classes="code-container-edit"
+ )
with gr.Row():
with gr.Accordion("Get RAG Info", open=False):
@@ -280,8 +303,12 @@
graph_index_btn0 = gr.Button("Get Graph Index Info", size="sm")
with gr.Accordion("Clear RAG Data", open=False):
with gr.Column():
- vector_index_btn1 = gr.Button("Clear Chunks Vector Index", size="sm")
- graph_index_btn1 = gr.Button("Clear Graph Vid Vector Index", size="sm")
+ vector_index_btn1 = gr.Button(
+ "Clear Chunks Vector Index", size="sm"
+ )
+ graph_index_btn1 = gr.Button(
+ "Clear Graph Vid Vector Index", size="sm"
+ )
graph_data_btn0 = gr.Button("Clear Graph Data", size="sm")
vector_import_bt = gr.Button("Import into Vector", variant="primary")
@@ -354,9 +381,9 @@
inputs=[input_text, input_schema, info_extract_template],
)
- graph_loading_bt.click(import_graph_data, inputs=[out, input_schema], outputs=[out]).then(
- update_vid_embedding
- ).then(
+ graph_loading_bt.click(
+ import_graph_data, inputs=[out, input_schema], outputs=[out]
+ ).then(update_vid_embedding).then(
store_prompt,
inputs=[input_text, input_schema, info_extract_template],
)
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/__init__.py b/hugegraph-llm/src/hugegraph_llm/flows/__init__.py
index 13a8339..1016680 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/__init__.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/__init__.py
@@ -14,3 +14,21 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+
+from enum import Enum
+
+
+class FlowName(str, Enum):
+ RAG_GRAPH_ONLY = "rag_graph_only"
+ RAG_VECTOR_ONLY = "rag_vector_only"
+ TEXT2GREMLIN = "text2gremlin"
+ BUILD_EXAMPLES_INDEX = "build_examples_index"
+ BUILD_VECTOR_INDEX = "build_vector_index"
+ GRAPH_EXTRACT = "graph_extract"
+ IMPORT_GRAPH_DATA = "import_graph_data"
+ UPDATE_VID_EMBEDDINGS = "update_vid_embeddings"
+ GET_GRAPH_INDEX_INFO = "get_graph_index_info"
+ BUILD_SCHEMA = "build_schema"
+ PROMPT_GENERATE = "prompt_generate"
+ RAG_RAW = "rag_raw"
+ RAG_GRAPH_VECTOR = "rag_graph_vector"
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/build_example_index.py b/hugegraph-llm/src/hugegraph_llm/flows/build_example_index.py
new file mode 100644
index 0000000..d09cc78
--- /dev/null
+++ b/hugegraph-llm/src/hugegraph_llm/flows/build_example_index.py
@@ -0,0 +1,62 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+from typing import List, Dict, Optional
+
+from PyCGraph import GPipeline
+
+from hugegraph_llm.flows.common import BaseFlow
+from hugegraph_llm.state.ai_state import WkFlowInput, WkFlowState
+from hugegraph_llm.nodes.index_node.build_gremlin_example_index import (
+ BuildGremlinExampleIndexNode,
+)
+from hugegraph_llm.utils.log import log
+
+
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
+class BuildExampleIndexFlow(BaseFlow):
+ def __init__(self):
+ pass
+
+ def prepare(
+ self,
+ prepared_input: WkFlowInput,
+ examples: Optional[List[Dict[str, str]]],
+ **kwargs,
+ ):
+ prepared_input.examples = examples
+
+ def build_flow(self, examples=None, **kwargs):
+ pipeline = GPipeline()
+ prepared_input = WkFlowInput()
+ self.prepare(prepared_input, examples=examples)
+
+ pipeline.createGParam(prepared_input, "wkflow_input")
+ pipeline.createGParam(WkFlowState(), "wkflow_state")
+
+ build_node = BuildGremlinExampleIndexNode()
+ pipeline.registerGElement(build_node, set(), "build_examples_index")
+
+ return pipeline
+
+ def post_deal(self, pipeline=None, **kwargs):
+ state_json = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
+ try:
+ formatted_schema = json.dumps(state_json, ensure_ascii=False, indent=2)
+ return formatted_schema
+ except (TypeError, ValueError) as e:
+ log.error("Failed to format schema: %s", e)
+ return str(state_json)
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/build_schema.py b/hugegraph-llm/src/hugegraph_llm/flows/build_schema.py
index 6bbcb85..1554e53 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/build_schema.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/build_schema.py
@@ -13,15 +13,17 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+import json
+
+from PyCGraph import GPipeline
+
from hugegraph_llm.flows.common import BaseFlow
from hugegraph_llm.state.ai_state import WkFlowInput, WkFlowState
from hugegraph_llm.nodes.llm_node.schema_build import SchemaBuildNode
from hugegraph_llm.utils.log import log
-import json
-from PyCGraph import GPipeline
-
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
class BuildSchemaFlow(BaseFlow):
def __init__(self):
pass
@@ -32,15 +34,17 @@
texts=None,
query_examples=None,
few_shot_schema=None,
+ **kwargs,
):
prepared_input.texts = texts
# Optional fields packed into wk_input for SchemaBuildNode
# Keep raw values; node will parse if strings
prepared_input.query_examples = query_examples
prepared_input.few_shot_schema = few_shot_schema
- return
- def build_flow(self, texts=None, query_examples=None, few_shot_schema=None):
+ def build_flow(
+ self, texts=None, query_examples=None, few_shot_schema=None, **kwargs
+ ):
pipeline = GPipeline()
prepared_input = WkFlowInput()
self.prepare(
@@ -58,7 +62,7 @@
return pipeline
- def post_deal(self, pipeline=None):
+ def post_deal(self, pipeline=None, **kwargs):
state_json = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
if "schema" not in state_json:
return ""
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/build_vector_index.py b/hugegraph-llm/src/hugegraph_llm/flows/build_vector_index.py
index 9a07b5d..b57cbfb 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/build_vector_index.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/build_vector_index.py
@@ -13,28 +13,28 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+import json
+
+from PyCGraph import GPipeline
+
from hugegraph_llm.flows.common import BaseFlow
from hugegraph_llm.nodes.document_node.chunk_split import ChunkSplitNode
from hugegraph_llm.nodes.index_node.build_vector_index import BuildVectorIndexNode
from hugegraph_llm.state.ai_state import WkFlowInput
-
-import json
-from PyCGraph import GPipeline
-
from hugegraph_llm.state.ai_state import WkFlowState
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
class BuildVectorIndexFlow(BaseFlow):
def __init__(self):
pass
- def prepare(self, prepared_input: WkFlowInput, texts):
+ def prepare(self, prepared_input: WkFlowInput, texts, **kwargs):
prepared_input.texts = texts
prepared_input.language = "zh"
prepared_input.split_type = "paragraph"
- return
- def build_flow(self, texts):
+ def build_flow(self, texts, **kwargs):
pipeline = GPipeline()
# prepare for workflow input
prepared_input = WkFlowInput()
@@ -50,6 +50,6 @@
return pipeline
- def post_deal(self, pipeline=None):
+ def post_deal(self, pipeline=None, **kwargs):
res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
return json.dumps(res, ensure_ascii=False, indent=2)
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/common.py b/hugegraph-llm/src/hugegraph_llm/flows/common.py
index e234846..d130111 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/common.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/common.py
@@ -26,25 +26,22 @@
"""
@abstractmethod
- def prepare(self, prepared_input: WkFlowInput, *args, **kwargs):
+ def prepare(self, prepared_input: WkFlowInput, **kwargs):
"""
Pre-processing interface.
"""
- pass
@abstractmethod
- def build_flow(self, *args, **kwargs):
+ def build_flow(self, **kwargs):
"""
Interface for building the flow.
"""
- pass
@abstractmethod
- def post_deal(self, *args, **kwargs):
+ def post_deal(self, **kwargs):
"""
Post-processing interface.
"""
- pass
async def post_deal_stream(
self, pipeline=None
@@ -57,15 +54,11 @@
if pipeline is None:
yield {"error": "No pipeline provided"}
return
- try:
- state_json = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
- log.info(f"{flow_name} post processing success")
- stream_flow = state_json.get("stream_generator")
- if stream_flow is None:
- yield {"error": "No stream_generator found in workflow state"}
- return
- async for chunk in stream_flow:
- yield chunk
- except Exception as e:
- log.error(f"{flow_name} post processing failed: {e}")
- yield {"error": f"Post processing failed: {str(e)}"}
+ state_json = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
+ log.info("%s post processing success", flow_name)
+ stream_flow = state_json.get("stream_generator")
+ if stream_flow is None:
+ yield {"error": "No stream_generator found in workflow state"}
+ return
+ async for chunk in stream_flow:
+ yield chunk
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/get_graph_index_info.py b/hugegraph-llm/src/hugegraph_llm/flows/get_graph_index_info.py
index 7d27353..86d08bf 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/get_graph_index_info.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/get_graph_index_info.py
@@ -16,30 +16,32 @@
import json
import os
+from PyCGraph import GPipeline
+
from hugegraph_llm.config import huge_settings, llm_settings, resource_path
from hugegraph_llm.flows.common import BaseFlow
from hugegraph_llm.indices.vector_index import VectorIndex
from hugegraph_llm.models.embeddings.init_embedding import model_map
from hugegraph_llm.state.ai_state import WkFlowInput, WkFlowState
from hugegraph_llm.nodes.hugegraph_node.fetch_graph_data import FetchGraphDataNode
-from PyCGraph import GPipeline
from hugegraph_llm.utils.embedding_utils import (
get_filename_prefix,
get_index_folder_name,
)
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
class GetGraphIndexInfoFlow(BaseFlow):
def __init__(self):
pass
- def prepare(self, prepared_input: WkFlowInput, *args, **kwargs):
+ def prepare(self, prepared_input: WkFlowInput, **kwargs):
return
- def build_flow(self, *args, **kwargs):
+ def build_flow(self, **kwargs):
pipeline = GPipeline()
prepared_input = WkFlowInput()
- self.prepare(prepared_input, *args, **kwargs)
+ self.prepare(prepared_input, **kwargs)
pipeline.createGParam(prepared_input, "wkflow_input")
pipeline.createGParam(WkFlowState(), "wkflow_state")
fetch_node = FetchGraphDataNode()
@@ -48,7 +50,9 @@
def post_deal(self, pipeline=None):
graph_summary_info = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
- folder_name = get_index_folder_name(huge_settings.graph_name, huge_settings.graph_space)
+ folder_name = get_index_folder_name(
+ huge_settings.graph_name, huge_settings.graph_space
+ )
index_dir = str(os.path.join(resource_path, folder_name, "graph_vids"))
filename_prefix = get_filename_prefix(
llm_settings.embedding_type,
@@ -56,7 +60,7 @@
)
try:
vector_index = VectorIndex.from_index_file(index_dir, filename_prefix)
- except FileNotFoundError:
+ except (RuntimeError, OSError):
return json.dumps(graph_summary_info, ensure_ascii=False, indent=2)
graph_summary_info["vid_index"] = {
"embed_dim": vector_index.index.d,
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/graph_extract.py b/hugegraph-llm/src/hugegraph_llm/flows/graph_extract.py
index 55f53b7..f3d1667 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/graph_extract.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/graph_extract.py
@@ -23,25 +23,38 @@
from hugegraph_llm.utils.log import log
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
class GraphExtractFlow(BaseFlow):
def __init__(self):
pass
- def prepare(self, prepared_input: WkFlowInput, schema, texts, example_prompt, extract_type):
+ def prepare(
+ self,
+ prepared_input: WkFlowInput,
+ schema,
+ texts,
+ example_prompt,
+ extract_type,
+ language="zh",
+ **kwargs,
+ ):
# prepare input data
prepared_input.texts = texts
- prepared_input.language = "zh"
+ prepared_input.language = language
prepared_input.split_type = "document"
prepared_input.example_prompt = example_prompt
prepared_input.schema = schema
prepared_input.extract_type = extract_type
- return
- def build_flow(self, schema, texts, example_prompt, extract_type):
+ def build_flow(
+ self, schema, texts, example_prompt, extract_type, language="zh", **kwargs
+ ):
pipeline = GPipeline()
prepared_input = WkFlowInput()
# prepare input data
- self.prepare(prepared_input, schema, texts, example_prompt, extract_type)
+ self.prepare(
+ prepared_input, schema, texts, example_prompt, extract_type, language
+ )
pipeline.createGParam(prepared_input, "wkflow_input")
pipeline.createGParam(WkFlowState(), "wkflow_state")
@@ -57,7 +70,7 @@
return pipeline
- def post_deal(self, pipeline=None):
+ def post_deal(self, pipeline=None, **kwargs):
res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
vertices = res.get("vertices", [])
edges = res.get("edges", [])
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/import_graph_data.py b/hugegraph-llm/src/hugegraph_llm/flows/import_graph_data.py
index 0b29b4e..d0e34ac 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/import_graph_data.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/import_graph_data.py
@@ -24,11 +24,12 @@
from hugegraph_llm.utils.log import log
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
class ImportGraphDataFlow(BaseFlow):
def __init__(self):
pass
- def prepare(self, prepared_input: WkFlowInput, data, schema):
+ def prepare(self, prepared_input: WkFlowInput, data, schema, **kwargs):
try:
data_json = json.loads(data.strip()) if isinstance(data, str) else data
except json.JSONDecodeError as e:
@@ -43,9 +44,8 @@
)
prepared_input.data_json = data_json
prepared_input.schema = schema
- return
- def build_flow(self, data, schema):
+ def build_flow(self, data, schema, **kwargs):
pipeline = GPipeline()
prepared_input = WkFlowInput()
# prepare input data
@@ -61,7 +61,7 @@
return pipeline
- def post_deal(self, pipeline=None):
+ def post_deal(self, pipeline=None, **kwargs):
res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
gr.Info("Import graph data successfully!")
return json.dumps(res, ensure_ascii=False, indent=2)
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/prompt_generate.py b/hugegraph-llm/src/hugegraph_llm/flows/prompt_generate.py
index b4a7bf3..16618e1 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/prompt_generate.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/prompt_generate.py
@@ -13,29 +13,30 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+from PyCGraph import GPipeline
+
from hugegraph_llm.flows.common import BaseFlow
from hugegraph_llm.nodes.llm_node.prompt_generate import PromptGenerateNode
from hugegraph_llm.state.ai_state import WkFlowInput
-
-from PyCGraph import GPipeline
-
from hugegraph_llm.state.ai_state import WkFlowState
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
class PromptGenerateFlow(BaseFlow):
def __init__(self):
pass
- def prepare(self, prepared_input: WkFlowInput, source_text, scenario, example_name):
+ def prepare(
+ self, prepared_input: WkFlowInput, source_text, scenario, example_name, **kwargs
+ ):
"""
Prepare input data for PromptGenerate workflow
"""
prepared_input.source_text = source_text
prepared_input.scenario = scenario
prepared_input.example_name = example_name
- return
- def build_flow(self, source_text, scenario, example_name):
+ def build_flow(self, source_text, scenario, example_name, **kwargs):
"""
Build the PromptGenerate workflow
"""
@@ -53,9 +54,11 @@
return pipeline
- def post_deal(self, pipeline=None):
+ def post_deal(self, pipeline=None, **kwargs):
"""
Process the execution result of PromptGenerate workflow
"""
res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
- return res.get("generated_extract_prompt", "Generation failed. Please check the logs.")
+ return res.get(
+ "generated_extract_prompt", "Generation failed. Please check the logs."
+ )
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_graph_only.py b/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_graph_only.py
index 5feb3d4..3029b62 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_graph_only.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_graph_only.py
@@ -13,11 +13,10 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import json
-from typing import Optional, Literal
+from typing import Optional, Literal, cast
-from PyCGraph import GPipeline
+from PyCGraph import GPipeline, GRegion, GCondition
from hugegraph_llm.flows.common import BaseFlow
from hugegraph_llm.nodes.llm_node.keyword_extract_node import KeywordExtractNode
@@ -31,6 +30,23 @@
from hugegraph_llm.utils.log import log
+class GraphRecallCondition(GCondition):
+ def choose(self):
+ prepared_input: WkFlowInput = cast(
+ WkFlowInput, self.getGParamWithNoEmpty("wkflow_input")
+ )
+ return 0 if prepared_input.is_graph_rag_recall else 1
+
+
+class VectorOnlyCondition(GCondition):
+ def choose(self):
+ prepared_input: WkFlowInput = cast(
+ WkFlowInput, self.getGParamWithNoEmpty("wkflow_input")
+ )
+ return 0 if prepared_input.is_vector_only else 1
+
+
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
class RAGGraphOnlyFlow(BaseFlow):
"""
Workflow for graph-only answering (graph_only_answer)
@@ -40,13 +56,12 @@
self,
prepared_input: WkFlowInput,
query: str,
- vector_search: bool = None,
- graph_search: bool = None,
- raw_answer: bool = None,
- vector_only_answer: bool = None,
- graph_only_answer: bool = None,
- graph_vector_answer: bool = None,
- graph_ratio: float = 0.5,
+ vector_search: bool = False,
+ graph_search: bool = True,
+ raw_answer: bool = False,
+ vector_only_answer: bool = False,
+ graph_only_answer: bool = True,
+ graph_vector_answer: bool = False,
rerank_method: Literal["bleu", "reranker"] = "bleu",
near_neighbor_first: bool = False,
custom_related_information: str = "",
@@ -54,11 +69,13 @@
keywords_extract_prompt: Optional[str] = None,
gremlin_tmpl_num: Optional[int] = -1,
gremlin_prompt: Optional[str] = None,
- max_graph_items: int = None,
- topk_return_results: int = None,
- vector_dis_threshold: float = None,
- topk_per_keyword: int = None,
- **_: dict,
+ max_graph_items: Optional[int] = None,
+ topk_return_results: Optional[int] = None,
+ vector_dis_threshold: Optional[float] = None,
+ topk_per_keyword: Optional[int] = None,
+ is_graph_rag_recall: bool = False,
+ is_vector_only: bool = False,
+ **kwargs,
):
prepared_input.query = query
prepared_input.vector_search = vector_search
@@ -90,13 +107,15 @@
)
prepared_input.schema = huge_settings.graph_name
+ prepared_input.is_graph_rag_recall = is_graph_rag_recall
+ prepared_input.is_vector_only = is_vector_only
prepared_input.data_json = {
"query": query,
"vector_search": vector_search,
"graph_search": graph_search,
"max_graph_items": max_graph_items or huge_settings.max_graph_items,
+ "is_graph_rag_recall": is_graph_rag_recall,
}
- return
def build_flow(self, **kwargs):
pipeline = GPipeline()
@@ -106,48 +125,49 @@
pipeline.createGParam(WkFlowState(), "wkflow_state")
# Create nodes and register them with registerGElement
- only_keyword_extract_node = KeywordExtractNode()
- only_semantic_id_query_node = SemanticIdQueryNode()
- only_schema_node = SchemaNode()
- only_graph_query_node = GraphQueryNode()
- merge_rerank_node = MergeRerankNode()
- answer_synthesize_node = AnswerSynthesizeNode()
+ only_keyword_extract_node = KeywordExtractNode("only_keyword")
+ only_semantic_id_query_node = SemanticIdQueryNode(
+ {only_keyword_extract_node}, "only_semantic"
+ )
+ vector_region: GRegion = GRegion(
+ [only_keyword_extract_node, only_semantic_id_query_node]
+ )
- pipeline.registerGElement(only_keyword_extract_node, set(), "only_keyword")
+ only_schema_node = SchemaNode()
+ schema_node = VectorOnlyCondition([GRegion(), only_schema_node])
+ only_graph_query_node = GraphQueryNode("only_graph")
+ merge_rerank_node = MergeRerankNode({only_graph_query_node}, "merge_rerank")
+ graph_region: GRegion = GRegion([only_graph_query_node, merge_rerank_node])
+ graph_condition_region = VectorOnlyCondition([GRegion(), graph_region])
+
+ answer_synthesize_node = AnswerSynthesizeNode()
+ answer_node = GraphRecallCondition([GRegion(), answer_synthesize_node])
+
+ pipeline.registerGElement(vector_region, set(), "vector_fetch")
+ pipeline.registerGElement(schema_node, set(), "schema_condition")
pipeline.registerGElement(
- only_semantic_id_query_node, {only_keyword_extract_node}, "only_semantic"
- )
- pipeline.registerGElement(only_schema_node, set(), "only_schema")
- pipeline.registerGElement(
- only_graph_query_node,
- {only_schema_node, only_semantic_id_query_node},
- "only_graph",
+ graph_condition_region,
+ {schema_node, vector_region},
+ "graph_condition",
)
pipeline.registerGElement(
- merge_rerank_node, {only_graph_query_node}, "merge_one"
+ answer_node, {graph_condition_region}, "answer_condition"
)
- pipeline.registerGElement(answer_synthesize_node, {merge_rerank_node}, "graph")
log.info("RAGGraphOnlyFlow pipeline built successfully")
return pipeline
- def post_deal(self, pipeline=None):
+ def post_deal(self, pipeline=None, **kwargs):
if pipeline is None:
- return json.dumps(
- {"error": "No pipeline provided"}, ensure_ascii=False, indent=2
- )
- try:
- res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
- log.info("RAGGraphOnlyFlow post processing success")
- return {
+ return {"error": "No pipeline provided"}
+ res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
+ log.info("RAGGraphOnlyFlow post processing success")
+ return (
+ {
"raw_answer": res.get("raw_answer", ""),
"vector_only_answer": res.get("vector_only_answer", ""),
"graph_only_answer": res.get("graph_only_answer", ""),
"graph_vector_answer": res.get("graph_vector_answer", ""),
}
- except Exception as e:
- log.error(f"RAGGraphOnlyFlow post processing failed: {e}")
- return json.dumps(
- {"error": f"Post processing failed: {str(e)}"},
- ensure_ascii=False,
- indent=2,
- )
+ if not res.get("is_graph_rag_recall", False)
+ else res
+ )
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_graph_vector.py b/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_graph_vector.py
index 2f4a2bf..96c4ab8 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_graph_vector.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_graph_vector.py
@@ -13,7 +13,6 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import json
from typing import Optional, Literal
@@ -32,6 +31,7 @@
from hugegraph_llm.utils.log import log
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
class RAGGraphVectorFlow(BaseFlow):
"""
Workflow for graph + vector hybrid answering (graph_vector_answer)
@@ -41,12 +41,12 @@
self,
prepared_input: WkFlowInput,
query: str,
- vector_search: bool = None,
- graph_search: bool = None,
- raw_answer: bool = None,
- vector_only_answer: bool = None,
- graph_only_answer: bool = None,
- graph_vector_answer: bool = None,
+ vector_search: bool = True,
+ graph_search: bool = True,
+ raw_answer: bool = False,
+ vector_only_answer: bool = False,
+ graph_only_answer: bool = False,
+ graph_vector_answer: bool = True,
graph_ratio: float = 0.5,
rerank_method: Literal["bleu", "reranker"] = "bleu",
near_neighbor_first: bool = False,
@@ -55,11 +55,11 @@
keywords_extract_prompt: Optional[str] = None,
gremlin_tmpl_num: Optional[int] = -1,
gremlin_prompt: Optional[str] = None,
- max_graph_items: int = None,
- topk_return_results: int = None,
- vector_dis_threshold: float = None,
- topk_per_keyword: int = None,
- **_: dict,
+ max_graph_items: Optional[int] = None,
+ topk_return_results: Optional[int] = None,
+ vector_dis_threshold: Optional[float] = None,
+ topk_per_keyword: Optional[int] = None,
+ **kwargs,
):
prepared_input.query = query
prepared_input.vector_search = vector_search
@@ -98,7 +98,6 @@
"graph_search": graph_search,
"max_graph_items": max_graph_items or huge_settings.max_graph_items,
}
- return
def build_flow(self, **kwargs):
pipeline = GPipeline()
@@ -135,24 +134,14 @@
log.info("RAGGraphVectorFlow pipeline built successfully")
return pipeline
- def post_deal(self, pipeline=None):
+ def post_deal(self, pipeline=None, **kwargs):
if pipeline is None:
- return json.dumps(
- {"error": "No pipeline provided"}, ensure_ascii=False, indent=2
- )
- try:
- res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
- log.info("RAGGraphVectorFlow post processing success")
- return {
- "raw_answer": res.get("raw_answer", ""),
- "vector_only_answer": res.get("vector_only_answer", ""),
- "graph_only_answer": res.get("graph_only_answer", ""),
- "graph_vector_answer": res.get("graph_vector_answer", ""),
- }
- except Exception as e:
- log.error(f"RAGGraphVectorFlow post processing failed: {e}")
- return json.dumps(
- {"error": f"Post processing failed: {str(e)}"},
- ensure_ascii=False,
- indent=2,
- )
+ return {"error": "No pipeline provided"}
+ res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
+ log.info("RAGGraphVectorFlow post processing success")
+ return {
+ "raw_answer": res.get("raw_answer", ""),
+ "vector_only_answer": res.get("vector_only_answer", ""),
+ "graph_only_answer": res.get("graph_only_answer", ""),
+ "graph_vector_answer": res.get("graph_vector_answer", ""),
+ }
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_raw.py b/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_raw.py
index f62e574..ede8f98 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_raw.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_raw.py
@@ -13,7 +13,6 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import json
from typing import Optional
@@ -26,6 +25,7 @@
from hugegraph_llm.utils.log import log
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
class RAGRawFlow(BaseFlow):
"""
Workflow for basic LLM answering only (raw_answer)
@@ -35,16 +35,16 @@
self,
prepared_input: WkFlowInput,
query: str,
- vector_search: bool = None,
- graph_search: bool = None,
- raw_answer: bool = None,
- vector_only_answer: bool = None,
- graph_only_answer: bool = None,
- graph_vector_answer: bool = None,
+ vector_search: bool = False,
+ graph_search: bool = False,
+ raw_answer: bool = True,
+ vector_only_answer: bool = False,
+ graph_only_answer: bool = False,
+ graph_vector_answer: bool = False,
custom_related_information: str = "",
answer_prompt: Optional[str] = None,
- max_graph_items: int = None,
- **_: dict,
+ max_graph_items: Optional[int] = None,
+ **kwargs,
):
prepared_input.query = query
prepared_input.raw_answer = raw_answer
@@ -61,7 +61,6 @@
"graph_search": graph_search,
"max_graph_items": max_graph_items or huge_settings.max_graph_items,
}
- return
def build_flow(self, **kwargs):
pipeline = GPipeline()
@@ -76,24 +75,14 @@
log.info("RAGRawFlow pipeline built successfully")
return pipeline
- def post_deal(self, pipeline=None):
+ def post_deal(self, pipeline=None, **kwargs):
if pipeline is None:
- return json.dumps(
- {"error": "No pipeline provided"}, ensure_ascii=False, indent=2
- )
- try:
- res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
- log.info("RAGRawFlow post processing success")
- return {
- "raw_answer": res.get("raw_answer", ""),
- "vector_only_answer": res.get("vector_only_answer", ""),
- "graph_only_answer": res.get("graph_only_answer", ""),
- "graph_vector_answer": res.get("graph_vector_answer", ""),
- }
- except Exception as e:
- log.error(f"RAGRawFlow post processing failed: {e}")
- return json.dumps(
- {"error": f"Post processing failed: {str(e)}"},
- ensure_ascii=False,
- indent=2,
- )
+ return {"error": "No pipeline provided"}
+ res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
+ log.info("RAGRawFlow post processing success")
+ return {
+ "raw_answer": res.get("raw_answer", ""),
+ "vector_only_answer": res.get("vector_only_answer", ""),
+ "graph_only_answer": res.get("graph_only_answer", ""),
+ "graph_vector_answer": res.get("graph_vector_answer", ""),
+ }
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_vector_only.py b/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_vector_only.py
index c727eac..150e316 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_vector_only.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/rag_flow_vector_only.py
@@ -13,7 +13,6 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import json
from typing import Optional, Literal
@@ -28,6 +27,7 @@
from hugegraph_llm.utils.log import log
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
class RAGVectorOnlyFlow(BaseFlow):
"""
Workflow for vector-only answering (vector_only_answer)
@@ -37,20 +37,20 @@
self,
prepared_input: WkFlowInput,
query: str,
- vector_search: bool = None,
- graph_search: bool = None,
- raw_answer: bool = None,
- vector_only_answer: bool = None,
- graph_only_answer: bool = None,
- graph_vector_answer: bool = None,
+ vector_search: bool = True,
+ graph_search: bool = False,
+ raw_answer: bool = False,
+ vector_only_answer: bool = True,
+ graph_only_answer: bool = False,
+ graph_vector_answer: bool = False,
rerank_method: Literal["bleu", "reranker"] = "bleu",
near_neighbor_first: bool = False,
custom_related_information: str = "",
answer_prompt: Optional[str] = None,
- max_graph_items: int = None,
- topk_return_results: int = None,
- vector_dis_threshold: float = None,
- **_: dict,
+ max_graph_items: Optional[int] = None,
+ topk_return_results: Optional[int] = None,
+ vector_dis_threshold: Optional[float] = None,
+ **kwargs,
):
prepared_input.query = query
prepared_input.vector_search = vector_search
@@ -77,7 +77,6 @@
"graph_search": graph_search,
"max_graph_items": max_graph_items or huge_settings.max_graph_items,
}
- return
def build_flow(self, **kwargs):
pipeline = GPipeline()
@@ -100,24 +99,14 @@
log.info("RAGVectorOnlyFlow pipeline built successfully")
return pipeline
- def post_deal(self, pipeline=None):
+ def post_deal(self, pipeline=None, **kwargs):
if pipeline is None:
- return json.dumps(
- {"error": "No pipeline provided"}, ensure_ascii=False, indent=2
- )
- try:
- res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
- log.info("RAGVectorOnlyFlow post processing success")
- return {
- "raw_answer": res.get("raw_answer", ""),
- "vector_only_answer": res.get("vector_only_answer", ""),
- "graph_only_answer": res.get("graph_only_answer", ""),
- "graph_vector_answer": res.get("graph_vector_answer", ""),
- }
- except Exception as e:
- log.error(f"RAGVectorOnlyFlow post processing failed: {e}")
- return json.dumps(
- {"error": f"Post processing failed: {str(e)}"},
- ensure_ascii=False,
- indent=2,
- )
+ return {"error": "No pipeline provided"}
+ res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
+ log.info("RAGVectorOnlyFlow post processing success")
+ return {
+ "raw_answer": res.get("raw_answer", ""),
+ "vector_only_answer": res.get("vector_only_answer", ""),
+ "graph_only_answer": res.get("graph_only_answer", ""),
+ "graph_vector_answer": res.get("graph_vector_answer", ""),
+ }
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/scheduler.py b/hugegraph-llm/src/hugegraph_llm/flows/scheduler.py
index 5afa1bf..bdf59d8 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/scheduler.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/scheduler.py
@@ -16,11 +16,13 @@
import threading
from typing import Dict, Any
from PyCGraph import GPipeline, GPipelineManager
+from hugegraph_llm.flows import FlowName
from hugegraph_llm.flows.build_vector_index import BuildVectorIndexFlow
from hugegraph_llm.flows.common import BaseFlow
+from hugegraph_llm.flows.build_example_index import BuildExampleIndexFlow
from hugegraph_llm.flows.graph_extract import GraphExtractFlow
from hugegraph_llm.flows.import_graph_data import ImportGraphDataFlow
-from hugegraph_llm.flows.update_vid_embeddings import UpdateVidEmbeddingsFlows
+from hugegraph_llm.flows.update_vid_embeddings import UpdateVidEmbeddingsFlow
from hugegraph_llm.flows.get_graph_index_info import GetGraphIndexInfoFlow
from hugegraph_llm.flows.build_schema import BuildSchemaFlow
from hugegraph_llm.flows.prompt_generate import PromptGenerateFlow
@@ -34,72 +36,76 @@
class Scheduler:
- pipeline_pool: Dict[str, Any] = None
+ pipeline_pool: Dict[str, Any]
max_pipeline: int
def __init__(self, max_pipeline: int = 10):
self.pipeline_pool = {}
# pipeline_pool act as a manager of GPipelineManager which used for pipeline management
- self.pipeline_pool["build_vector_index"] = {
+ self.pipeline_pool[FlowName.BUILD_VECTOR_INDEX] = {
"manager": GPipelineManager(),
"flow": BuildVectorIndexFlow(),
}
- self.pipeline_pool["graph_extract"] = {
+ self.pipeline_pool[FlowName.GRAPH_EXTRACT] = {
"manager": GPipelineManager(),
"flow": GraphExtractFlow(),
}
- self.pipeline_pool["import_graph_data"] = {
+ self.pipeline_pool[FlowName.IMPORT_GRAPH_DATA] = {
"manager": GPipelineManager(),
"flow": ImportGraphDataFlow(),
}
- self.pipeline_pool["update_vid_embeddings"] = {
+ self.pipeline_pool[FlowName.UPDATE_VID_EMBEDDINGS] = {
"manager": GPipelineManager(),
- "flow": UpdateVidEmbeddingsFlows(),
+ "flow": UpdateVidEmbeddingsFlow(),
}
- self.pipeline_pool["get_graph_index_info"] = {
+ self.pipeline_pool[FlowName.GET_GRAPH_INDEX_INFO] = {
"manager": GPipelineManager(),
"flow": GetGraphIndexInfoFlow(),
}
- self.pipeline_pool["build_schema"] = {
+ self.pipeline_pool[FlowName.BUILD_SCHEMA] = {
"manager": GPipelineManager(),
"flow": BuildSchemaFlow(),
}
- self.pipeline_pool["prompt_generate"] = {
+ self.pipeline_pool[FlowName.PROMPT_GENERATE] = {
"manager": GPipelineManager(),
"flow": PromptGenerateFlow(),
}
- self.pipeline_pool["text2gremlin"] = {
+ self.pipeline_pool[FlowName.TEXT2GREMLIN] = {
"manager": GPipelineManager(),
"flow": Text2GremlinFlow(),
}
# New split rag pipelines
- self.pipeline_pool["rag_raw"] = {
+ self.pipeline_pool[FlowName.RAG_RAW] = {
"manager": GPipelineManager(),
"flow": RAGRawFlow(),
}
- self.pipeline_pool["rag_vector_only"] = {
+ self.pipeline_pool[FlowName.RAG_VECTOR_ONLY] = {
"manager": GPipelineManager(),
"flow": RAGVectorOnlyFlow(),
}
- self.pipeline_pool["rag_graph_only"] = {
+ self.pipeline_pool[FlowName.RAG_GRAPH_ONLY] = {
"manager": GPipelineManager(),
"flow": RAGGraphOnlyFlow(),
}
- self.pipeline_pool["rag_graph_vector"] = {
+ self.pipeline_pool[FlowName.RAG_GRAPH_VECTOR] = {
"manager": GPipelineManager(),
"flow": RAGGraphVectorFlow(),
}
+ self.pipeline_pool[FlowName.BUILD_EXAMPLES_INDEX] = {
+ "manager": GPipelineManager(),
+ "flow": BuildExampleIndexFlow(),
+ }
self.max_pipeline = max_pipeline
# TODO: Implement Agentic Workflow
def agentic_flow(self):
pass
- def schedule_flow(self, flow: str, *args, **kwargs):
- if flow not in self.pipeline_pool:
- raise ValueError(f"Unsupported workflow {flow}")
- manager: GPipelineManager = self.pipeline_pool[flow]["manager"]
- flow: BaseFlow = self.pipeline_pool[flow]["flow"]
+ def schedule_flow(self, flow_name: str, *args, **kwargs):
+ if flow_name not in self.pipeline_pool:
+ raise ValueError(f"Unsupported workflow {flow_name}")
+ manager: GPipelineManager = self.pipeline_pool[flow_name]["manager"]
+ flow: BaseFlow = self.pipeline_pool[flow_name]["flow"]
pipeline: GPipeline = manager.fetch()
if pipeline is None:
# call coresponding flow_func to create new workflow
@@ -111,13 +117,14 @@
raise RuntimeError(error_msg)
status = pipeline.run()
if status.isErr():
+ manager.add(pipeline)
error_msg = f"Error in flow execution: {status.getInfo()}"
log.error(error_msg)
raise RuntimeError(error_msg)
res = flow.post_deal(pipeline)
manager.add(pipeline)
return res
- else:
+ try:
# fetch pipeline & prepare input for flow
prepared_input = pipeline.getGParamWithNoEmpty("wkflow_input")
flow.prepare(prepared_input, *args, **kwargs)
@@ -127,49 +134,46 @@
log.error(error_msg)
raise RuntimeError(error_msg)
res = flow.post_deal(pipeline)
+ finally:
manager.release(pipeline)
- return res
+ return res
- async def schedule_stream_flow(self, flow: str, *args, **kwargs):
- if flow not in self.pipeline_pool:
- raise ValueError(f"Unsupported workflow {flow}")
- manager: GPipelineManager = self.pipeline_pool[flow]["manager"]
- flow: BaseFlow = self.pipeline_pool[flow]["flow"]
+ async def schedule_stream_flow(self, flow_name: str, *args, **kwargs):
+ if flow_name not in self.pipeline_pool:
+ raise ValueError(f"Unsupported workflow {flow_name}")
+ manager: GPipelineManager = self.pipeline_pool[flow_name]["manager"]
+ flow: BaseFlow = self.pipeline_pool[flow_name]["flow"]
pipeline: GPipeline = manager.fetch()
if pipeline is None:
# call coresponding flow_func to create new workflow
pipeline = flow.build_flow(*args, **kwargs)
- try:
- pipeline.getGParamWithNoEmpty("wkflow_input").stream = True
- status = pipeline.init()
- if status.isErr():
- error_msg = f"Error in flow init: {status.getInfo()}"
- log.error(error_msg)
- raise RuntimeError(error_msg)
- status = pipeline.run()
- if status.isErr():
- error_msg = f"Error in flow execution: {status.getInfo()}"
- log.error(error_msg)
- raise RuntimeError(error_msg)
- async for res in flow.post_deal_stream(pipeline):
- yield res
- finally:
+ pipeline.getGParamWithNoEmpty("wkflow_input").stream = True
+ status = pipeline.init()
+ if status.isErr():
+ error_msg = f"Error in flow init: {status.getInfo()}"
+ log.error(error_msg)
+ raise RuntimeError(error_msg)
+ status = pipeline.run()
+ if status.isErr():
manager.add(pipeline)
- else:
- try:
- # fetch pipeline & prepare input for flow
- prepared_input: WkFlowInput = pipeline.getGParamWithNoEmpty(
- "wkflow_input"
- )
- prepared_input.stream = True
- flow.prepare(prepared_input, *args, **kwargs)
- status = pipeline.run()
- if status.isErr():
- raise RuntimeError(f"Error in flow execution {status.getInfo()}")
- async for res in flow.post_deal_stream(pipeline):
- yield res
- finally:
- manager.release(pipeline)
+ error_msg = f"Error in flow execution: {status.getInfo()}"
+ log.error(error_msg)
+ raise RuntimeError(error_msg)
+ async for res in flow.post_deal_stream(pipeline):
+ yield res
+ manager.add(pipeline)
+ try:
+ # fetch pipeline & prepare input for flow
+ prepared_input: WkFlowInput = pipeline.getGParamWithNoEmpty("wkflow_input")
+ prepared_input.stream = True
+ flow.prepare(prepared_input, *args, **kwargs)
+ status = pipeline.run()
+ if status.isErr():
+ raise RuntimeError(f"Error in flow execution {status.getInfo()}")
+ async for res in flow.post_deal_stream(pipeline):
+ yield res
+ finally:
+ manager.release(pipeline)
class SchedulerSingleton:
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/text2gremlin.py b/hugegraph-llm/src/hugegraph_llm/flows/text2gremlin.py
index e9ba427..1ae5662 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/text2gremlin.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/text2gremlin.py
@@ -13,18 +13,21 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+from typing import Any, Dict, List, Optional
+
from PyCGraph import GPipeline
from hugegraph_llm.flows.common import BaseFlow
from hugegraph_llm.state.ai_state import WkFlowInput, WkFlowState
from hugegraph_llm.nodes.hugegraph_node.schema import SchemaNode
-from hugegraph_llm.nodes.index_node.gremlin_example_index_query import GremlinExampleIndexQueryNode
+from hugegraph_llm.nodes.index_node.gremlin_example_index_query import (
+ GremlinExampleIndexQueryNode,
+)
from hugegraph_llm.nodes.llm_node.text2gremlin import Text2GremlinNode
from hugegraph_llm.nodes.hugegraph_node.gremlin_execute import GremlinExecuteNode
-from typing import Any, Dict, List, Optional
-
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
class Text2GremlinFlow(BaseFlow):
def __init__(self):
pass
@@ -37,6 +40,7 @@
schema_input: str,
gremlin_prompt_input: Optional[str],
requested_outputs: Optional[List[str]],
+ **kwargs,
):
# sanitize example_num to [0,10], fallback to 2 if invalid
if not isinstance(example_num, int):
@@ -63,7 +67,6 @@
prepared_input.schema = schema_input
prepared_input.gremlin_prompt = gremlin_prompt_input
prepared_input.requested_outputs = req
- return
def build_flow(
self,
@@ -72,6 +75,7 @@
schema_input: str,
gremlin_prompt_input: Optional[str] = None,
requested_outputs: Optional[List[str]] = None,
+ **kwargs,
):
pipeline = GPipeline()
@@ -100,7 +104,7 @@
return pipeline
- def post_deal(self, pipeline=None) -> Dict[str, Any]:
+ def post_deal(self, pipeline=None, **kwargs) -> Dict[str, Any]:
state = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
# 始终返回 5 个标准键,避免前端因过滤异常看不到字段
return {
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/update_vid_embeddings.py b/hugegraph-llm/src/hugegraph_llm/flows/update_vid_embeddings.py
index b3f0d99..216f356 100644
--- a/hugegraph-llm/src/hugegraph_llm/flows/update_vid_embeddings.py
+++ b/hugegraph-llm/src/hugegraph_llm/flows/update_vid_embeddings.py
@@ -13,18 +13,20 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-from PyCGraph import CStatus, GPipeline
-from hugegraph_llm.flows.common import BaseFlow, WkFlowInput
+from PyCGraph import GPipeline
+
+from hugegraph_llm.flows.common import BaseFlow
from hugegraph_llm.nodes.hugegraph_node.fetch_graph_data import FetchGraphDataNode
from hugegraph_llm.nodes.index_node.build_semantic_index import BuildSemanticIndexNode
-from hugegraph_llm.state.ai_state import WkFlowState
+from hugegraph_llm.state.ai_state import WkFlowState, WkFlowInput
-class UpdateVidEmbeddingsFlows(BaseFlow):
- def prepare(self, prepared_input: WkFlowInput):
- return CStatus()
+# pylint: disable=arguments-differ,keyword-arg-before-vararg
+class UpdateVidEmbeddingsFlow(BaseFlow):
+ def prepare(self, prepared_input: WkFlowInput, **kwargs):
+ pass
- def build_flow(self):
+ def build_flow(self, **kwargs):
pipeline = GPipeline()
prepared_input = WkFlowInput()
# prepare input data
@@ -40,7 +42,7 @@
return pipeline
- def post_deal(self, pipeline):
+ def post_deal(self, pipeline, **kwargs):
res = pipeline.getGParamWithNoEmpty("wkflow_state").to_json()
removed_num = res.get("removed_vid_vector_num", 0)
added_num = res.get("added_vid_vector_num", 0)
diff --git a/hugegraph-llm/src/hugegraph_llm/flows/utils.py b/hugegraph-llm/src/hugegraph_llm/flows/utils.py
deleted file mode 100644
index b4ba05c..0000000
--- a/hugegraph-llm/src/hugegraph_llm/flows/utils.py
+++ /dev/null
@@ -1,34 +0,0 @@
-# Licensed to the Apache Software Foundation (ASF) under one or more
-# contributor license agreements. See the NOTICE file distributed with
-# this work for additional information regarding copyright ownership.
-# The ASF licenses this file to You under the Apache License, Version 2.0
-# (the "License"); you may not use this file except in compliance with
-# the License. You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import json
-
-from hugegraph_llm.state.ai_state import WkFlowInput
-from hugegraph_llm.utils.log import log
-
-
-def prepare_schema(prepared_input: WkFlowInput, schema):
- schema = schema.strip()
- if schema.startswith("{"):
- try:
- schema = json.loads(schema)
- prepared_input.schema = schema
- except json.JSONDecodeError as exc:
- log.error("Invalid JSON format in schema. Please check it again.")
- raise ValueError("Invalid JSON format in schema.") from exc
- else:
- log.info("Get schema '%s' from graphdb.", schema)
- prepared_input.graph_name = schema
- return
diff --git a/hugegraph-llm/src/hugegraph_llm/models/embeddings/init_embedding.py b/hugegraph-llm/src/hugegraph_llm/models/embeddings/init_embedding.py
index 3ad50b3..de04dff 100644
--- a/hugegraph-llm/src/hugegraph_llm/models/embeddings/init_embedding.py
+++ b/hugegraph-llm/src/hugegraph_llm/models/embeddings/init_embedding.py
@@ -29,27 +29,27 @@
}
-def get_embedding(llm_settings: LLMConfig):
- if llm_settings.embedding_type == "openai":
+def get_embedding(llm_configs: LLMConfig):
+ if llm_configs.embedding_type == "openai":
return OpenAIEmbedding(
- model_name=llm_settings.openai_embedding_model,
- api_key=llm_settings.openai_embedding_api_key,
- api_base=llm_settings.openai_embedding_api_base,
+ model_name=llm_configs.openai_embedding_model,
+ api_key=llm_configs.openai_embedding_api_key,
+ api_base=llm_configs.openai_embedding_api_base,
)
- if llm_settings.embedding_type == "ollama/local":
+ if llm_configs.embedding_type == "ollama/local":
return OllamaEmbedding(
- model_name=llm_settings.ollama_embedding_model,
- host=llm_settings.ollama_embedding_host,
- port=llm_settings.ollama_embedding_port,
+ model_name=llm_configs.ollama_embedding_model,
+ host=llm_configs.ollama_embedding_host,
+ port=llm_configs.ollama_embedding_port,
)
- if llm_settings.embedding_type == "litellm":
+ if llm_configs.embedding_type == "litellm":
return LiteLLMEmbedding(
- model_name=llm_settings.litellm_embedding_model,
- api_key=llm_settings.litellm_embedding_api_key,
- api_base=llm_settings.litellm_embedding_api_base,
+ model_name=llm_configs.litellm_embedding_model,
+ api_key=llm_configs.litellm_embedding_api_key,
+ api_base=llm_configs.litellm_embedding_api_base,
)
- raise Exception("embedding type is not supported !")
+ raise ValueError("embedding type is not supported !")
class Embeddings:
diff --git a/hugegraph-llm/src/hugegraph_llm/models/llms/init_llm.py b/hugegraph-llm/src/hugegraph_llm/models/llms/init_llm.py
index 9121fca..a13641d 100644
--- a/hugegraph-llm/src/hugegraph_llm/models/llms/init_llm.py
+++ b/hugegraph-llm/src/hugegraph_llm/models/llms/init_llm.py
@@ -22,74 +22,74 @@
from hugegraph_llm.config import llm_settings
-def get_chat_llm(llm_settings: LLMConfig):
- if llm_settings.chat_llm_type == "openai":
+def get_chat_llm(llm_configs: LLMConfig):
+ if llm_configs.chat_llm_type == "openai":
return OpenAIClient(
- api_key=llm_settings.openai_chat_api_key,
- api_base=llm_settings.openai_chat_api_base,
- model_name=llm_settings.openai_chat_language_model,
- max_tokens=llm_settings.openai_chat_tokens,
+ api_key=llm_configs.openai_chat_api_key,
+ api_base=llm_configs.openai_chat_api_base,
+ model_name=llm_configs.openai_chat_language_model,
+ max_tokens=llm_configs.openai_chat_tokens,
)
- if llm_settings.chat_llm_type == "ollama/local":
+ if llm_configs.chat_llm_type == "ollama/local":
return OllamaClient(
- model=llm_settings.ollama_chat_language_model,
- host=llm_settings.ollama_chat_host,
- port=llm_settings.ollama_chat_port,
+ model=llm_configs.ollama_chat_language_model,
+ host=llm_configs.ollama_chat_host,
+ port=llm_configs.ollama_chat_port,
)
- if llm_settings.chat_llm_type == "litellm":
+ if llm_configs.chat_llm_type == "litellm":
return LiteLLMClient(
- api_key=llm_settings.litellm_chat_api_key,
- api_base=llm_settings.litellm_chat_api_base,
- model_name=llm_settings.litellm_chat_language_model,
- max_tokens=llm_settings.litellm_chat_tokens,
+ api_key=llm_configs.litellm_chat_api_key,
+ api_base=llm_configs.litellm_chat_api_base,
+ model_name=llm_configs.litellm_chat_language_model,
+ max_tokens=llm_configs.litellm_chat_tokens,
)
raise Exception("chat llm type is not supported !")
-def get_extract_llm(llm_settings: LLMConfig):
- if llm_settings.extract_llm_type == "openai":
+def get_extract_llm(llm_configs: LLMConfig):
+ if llm_configs.extract_llm_type == "openai":
return OpenAIClient(
- api_key=llm_settings.openai_extract_api_key,
- api_base=llm_settings.openai_extract_api_base,
- model_name=llm_settings.openai_extract_language_model,
- max_tokens=llm_settings.openai_extract_tokens,
+ api_key=llm_configs.openai_extract_api_key,
+ api_base=llm_configs.openai_extract_api_base,
+ model_name=llm_configs.openai_extract_language_model,
+ max_tokens=llm_configs.openai_extract_tokens,
)
- if llm_settings.extract_llm_type == "ollama/local":
+ if llm_configs.extract_llm_type == "ollama/local":
return OllamaClient(
- model=llm_settings.ollama_extract_language_model,
- host=llm_settings.ollama_extract_host,
- port=llm_settings.ollama_extract_port,
+ model=llm_configs.ollama_extract_language_model,
+ host=llm_configs.ollama_extract_host,
+ port=llm_configs.ollama_extract_port,
)
- if llm_settings.extract_llm_type == "litellm":
+ if llm_configs.extract_llm_type == "litellm":
return LiteLLMClient(
- api_key=llm_settings.litellm_extract_api_key,
- api_base=llm_settings.litellm_extract_api_base,
- model_name=llm_settings.litellm_extract_language_model,
- max_tokens=llm_settings.litellm_extract_tokens,
+ api_key=llm_configs.litellm_extract_api_key,
+ api_base=llm_configs.litellm_extract_api_base,
+ model_name=llm_configs.litellm_extract_language_model,
+ max_tokens=llm_configs.litellm_extract_tokens,
)
raise Exception("extract llm type is not supported !")
-def get_text2gql_llm(llm_settings: LLMConfig):
- if llm_settings.text2gql_llm_type == "openai":
+def get_text2gql_llm(llm_configs: LLMConfig):
+ if llm_configs.text2gql_llm_type == "openai":
return OpenAIClient(
- api_key=llm_settings.openai_text2gql_api_key,
- api_base=llm_settings.openai_text2gql_api_base,
- model_name=llm_settings.openai_text2gql_language_model,
- max_tokens=llm_settings.openai_text2gql_tokens,
+ api_key=llm_configs.openai_text2gql_api_key,
+ api_base=llm_configs.openai_text2gql_api_base,
+ model_name=llm_configs.openai_text2gql_language_model,
+ max_tokens=llm_configs.openai_text2gql_tokens,
)
- if llm_settings.text2gql_llm_type == "ollama/local":
+ if llm_configs.text2gql_llm_type == "ollama/local":
return OllamaClient(
- model=llm_settings.ollama_text2gql_language_model,
- host=llm_settings.ollama_text2gql_host,
- port=llm_settings.ollama_text2gql_port,
+ model=llm_configs.ollama_text2gql_language_model,
+ host=llm_configs.ollama_text2gql_host,
+ port=llm_configs.ollama_text2gql_port,
)
- if llm_settings.text2gql_llm_type == "litellm":
+ if llm_configs.text2gql_llm_type == "litellm":
return LiteLLMClient(
- api_key=llm_settings.litellm_text2gql_api_key,
- api_base=llm_settings.litellm_text2gql_api_base,
- model_name=llm_settings.litellm_text2gql_language_model,
- max_tokens=llm_settings.litellm_text2gql_tokens,
+ api_key=llm_configs.litellm_text2gql_api_key,
+ api_base=llm_configs.litellm_text2gql_api_base,
+ model_name=llm_configs.litellm_text2gql_language_model,
+ max_tokens=llm_configs.litellm_text2gql_tokens,
)
raise Exception("text2gql llm type is not supported !")
@@ -173,4 +173,8 @@
if __name__ == "__main__":
client = LLMs().get_chat_llm()
print(client.generate(prompt="What is the capital of China?"))
- print(client.generate(messages=[{"role": "user", "content": "What is the capital of China?"}]))
+ print(
+ client.generate(
+ messages=[{"role": "user", "content": "What is the capital of China?"}]
+ )
+ )
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/base_node.py b/hugegraph-llm/src/hugegraph_llm/nodes/base_node.py
index f901673..d7e53d4 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/base_node.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/base_node.py
@@ -13,14 +13,26 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+from typing import Dict, Optional
from PyCGraph import GNode, CStatus
from hugegraph_llm.nodes.util import init_context
from hugegraph_llm.state.ai_state import WkFlowInput, WkFlowState
+from hugegraph_llm.utils.log import log
class BaseNode(GNode):
- context: WkFlowState = None
- wk_input: WkFlowInput = None
+ """
+ Base class for workflow nodes, providing context management and operation scheduling.
+
+ All custom nodes should inherit from this class and implement the operator_schedule method.
+
+ Attributes:
+ context: Shared workflow state
+ wk_input: Workflow input parameters
+ """
+
+ context: Optional[WkFlowState] = None
+ wk_input: Optional[WkFlowInput] = None
def init(self):
return init_context(self)
@@ -30,6 +42,8 @@
Node initialization method, can be overridden by subclasses.
Returns a CStatus object indicating whether initialization succeeded.
"""
+ if self.wk_input is None or self.context is None:
+ return CStatus(-1, "wk_input or context not initialized")
if self.wk_input.data_json is not None:
self.context.assign_from_json(self.wk_input.data_json)
self.wk_input.data_json = None
@@ -43,6 +57,8 @@
sts = self.node_init()
if sts.isErr():
return sts
+ if self.context is None:
+ return CStatus(-1, "Context not initialized")
self.context.lock()
try:
data_json = self.context.to_json()
@@ -51,24 +67,35 @@
try:
res = self.operator_schedule(data_json)
- except Exception as exc:
+ except (ValueError, TypeError, KeyError, NotImplementedError) as exc:
import traceback
node_info = f"Node type: {type(self).__name__}, Node object: {self}"
err_msg = f"Node failed: {exc}\n{node_info}\n{traceback.format_exc()}"
return CStatus(-1, err_msg)
+ # For unexpected exceptions, re-raise to let them propagate or be caught elsewhere
self.context.lock()
try:
- if isinstance(res, dict):
+ if res is not None and isinstance(res, dict):
self.context.assign_from_json(res)
+ elif res is not None:
+ log.warning("operator_schedule returned non-dict type: %s", type(res))
finally:
self.context.unlock()
return CStatus()
- def operator_schedule(self, data_json):
+ def operator_schedule(self, data_json) -> Optional[Dict]:
"""
- Interface for scheduling the operator, can be overridden by subclasses.
- Returns a CStatus object indicating whether scheduling succeeded.
+ Operation scheduling method that must be implemented by subclasses.
+
+ Args:
+ data_json: Context serialized as JSON data
+
+ Returns:
+ Dictionary of processing results, or None to indicate no update
+
+ Raises:
+ NotImplementedError: If the subclass has not implemented this method
"""
- pass
+ raise NotImplementedError("Subclasses must implement operator_schedule")
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/common_node/merge_rerank_node.py b/hugegraph-llm/src/hugegraph_llm/nodes/common_node/merge_rerank_node.py
index 78f53e2..c718086 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/common_node/merge_rerank_node.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/common_node/merge_rerank_node.py
@@ -52,8 +52,8 @@
topk_return_results=topk_return_results,
)
return super().node_init()
- except Exception as e:
- log.error(f"Failed to initialize MergeRerankNode: {e}")
+ except ValueError as e:
+ log.error("Failed to initialize MergeRerankNode: %s", e)
from PyCGraph import CStatus
return CStatus(-1, f"MergeRerankNode initialization failed: {e}")
@@ -72,12 +72,14 @@
merged_count = len(result.get("merged_result", []))
log.info(
- f"Merge and rerank completed: {vector_count} vector results, "
- f"{graph_count} graph results, {merged_count} merged results"
+ "Merge and rerank completed: %d vector results, %d graph results, %d merged results",
+ vector_count,
+ graph_count,
+ merged_count,
)
return result
- except Exception as e:
- log.error(f"Merge and rerank failed: {e}")
+ except ValueError as e:
+ log.error("Merge and rerank failed: %s", e)
return data_json
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/document_node/chunk_split.py b/hugegraph-llm/src/hugegraph_llm/nodes/document_node/chunk_split.py
index f71bd7b..883cc90 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/document_node/chunk_split.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/document_node/chunk_split.py
@@ -13,8 +13,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-from hugegraph_llm.nodes.base_node import BaseNode
from PyCGraph import CStatus
+from hugegraph_llm.nodes.base_node import BaseNode
from hugegraph_llm.operators.document_op.chunk_split import ChunkSplit
from hugegraph_llm.state.ai_state import WkFlowInput, WkFlowState
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/fetch_graph_data.py b/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/fetch_graph_data.py
index 99b428e..6e9dd01 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/fetch_graph_data.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/fetch_graph_data.py
@@ -13,6 +13,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+from typing import Optional
+
from hugegraph_llm.nodes.base_node import BaseNode
from hugegraph_llm.operators.hugegraph_op.fetch_graph_data import FetchGraphData
from hugegraph_llm.state.ai_state import WkFlowInput, WkFlowState
@@ -21,11 +23,12 @@
class FetchGraphDataNode(BaseNode):
fetch_graph_data_op: FetchGraphData
- context: WkFlowState = None
- wk_input: WkFlowInput = None
+ context: Optional[WkFlowState] = None
+ wk_input: Optional[WkFlowInput] = None
def node_init(self):
- self.fetch_graph_data_op = FetchGraphData(get_hg_client())
+ client = get_hg_client()
+ self.fetch_graph_data_op = FetchGraphData(client)
return super().node_init()
def operator_schedule(self, data_json):
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/graph_query_node.py b/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/graph_query_node.py
index ae65ccb..c9d62a9 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/graph_query_node.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/graph_query_node.py
@@ -13,12 +13,62 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-from PyCGraph import CStatus
-from typing import Dict, Any
+import json
+from typing import Dict, Any, Tuple, List, Set, Optional
+
from hugegraph_llm.nodes.base_node import BaseNode
-from hugegraph_llm.operators.hugegraph_op.graph_rag_query import GraphRAGQuery
from hugegraph_llm.config import huge_settings, prompt
+from hugegraph_llm.operators.operator_list import OperatorList
from hugegraph_llm.utils.log import log
+from pyhugegraph.client import PyHugeClient
+
+# TODO: remove 'as('subj)' step
+VERTEX_QUERY_TPL = "g.V({keywords}).limit(8).as('subj').toList()"
+
+# TODO: we could use a simpler query (like kneighbor-api to get the edges)
+# TODO: test with profile()/explain() to speed up the query
+VID_QUERY_NEIGHBOR_TPL = """\
+g.V({keywords})
+.repeat(
+ bothE({edge_labels}).limit({edge_limit}).otherV().dedup()
+).times({max_deep}).emit()
+.simplePath()
+.path()
+.by(project('label', 'id', 'props')
+ .by(label())
+ .by(id())
+ .by(valueMap().by(unfold()))
+)
+.by(project('label', 'inV', 'outV', 'props')
+ .by(label())
+ .by(inV().id())
+ .by(outV().id())
+ .by(valueMap().by(unfold()))
+)
+.limit({max_items})
+.toList()
+"""
+
+PROPERTY_QUERY_NEIGHBOR_TPL = """\
+g.V().has('{prop}', within({keywords}))
+.repeat(
+ bothE({edge_labels}).limit({edge_limit}).otherV().dedup()
+).times({max_deep}).emit()
+.simplePath()
+.path()
+.by(project('label', 'props')
+ .by(label())
+ .by(valueMap().by(unfold()))
+)
+.by(project('label', 'inV', 'outV', 'props')
+ .by(label())
+ .by(inV().values('{prop}'))
+ .by(outV().values('{prop}'))
+ .by(valueMap().by(unfold()))
+)
+.limit({max_items})
+.toList()
+"""
class GraphQueryNode(BaseNode):
@@ -26,45 +76,395 @@
Graph query node, responsible for retrieving relevant information from the graph database.
"""
- graph_rag_query: GraphRAGQuery
+ _client: Optional[PyHugeClient] = None
+ _max_deep: Optional[int] = None
+ _max_items: Optional[int] = None
+ _prop_to_match: Optional[str] = None
+ _num_gremlin_generate_example: int = -1
+ gremlin_prompt: str = ""
+ _limit_property: bool = False
+ _max_v_prop_len: int = 2048
+ _max_e_prop_len: int = 256
+ _schema: str = ""
+ operator_list: Optional[OperatorList] = None
def node_init(self):
"""
Initialize the graph query operator.
"""
+ self._client: PyHugeClient = PyHugeClient(
+ url=huge_settings.graph_url,
+ graph=huge_settings.graph_name,
+ user=huge_settings.graph_user,
+ pwd=huge_settings.graph_pwd,
+ graphspace=huge_settings.graph_space,
+ )
+ self._max_deep = self.wk_input.max_deep or 2
+ self._max_items = self.wk_input.max_graph_items or huge_settings.max_graph_items
+ self._prop_to_match = self.wk_input.prop_to_match
+ self._num_gremlin_generate_example = (
+ self.wk_input.gremlin_tmpl_num
+ if self.wk_input.gremlin_tmpl_num is not None
+ else -1
+ )
+ self.gremlin_prompt = (
+ self.wk_input.gremlin_prompt or prompt.gremlin_generate_prompt
+ )
+ self._limit_property = huge_settings.limit_property.lower() == "true"
+ self._max_v_prop_len = self.wk_input.max_v_prop_len or 2048
+ self._max_e_prop_len = self.wk_input.max_e_prop_len or 256
+ self._schema = ""
+ self.operator_list = OperatorList(None, None)
+
+ return super().node_init()
+
+ # TODO: move this method to a util file for reuse (remove self param)
+ def init_client(self, context):
+ """Initialize the HugeGraph client from context or default settings."""
+ # pylint: disable=R0915 (too-many-statements)
+ if self._client is None:
+ if isinstance(context.get("graph_client"), PyHugeClient):
+ self._client = context["graph_client"]
+ else:
+ url = context.get("url") or "http://localhost:8080"
+ graph = context.get("graph") or "hugegraph"
+ user = context.get("user") or "admin"
+ pwd = context.get("pwd") or "admin"
+ gs = context.get("graphspace") or None
+ self._client = PyHugeClient(url, graph, user, pwd, gs)
+ assert self._client is not None, "No valid graph to search."
+
+ def _gremlin_generate_query(self, context: Dict[str, Any]) -> Dict[str, Any]:
+ query = context["query"]
+ vertices = context.get("match_vids")
+ query_embedding = context.get("query_embedding")
+
+ self.operator_list.clear()
+ self.operator_list.example_index_query(
+ num_examples=self._num_gremlin_generate_example
+ )
+ gremlin_response = self.operator_list.gremlin_generate_synthesize(
+ context["simple_schema"],
+ vertices=vertices,
+ gremlin_prompt=self.gremlin_prompt,
+ ).run(query=query, query_embedding=query_embedding)
+ if self._num_gremlin_generate_example > 0:
+ gremlin = gremlin_response["result"]
+ else:
+ gremlin = gremlin_response["raw_result"]
+ log.info("Generated gremlin: %s", gremlin)
+ context["gremlin"] = gremlin
try:
- graph_name = huge_settings.graph_name
- if not graph_name:
- return CStatus(-1, "graph_name is required in wk_input")
+ result = self._client.gremlin().exec(gremlin=gremlin)["data"]
+ if result == [None]:
+ result = []
+ context["graph_result"] = [
+ json.dumps(item, ensure_ascii=False) for item in result
+ ]
+ if context["graph_result"]:
+ context["graph_result_flag"] = 1
+ context["graph_context_head"] = (
+ f"The following are graph query result "
+ f"from gremlin query `{gremlin}`.\n"
+ )
+ except Exception as e: # pylint: disable=broad-except,broad-exception-caught
+ log.error(e)
+ context["graph_result"] = []
+ return context
- max_deep = self.wk_input.max_deep or 2
- max_graph_items = (
- self.wk_input.max_graph_items or huge_settings.max_graph_items
+ def _limit_property_query(
+ self, value: Optional[str], item_type: str
+ ) -> Optional[str]:
+ # NOTE: we skip the filter for list/set type (e.g., list of string, add it if needed)
+ if not self._limit_property or not isinstance(value, str):
+ return value
+
+ max_len = self._max_v_prop_len if item_type == "v" else self._max_e_prop_len
+ return value[:max_len] if value else value
+
+ def _process_vertex(
+ self,
+ item: Any,
+ flat_rel: str,
+ node_cache: Set[str],
+ prior_edge_str_len: int,
+ depth: int,
+ nodes_with_degree: List[str],
+ use_id_to_match: bool,
+ v_cache: Set[str],
+ ) -> Tuple[str, int, int]:
+ matched_str = (
+ item["id"] if use_id_to_match else item["props"][self._prop_to_match]
+ )
+ if matched_str in node_cache:
+ flat_rel = flat_rel[:-prior_edge_str_len]
+ return flat_rel, prior_edge_str_len, depth
+
+ node_cache.add(matched_str)
+ props_str = ", ".join(
+ f"{k}: {self._limit_property_query(v, 'v')}"
+ for k, v in item["props"].items()
+ if v
+ )
+
+ # TODO: we may remove label id or replace with label name
+ if matched_str in v_cache:
+ node_str = matched_str
+ else:
+ v_cache.add(matched_str)
+ node_str = f"{item['id']}{{{props_str}}}"
+
+ flat_rel += node_str
+ nodes_with_degree.append(node_str)
+ depth += 1
+ return flat_rel, prior_edge_str_len, depth
+
+ def _process_edge(
+ self,
+ item: Any,
+ path_str: str,
+ raw_flat_rel: List[Any],
+ i: int,
+ use_id_to_match: bool,
+ e_cache: Set[Tuple[str, str, str]],
+ ) -> Tuple[str, int]:
+ props_str = ", ".join(
+ f"{k}: {self._limit_property_query(v, 'e')}"
+ for k, v in item["props"].items()
+ if v
+ )
+ props_str = f"{{{props_str}}}" if props_str else ""
+ prev_matched_str = (
+ raw_flat_rel[i - 1]["id"]
+ if use_id_to_match
+ else (raw_flat_rel)[i - 1]["props"][self._prop_to_match]
+ )
+
+ edge_key = (item["inV"], item["label"], item["outV"])
+ if edge_key not in e_cache:
+ e_cache.add(edge_key)
+ edge_label = f"{item['label']}{props_str}"
+ else:
+ edge_label = item["label"]
+
+ edge_str = (
+ f"--[{edge_label}]-->"
+ if item["outV"] == prev_matched_str
+ else f"<--[{edge_label}]--"
+ )
+ path_str += edge_str
+ prior_edge_str_len = len(edge_str)
+ return path_str, prior_edge_str_len
+
+ def _process_path(
+ self,
+ path: Any,
+ use_id_to_match: bool,
+ v_cache: Set[str],
+ e_cache: Set[Tuple[str, str, str]],
+ ) -> Tuple[str, List[str]]:
+ flat_rel = ""
+ raw_flat_rel = path["objects"]
+ assert len(raw_flat_rel) % 2 == 1, "The length of raw_flat_rel should be odd."
+
+ node_cache = set()
+ prior_edge_str_len = 0
+ depth = 0
+ nodes_with_degree = []
+
+ for i, item in enumerate(raw_flat_rel):
+ if i % 2 == 0:
+ # Process each vertex
+ flat_rel, prior_edge_str_len, depth = self._process_vertex(
+ item,
+ flat_rel,
+ node_cache,
+ prior_edge_str_len,
+ depth,
+ nodes_with_degree,
+ use_id_to_match,
+ v_cache,
+ )
+ else:
+ # Process each edge
+ flat_rel, prior_edge_str_len = self._process_edge(
+ item, flat_rel, raw_flat_rel, i, use_id_to_match, e_cache
+ )
+
+ return flat_rel, nodes_with_degree
+
+ def _update_vertex_degree_list(
+ self, vertex_degree_list: List[Set[str]], nodes_with_degree: List[str]
+ ) -> None:
+ for depth, node_str in enumerate(nodes_with_degree):
+ if depth >= len(vertex_degree_list):
+ vertex_degree_list.append(set())
+ vertex_degree_list[depth].add(node_str)
+
+ def _format_graph_query_result(
+ self, query_paths
+ ) -> Tuple[Set[str], List[Set[str]], Dict[str, List[str]]]:
+ use_id_to_match = self._prop_to_match is None
+ subgraph = set()
+ subgraph_with_degree = {}
+ vertex_degree_list: List[Set[str]] = []
+ v_cache: Set[str] = set()
+ e_cache: Set[Tuple[str, str, str]] = set()
+
+ for path in query_paths:
+ # 1. Process each path
+ path_str, vertex_with_degree = self._process_path(
+ path, use_id_to_match, v_cache, e_cache
)
- max_v_prop_len = self.wk_input.max_v_prop_len or 2048
- max_e_prop_len = self.wk_input.max_e_prop_len or 256
- prop_to_match = self.wk_input.prop_to_match
- num_gremlin_generate_example = self.wk_input.gremlin_tmpl_num or -1
- gremlin_prompt = (
- self.wk_input.gremlin_prompt or prompt.gremlin_generate_prompt
+ subgraph.add(path_str)
+ subgraph_with_degree[path_str] = vertex_with_degree
+ # 2. Update vertex degree list
+ self._update_vertex_degree_list(vertex_degree_list, vertex_with_degree)
+
+ return subgraph, vertex_degree_list, subgraph_with_degree
+
+ def _get_graph_schema(self, refresh: bool = False) -> str:
+ if self._schema and not refresh:
+ return self._schema
+
+ schema = self._client.schema()
+ vertex_schema = schema.getVertexLabels()
+ edge_schema = schema.getEdgeLabels()
+ relationships = schema.getRelations()
+
+ self._schema = (
+ f"Vertex properties: {vertex_schema}\n"
+ f"Edge properties: {edge_schema}\n"
+ f"Relationships: {relationships}\n"
+ )
+ log.debug("Link(Relation): %s", relationships)
+ return self._schema
+
+ @staticmethod
+ def _extract_label_names(
+ source: str, head: str = "name: ", tail: str = ", "
+ ) -> List[str]:
+ result = []
+ for s in source.split(head):
+ end = s.find(tail)
+ label = s[:end]
+ if label:
+ result.append(label)
+ return result
+
+ def _extract_labels_from_schema(self) -> Tuple[List[str], List[str]]:
+ schema = self._get_graph_schema()
+ vertex_props_str, edge_props_str = schema.split("\n")[:2]
+ # TODO: rename to vertex (also need update in the schema)
+ vertex_props_str = (
+ vertex_props_str[len("Vertex properties: ") :].strip("[").strip("]")
+ )
+ edge_props_str = (
+ edge_props_str[len("Edge properties: ") :].strip("[").strip("]")
+ )
+ vertex_labels = self._extract_label_names(vertex_props_str)
+ edge_labels = self._extract_label_names(edge_props_str)
+ return vertex_labels, edge_labels
+
+ def _format_graph_from_vertex(self, query_result: List[Any]) -> Set[str]:
+ knowledge = set()
+ for item in query_result:
+ props_str = ", ".join(f"{k}: {v}" for k, v in item["properties"].items())
+ node_str = f"{item['id']}{{{props_str}}}"
+ knowledge.add(node_str)
+ return knowledge
+
+ def _subgraph_query(self, context: Dict[str, Any]) -> Dict[str, Any]:
+ # 1. Extract params from context
+ matched_vids = context.get("match_vids")
+ if isinstance(context.get("max_deep"), int):
+ self._max_deep = context["max_deep"]
+ if isinstance(context.get("max_items"), int):
+ self._max_items = context["max_items"]
+ if isinstance(context.get("prop_to_match"), str):
+ self._prop_to_match = context["prop_to_match"]
+
+ # 2. Extract edge_labels from graph schema
+ _, edge_labels = self._extract_labels_from_schema()
+ edge_labels_str = ",".join("'" + label + "'" for label in edge_labels)
+ # TODO: enhance the limit logic later
+ edge_limit_amount = len(edge_labels) * huge_settings.edge_limit_pre_label
+
+ use_id_to_match = self._prop_to_match is None
+ if use_id_to_match:
+ if not matched_vids:
+ return context
+
+ gremlin_query = VERTEX_QUERY_TPL.format(keywords=matched_vids)
+ vertexes = self._client.gremlin().exec(gremlin=gremlin_query)["data"]
+ log.debug("Vids gremlin query: %s", gremlin_query)
+
+ vertex_knowledge = self._format_graph_from_vertex(query_result=vertexes)
+ paths: List[Any] = []
+ # TODO: use generator or asyncio to speed up the query logic
+ for matched_vid in matched_vids:
+ gremlin_query = VID_QUERY_NEIGHBOR_TPL.format(
+ keywords=f"'{matched_vid}'",
+ max_deep=self._max_deep,
+ edge_labels=edge_labels_str,
+ edge_limit=edge_limit_amount,
+ max_items=self._max_items,
+ )
+ log.debug("Kneighbor gremlin query: %s", gremlin_query)
+ paths.extend(self._client.gremlin().exec(gremlin=gremlin_query)["data"])
+
+ (
+ graph_chain_knowledge,
+ vertex_degree_list,
+ knowledge_with_degree,
+ ) = self._format_graph_query_result(query_paths=paths)
+
+ # TODO: we may need to optimize the logic here with global deduplication (may lack some single vertex)
+ if not graph_chain_knowledge:
+ graph_chain_knowledge.update(vertex_knowledge)
+ if vertex_degree_list:
+ vertex_degree_list[0].update(vertex_knowledge)
+ else:
+ vertex_degree_list.append(vertex_knowledge)
+ else:
+ # WARN: When will the query enter here?
+ keywords = context.get("keywords")
+ assert keywords, "No related property(keywords) for graph query."
+ keywords_str = ",".join("'" + kw + "'" for kw in keywords)
+ gremlin_query = PROPERTY_QUERY_NEIGHBOR_TPL.format(
+ prop=self._prop_to_match,
+ keywords=keywords_str,
+ edge_labels=edge_labels_str,
+ edge_limit=edge_limit_amount,
+ max_deep=self._max_deep,
+ max_items=self._max_items,
+ )
+ log.warning(
+ "Unable to find vid, downgraded to property query, please confirm if it meets expectation."
)
- # Initialize GraphRAGQuery operator
- self.graph_rag_query = GraphRAGQuery(
- max_deep=max_deep,
- max_graph_items=max_graph_items,
- max_v_prop_len=max_v_prop_len,
- max_e_prop_len=max_e_prop_len,
- prop_to_match=prop_to_match,
- num_gremlin_generate_example=num_gremlin_generate_example,
- gremlin_prompt=gremlin_prompt,
+ paths: List[Any] = self._client.gremlin().exec(gremlin=gremlin_query)[
+ "data"
+ ]
+ (
+ graph_chain_knowledge,
+ vertex_degree_list,
+ knowledge_with_degree,
+ ) = self._format_graph_query_result(query_paths=paths)
+
+ context["graph_result"] = list(graph_chain_knowledge)
+ if context["graph_result"]:
+ context["graph_result_flag"] = 0
+ context["vertex_degree_list"] = [
+ list(vertex_degree) for vertex_degree in vertex_degree_list
+ ]
+ context["knowledge_with_degree"] = knowledge_with_degree
+ context["graph_context_head"] = (
+ f"The following are graph knowledge in {self._max_deep} depth, e.g:\n"
+ "`vertexA--[links]-->vertexB<--[links]--vertexC ...`"
+ "extracted based on key entities as subject:\n"
)
-
- return super().node_init()
- except Exception as e:
- log.error(f"Failed to initialize GraphQueryNode: {e}")
-
- return CStatus(-1, f"GraphQueryNode initialization failed: {e}")
+ return context
def operator_schedule(self, data_json: Dict[str, Any]) -> Dict[str, Any]:
"""
@@ -79,15 +479,31 @@
return data_json
# Execute the graph query (assuming schema and semantic query have been completed in previous nodes)
- graph_result = self.graph_rag_query.run(data_json)
- data_json.update(graph_result)
+ self.init_client(data_json)
+
+ # initial flag: -1 means no result, 0 means subgraph query, 1 means gremlin query
+ data_json["graph_result_flag"] = -1
+ # 1. Try to perform a query based on the generated gremlin
+ if self._num_gremlin_generate_example >= 0:
+ data_json = self._gremlin_generate_query(data_json)
+ # 2. Try to perform a query based on subgraph-search if the previous query failed
+ if not data_json.get("graph_result"):
+ data_json = self._subgraph_query(data_json)
+
+ if data_json.get("graph_result"):
+ log.debug(
+ "Knowledge from Graph:\n%s", "\n".join(data_json["graph_result"])
+ )
+ else:
+ log.debug("No Knowledge Extracted from Graph")
log.info(
- f"Graph query completed, found {len(data_json.get('graph_result', []))} results"
+ "Graph query completed, found %d results",
+ len(data_json.get("graph_result", [])),
)
return data_json
- except Exception as e:
- log.error(f"Graph query failed: {e}")
+ except Exception as e: # pylint: disable=broad-except,broad-exception-caught
+ log.error("Graph query failed: %s", e)
return data_json
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/schema.py b/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/schema.py
index 3face9d..26d74c5 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/schema.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/hugegraph_node/schema.py
@@ -15,6 +15,7 @@
import json
+from PyCGraph import CStatus
from hugegraph_llm.nodes.base_node import BaseNode
from hugegraph_llm.operators.common_op.check_schema import CheckSchema
from hugegraph_llm.operators.hugegraph_op.schema_manager import SchemaManager
@@ -38,23 +39,23 @@
):
if from_hugegraph:
return SchemaManager(from_hugegraph)
- elif from_user_defined:
+ if from_user_defined:
return CheckSchema(from_user_defined)
- elif from_extraction:
+ if from_extraction:
raise NotImplementedError("Not implemented yet")
- else:
- raise ValueError("No input data / invalid schema type")
+ raise ValueError("No input data / invalid schema type")
def node_init(self):
- self.schema = self.wk_input.schema
- self.schema = self.schema.strip()
+ if self.wk_input.schema is None:
+ return CStatus(-1, "Schema message is required in SchemaNode")
+ self.schema = self.wk_input.schema.strip()
if self.schema.startswith("{"):
try:
schema = json.loads(self.schema)
self.check_schema = self._import_schema(from_user_defined=schema)
except json.JSONDecodeError as exc:
log.error("Invalid JSON format in schema. Please check it again.")
- raise ValueError("Invalid JSON format in schema.") from exc
+ return CStatus(-1, f"Invalid JSON format in schema. {exc}")
else:
log.info("Get schema '%s' from graphdb.", self.schema)
self.schema_manager = self._import_schema(from_hugegraph=self.schema)
@@ -63,11 +64,6 @@
def operator_schedule(self, data_json):
log.debug("SchemaNode input state: %s", data_json)
if self.schema.startswith("{"):
- try:
- return self.check_schema.run(data_json)
- except json.JSONDecodeError as exc:
- log.error("Invalid JSON format in schema. Please check it again.")
- raise ValueError("Invalid JSON format in schema.") from exc
- else:
- log.info("Get schema '%s' from graphdb.", self.schema)
- return self.schema_manager.run(data_json)
+ return self.check_schema.run(data_json)
+ log.info("Get schema '%s' from graphdb.", self.schema)
+ return self.schema_manager.run(data_json)
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/index_node/build_gremlin_example_index.py b/hugegraph-llm/src/hugegraph_llm/nodes/index_node/build_gremlin_example_index.py
new file mode 100644
index 0000000..8772959
--- /dev/null
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/index_node/build_gremlin_example_index.py
@@ -0,0 +1,43 @@
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from PyCGraph import CStatus
+
+from hugegraph_llm.config import llm_settings
+from hugegraph_llm.models.embeddings.init_embedding import get_embedding
+from hugegraph_llm.nodes.base_node import BaseNode
+from hugegraph_llm.operators.index_op.build_gremlin_example_index import (
+ BuildGremlinExampleIndex,
+)
+from hugegraph_llm.state.ai_state import WkFlowInput, WkFlowState
+
+
+class BuildGremlinExampleIndexNode(BaseNode):
+ build_gremlin_example_index_op: BuildGremlinExampleIndex
+ context: WkFlowState = None
+ wk_input: WkFlowInput = None
+
+ def node_init(self):
+ if not self.wk_input.examples:
+ return CStatus(-1, "examples is required in BuildGremlinExampleIndexNode")
+ examples = self.wk_input.examples
+
+ self.build_gremlin_example_index_op = BuildGremlinExampleIndex(
+ get_embedding(llm_settings), examples
+ )
+ return super().node_init()
+
+ def operator_schedule(self, data_json):
+ return self.build_gremlin_example_index_op.run(data_json)
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/index_node/semantic_id_query_node.py b/hugegraph-llm/src/hugegraph_llm/nodes/index_node/semantic_id_query_node.py
index bf605aa..68d2b72 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/index_node/semantic_id_query_node.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/index_node/semantic_id_query_node.py
@@ -13,8 +13,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-from PyCGraph import CStatus
from typing import Dict, Any
+from PyCGraph import CStatus
from hugegraph_llm.nodes.base_node import BaseNode
from hugegraph_llm.operators.index_op.semantic_id_query import SemanticIdQuery
from hugegraph_llm.models.embeddings.init_embedding import get_embedding
@@ -33,59 +33,61 @@
"""
Initialize the semantic ID query operator.
"""
- try:
- graph_name = huge_settings.graph_name
- if not graph_name:
- return CStatus(-1, "graph_name is required in wk_input")
+ graph_name = huge_settings.graph_name
+ if not graph_name:
+ return CStatus(-1, "graph_name is required in wk_input")
- embedding = get_embedding(llm_settings)
- by = self.wk_input.semantic_by or "keywords"
- topk_per_keyword = (
- self.wk_input.topk_per_keyword or huge_settings.topk_per_keyword
- )
- topk_per_query = self.wk_input.topk_per_query or 10
- vector_dis_threshold = (
- self.wk_input.vector_dis_threshold or huge_settings.vector_dis_threshold
- )
+ embedding = get_embedding(llm_settings)
+ by = (
+ self.wk_input.semantic_by
+ if self.wk_input.semantic_by is not None
+ else "keywords"
+ )
+ topk_per_keyword = (
+ self.wk_input.topk_per_keyword
+ if self.wk_input.topk_per_keyword is not None
+ else huge_settings.topk_per_keyword
+ )
+ topk_per_query = (
+ self.wk_input.topk_per_query
+ if self.wk_input.topk_per_query is not None
+ else 10
+ )
+ vector_dis_threshold = (
+ self.wk_input.vector_dis_threshold
+ if self.wk_input.vector_dis_threshold is not None
+ else huge_settings.vector_dis_threshold
+ )
- # Initialize the semantic ID query operator
- self.semantic_id_query = SemanticIdQuery(
- embedding=embedding,
- by=by,
- topk_per_keyword=topk_per_keyword,
- topk_per_query=topk_per_query,
- vector_dis_threshold=vector_dis_threshold,
- )
+ # Initialize the semantic ID query operator
+ self.semantic_id_query = SemanticIdQuery(
+ embedding=embedding,
+ by=by,
+ topk_per_keyword=topk_per_keyword,
+ topk_per_query=topk_per_query,
+ vector_dis_threshold=vector_dis_threshold,
+ )
- return super().node_init()
- except Exception as e:
- log.error(f"Failed to initialize SemanticIdQueryNode: {e}")
-
- return CStatus(-1, f"SemanticIdQueryNode initialization failed: {e}")
+ return super().node_init()
def operator_schedule(self, data_json: Dict[str, Any]) -> Dict[str, Any]:
"""
Execute the semantic ID query operation.
"""
- try:
- # Get the query text and keywords from input
- query = data_json.get("query", "")
- keywords = data_json.get("keywords", [])
+ # Get the query text and keywords from input
+ query = data_json.get("query", "")
+ keywords = data_json.get("keywords", [])
- if not query and not keywords:
- log.warning("No query text or keywords provided for semantic query")
- return data_json
-
- # Perform the semantic query
- semantic_result = self.semantic_id_query.run(data_json)
-
- match_vids = semantic_result.get("match_vids", [])
- log.info(
- f"Semantic query completed, found {len(match_vids)} matching vertex IDs"
- )
-
- return semantic_result
-
- except Exception as e:
- log.error(f"Semantic query failed: {e}")
+ if not query and not keywords:
+ log.warning("No query text or keywords provided for semantic query")
return data_json
+
+ # Perform the semantic query
+ semantic_result = self.semantic_id_query.run(data_json)
+
+ match_vids = semantic_result.get("match_vids", [])
+ log.info(
+ "Semantic query completed, found %d matching vertex IDs", len(match_vids)
+ )
+
+ return semantic_result
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/index_node/vector_query_node.py b/hugegraph-llm/src/hugegraph_llm/nodes/index_node/vector_query_node.py
index 48b50ac..9c8104c 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/index_node/vector_query_node.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/index_node/vector_query_node.py
@@ -32,20 +32,14 @@
"""
Initialize the vector query operator
"""
- try:
- # 从 wk_input 中读取用户配置参数
- embedding = get_embedding(llm_settings)
- max_items = (
- self.wk_input.max_items if self.wk_input.max_items is not None else 3
- )
+ # 从 wk_input 中读取用户配置参数
+ embedding = get_embedding(llm_settings)
+ max_items = (
+ self.wk_input.max_items if self.wk_input.max_items is not None else 3
+ )
- self.operator = VectorIndexQuery(embedding=embedding, topk=max_items)
- return super().node_init()
- except Exception as e:
- log.error(f"Failed to initialize VectorQueryNode: {e}")
- from PyCGraph import CStatus
-
- return CStatus(-1, f"VectorQueryNode initialization failed: {e}")
+ self.operator = VectorIndexQuery(embedding=embedding, topk=max_items)
+ return super().node_init()
def operator_schedule(self, data_json: Dict[str, Any]) -> Dict[str, Any]:
"""
@@ -64,11 +58,12 @@
# Update the state
data_json.update(result)
log.info(
- f"Vector query completed, found {len(result.get('vector_result', []))} results"
+ "Vector query completed, found %d results",
+ len(result.get("vector_result", [])),
)
return data_json
- except Exception as e:
- log.error(f"Vector query failed: {e}")
+ except ValueError as e:
+ log.error("Vector query failed: %s", e)
return data_json
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/answer_synthesize_node.py b/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/answer_synthesize_node.py
index 22b970b..6997cd7 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/answer_synthesize_node.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/answer_synthesize_node.py
@@ -30,70 +30,57 @@
"""
Initialize the answer synthesis operator.
"""
- try:
- prompt_template = self.wk_input.answer_prompt
- raw_answer = self.wk_input.raw_answer or False
- vector_only_answer = self.wk_input.vector_only_answer or False
- graph_only_answer = self.wk_input.graph_only_answer or False
- graph_vector_answer = self.wk_input.graph_vector_answer or False
+ prompt_template = self.wk_input.answer_prompt
+ raw_answer = self.wk_input.raw_answer or False
+ vector_only_answer = self.wk_input.vector_only_answer or False
+ graph_only_answer = self.wk_input.graph_only_answer or False
+ graph_vector_answer = self.wk_input.graph_vector_answer or False
- self.operator = AnswerSynthesize(
- prompt_template=prompt_template,
- raw_answer=raw_answer,
- vector_only_answer=vector_only_answer,
- graph_only_answer=graph_only_answer,
- graph_vector_answer=graph_vector_answer,
- )
- return super().node_init()
- except Exception as e:
- log.error(f"Failed to initialize AnswerSynthesizeNode: {e}")
- from PyCGraph import CStatus
-
- return CStatus(-1, f"AnswerSynthesizeNode initialization failed: {e}")
+ self.operator = AnswerSynthesize(
+ prompt_template=prompt_template,
+ raw_answer=raw_answer,
+ vector_only_answer=vector_only_answer,
+ graph_only_answer=graph_only_answer,
+ graph_vector_answer=graph_vector_answer,
+ )
+ return super().node_init()
def operator_schedule(self, data_json: Dict[str, Any]) -> Dict[str, Any]:
"""
Execute the answer synthesis operation.
"""
- try:
- if self.getGParamWithNoEmpty("wkflow_input").stream:
- # Streaming mode: return a generator for streaming output
- data_json["stream_generator"] = self.operator.run_streaming(data_json)
- return data_json
- else:
- # Non-streaming mode: execute answer synthesis
- result = self.operator.run(data_json)
-
- # Record the types of answers generated
- answer_types = []
- if result.get("raw_answer"):
- answer_types.append("raw")
- if result.get("vector_only_answer"):
- answer_types.append("vector_only")
- if result.get("graph_only_answer"):
- answer_types.append("graph_only")
- if result.get("graph_vector_answer"):
- answer_types.append("graph_vector")
-
- log.info(
- f"Answer synthesis completed for types: {', '.join(answer_types)}"
- )
-
- # Print enabled answer types according to self.wk_input configuration
- wk_input_types = []
- if getattr(self.wk_input, "raw_answer", False):
- wk_input_types.append("raw")
- if getattr(self.wk_input, "vector_only_answer", False):
- wk_input_types.append("vector_only")
- if getattr(self.wk_input, "graph_only_answer", False):
- wk_input_types.append("graph_only")
- if getattr(self.wk_input, "graph_vector_answer", False):
- wk_input_types.append("graph_vector")
- log.info(
- f"Enabled answer types according to wk_input config: {', '.join(wk_input_types)}"
- )
- return result
-
- except Exception as e:
- log.error(f"Answer synthesis failed: {e}")
+ if self.getGParamWithNoEmpty("wkflow_input").stream:
+ # Streaming mode: return a generator for streaming output
+ data_json["stream_generator"] = self.operator.run_streaming(data_json)
return data_json
+ # Non-streaming mode: execute answer synthesis
+ result = self.operator.run(data_json)
+
+ # Record the types of answers generated
+ answer_types = []
+ if result.get("raw_answer"):
+ answer_types.append("raw")
+ if result.get("vector_only_answer"):
+ answer_types.append("vector_only")
+ if result.get("graph_only_answer"):
+ answer_types.append("graph_only")
+ if result.get("graph_vector_answer"):
+ answer_types.append("graph_vector")
+
+ log.info("Answer synthesis completed for types: %s", ", ".join(answer_types))
+
+ # Print enabled answer types according to self.wk_input configuration
+ wk_input_types = []
+ if getattr(self.wk_input, "raw_answer", False):
+ wk_input_types.append("raw")
+ if getattr(self.wk_input, "vector_only_answer", False):
+ wk_input_types.append("vector_only")
+ if getattr(self.wk_input, "graph_only_answer", False):
+ wk_input_types.append("graph_only")
+ if getattr(self.wk_input, "graph_vector_answer", False):
+ wk_input_types.append("graph_vector")
+ log.info(
+ "Enabled answer types according to wk_input config: %s",
+ ", ".join(wk_input_types),
+ )
+ return result
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/extract_info.py b/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/extract_info.py
index 628765f..3c9bf23 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/extract_info.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/extract_info.py
@@ -48,5 +48,6 @@
def operator_schedule(self, data_json):
if self.extract_type == "triples":
return self.info_extract.run(data_json)
- elif self.extract_type == "property_graph":
+ if self.extract_type == "property_graph":
return self.property_graph_extract.run(data_json)
+ raise ValueError("Unsupport extract type")
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/keyword_extract_node.py b/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/keyword_extract_node.py
index 76fc06e..60542dd 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/keyword_extract_node.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/keyword_extract_node.py
@@ -14,7 +14,6 @@
# limitations under the License.
from typing import Dict, Any
-from PyCGraph import CStatus
from hugegraph_llm.nodes.base_node import BaseNode
from hugegraph_llm.operators.llm_op.keyword_extract import KeywordExtract
@@ -32,29 +31,17 @@
"""
Initialize the keyword extraction operator.
"""
- try:
- max_keywords = (
- self.wk_input.max_keywords
- if self.wk_input.max_keywords is not None
- else 5
- )
- language = (
- self.wk_input.language
- if self.wk_input.language is not None
- else "english"
- )
- extract_template = self.wk_input.keywords_extract_prompt
+ max_keywords = (
+ self.wk_input.max_keywords if self.wk_input.max_keywords is not None else 5
+ )
+ extract_template = self.wk_input.keywords_extract_prompt
- self.operator = KeywordExtract(
- text=self.wk_input.query,
- max_keywords=max_keywords,
- language=language,
- extract_template=extract_template,
- )
- return super().node_init()
- except Exception as e:
- log.error(f"Failed to initialize KeywordExtractNode: {e}")
- return CStatus(-1, f"KeywordExtractNode initialization failed: {e}")
+ self.operator = KeywordExtract(
+ text=self.wk_input.query,
+ max_keywords=max_keywords,
+ extract_template=extract_template,
+ )
+ return super().node_init()
def operator_schedule(self, data_json: Dict[str, Any]) -> Dict[str, Any]:
"""
@@ -67,12 +54,12 @@
log.warning("Keyword extraction result missing 'keywords' field")
result["keywords"] = []
- log.info(f"Extracted keywords: {result.get('keywords', [])}")
+ log.info("Extracted keywords: %s", result.get("keywords", []))
return result
- except Exception as e:
- log.error(f"Keyword extraction failed: {e}")
+ except ValueError as e:
+ log.error("Keyword extraction failed: %s", e)
# Add error flag to indicate failure
error_result = data_json.copy()
error_result["error"] = str(e)
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/schema_build.py b/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/schema_build.py
index 408adb1..1ef7e5c 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/schema_build.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/schema_build.py
@@ -61,12 +61,16 @@
# few_shot_schema: already parsed dict or raw JSON string
few_shot_schema = {}
- fss_src = self.wk_input.few_shot_schema if self.wk_input.few_shot_schema else None
+ fss_src = (
+ self.wk_input.few_shot_schema if self.wk_input.few_shot_schema else None
+ )
if fss_src:
try:
few_shot_schema = json.loads(fss_src)
except json.JSONDecodeError as e:
- return CStatus(-1, f"Few Shot Schema is not in a valid JSON format: {e}")
+ return CStatus(
+ -1, f"Few Shot Schema is not in a valid JSON format: {e}"
+ )
_context_payload = {
"raw_texts": raw_texts,
@@ -82,6 +86,6 @@
schema_result = self.schema_builder.run(data_json)
return {"schema": schema_result}
- except Exception as e:
+ except (ValueError, RuntimeError) as e:
log.error("Failed to generate schema: %s", e)
return {"schema": f"Schema generation failed: {e}"}
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/text2gremlin.py b/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/text2gremlin.py
index a368315..0904b99 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/text2gremlin.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/llm_node/text2gremlin.py
@@ -18,7 +18,6 @@
import json
from typing import Any, Dict, Optional
-from PyCGraph import CStatus
from hugegraph_llm.nodes.base_node import BaseNode
from hugegraph_llm.operators.llm_op.gremlin_generate import GremlinGenerateSynthesize
@@ -27,13 +26,14 @@
def _stable_schema_string(state_json: Dict[str, Any]) -> str:
- if "simple_schema" in state_json and state_json["simple_schema"] is not None:
- return json.dumps(
- state_json["simple_schema"], ensure_ascii=False, sort_keys=True
- )
- if "schema" in state_json and state_json["schema"] is not None:
- return json.dumps(state_json["schema"], ensure_ascii=False, sort_keys=True)
- return ""
+ val = state_json.get("simple_schema")
+ if val is None:
+ val = state_json.get("schema")
+ if val is None:
+ return ""
+ if isinstance(val, str):
+ return val
+ return json.dumps(val, ensure_ascii=False, sort_keys=True)
class Text2GremlinNode(BaseNode):
@@ -56,7 +56,7 @@
vertices=None,
gremlin_prompt=gremlin_prompt,
)
- return CStatus()
+ return super().node_init()
def operator_schedule(self, data_json: Dict[str, Any]):
# Ensure query exists in context; return empty if not provided
diff --git a/hugegraph-llm/src/hugegraph_llm/nodes/util.py b/hugegraph-llm/src/hugegraph_llm/nodes/util.py
index 60bdc2e..d1ac696 100644
--- a/hugegraph-llm/src/hugegraph_llm/nodes/util.py
+++ b/hugegraph-llm/src/hugegraph_llm/nodes/util.py
@@ -13,15 +13,26 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+from typing import Any
+
from PyCGraph import CStatus
-def init_context(obj) -> CStatus:
- try:
- obj.context = obj.getGParamWithNoEmpty("wkflow_state")
- obj.wk_input = obj.getGParamWithNoEmpty("wkflow_input")
- if obj.context is None or obj.wk_input is None:
- return CStatus(-1, "Required workflow parameters not found")
- return CStatus()
- except Exception as e:
- return CStatus(-1, f"Failed to initialize context: {str(e)}")
+def init_context(obj: Any) -> CStatus:
+ """
+ Initialize workflow context for a node.
+
+ Retrieves wkflow_state and wkflow_input from obj's global parameters
+ and assigns them to obj.context and obj.wk_input respectively.
+
+ Args:
+ obj: Node object with getGParamWithNoEmpty method
+
+ Returns:
+ CStatus: Empty status on success, error status with code -1 on failure
+ """
+ obj.context = obj.getGParamWithNoEmpty("wkflow_state")
+ obj.wk_input = obj.getGParamWithNoEmpty("wkflow_input")
+ if obj.context is None or obj.wk_input is None:
+ return CStatus(-1, "Required workflow parameters not found")
+ return CStatus()
diff --git a/hugegraph-llm/src/hugegraph_llm/operators/graph_rag_task.py b/hugegraph-llm/src/hugegraph_llm/operators/graph_rag_task.py
deleted file mode 100644
index 58848f8..0000000
--- a/hugegraph-llm/src/hugegraph_llm/operators/graph_rag_task.py
+++ /dev/null
@@ -1,252 +0,0 @@
-# Licensed to the Apache Software Foundation (ASF) under one
-# or more contributor license agreements. See the NOTICE file
-# distributed with this work for additional information
-# regarding copyright ownership. The ASF licenses this file
-# to you under the Apache License, Version 2.0 (the
-# "License"); you may not use this file except in compliance
-# with the License. You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing,
-# software distributed under the License is distributed on an
-# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-# KIND, either express or implied. See the License for the
-# specific language governing permissions and limitations
-# under the License.
-
-
-from typing import Any, Dict, List, Literal, Optional
-
-from hugegraph_llm.config import huge_settings, prompt
-from hugegraph_llm.models.embeddings.base import BaseEmbedding
-from hugegraph_llm.models.embeddings.init_embedding import Embeddings
-from hugegraph_llm.models.llms.base import BaseLLM
-from hugegraph_llm.models.llms.init_llm import LLMs
-from hugegraph_llm.operators.common_op.merge_dedup_rerank import MergeDedupRerank
-from hugegraph_llm.operators.common_op.print_result import PrintResult
-from hugegraph_llm.operators.document_op.word_extract import WordExtract
-from hugegraph_llm.operators.hugegraph_op.graph_rag_query import GraphRAGQuery
-from hugegraph_llm.operators.hugegraph_op.schema_manager import SchemaManager
-from hugegraph_llm.operators.index_op.semantic_id_query import SemanticIdQuery
-from hugegraph_llm.operators.index_op.vector_index_query import VectorIndexQuery
-from hugegraph_llm.operators.llm_op.answer_synthesize import AnswerSynthesize
-from hugegraph_llm.operators.llm_op.keyword_extract import KeywordExtract
-from hugegraph_llm.utils.decorators import log_operator_time, log_time, record_rpm
-
-
-class RAGPipeline:
- """
- RAGPipeline is a (core)class that encapsulates a series of operations for extracting information from text,
- querying graph databases and vector indices, merging and re-ranking results, and generating answers.
- """
-
- def __init__(self, llm: Optional[BaseLLM] = None, embedding: Optional[BaseEmbedding] = None):
- """
- Initialize the RAGPipeline with optional LLM and embedding models.
-
- :param llm: Optional LLM model to use.
- :param embedding: Optional embedding model to use.
- """
- self._chat_llm = llm or LLMs().get_chat_llm()
- self._extract_llm = llm or LLMs().get_extract_llm()
- self._text2gqlt_llm = llm or LLMs().get_text2gql_llm()
- self._embedding = embedding or Embeddings().get_embedding()
- self._operators: List[Any] = []
-
- def extract_word(self, text: Optional[str] = None):
- """
- Add a word extraction operator to the pipeline.
-
- :param text: Text to extract words from.
- :return: Self-instance for chaining.
- """
- self._operators.append(WordExtract(text=text))
- return self
-
- def extract_keywords(
- self,
- text: Optional[str] = None,
- extract_template: Optional[str] = None,
- ):
- """
- Add a keyword extraction operator to the pipeline.
-
- :param text: Text to extract keywords from.
- :param extract_template: Template for keyword extraction.
- :return: Self-instance for chaining.
- """
- self._operators.append(
- KeywordExtract(
- text=text,
- extract_template=extract_template
- )
- )
- return self
-
- def import_schema(self, graph_name: str):
- self._operators.append(SchemaManager(graph_name))
- return self
-
- def keywords_to_vid(
- self,
- by: Literal["query", "keywords"] = "keywords",
- topk_per_keyword: int = huge_settings.topk_per_keyword,
- topk_per_query: int = 10,
- vector_dis_threshold: float = huge_settings.vector_dis_threshold,
- ):
- """
- Add a semantic ID query operator to the pipeline.
- :param by: Match by query or keywords.
- :param topk_per_keyword: Top K results per keyword.
- :param topk_per_query: Top K results per query.
- :param vector_dis_threshold: Vector distance threshold.
- :return: Self-instance for chaining.
- """
- self._operators.append(
- SemanticIdQuery(
- embedding=self._embedding,
- by=by,
- topk_per_keyword=topk_per_keyword,
- topk_per_query=topk_per_query,
- vector_dis_threshold=vector_dis_threshold,
- )
- )
- return self
-
- def query_graphdb(
- self,
- max_deep: int = 2,
- max_graph_items: int = huge_settings.max_graph_items,
- max_v_prop_len: int = 2048,
- max_e_prop_len: int = 256,
- prop_to_match: Optional[str] = None,
- num_gremlin_generate_example: Optional[int] = -1,
- gremlin_prompt: Optional[str] = prompt.gremlin_generate_prompt,
- ):
- """
- Add a graph RAG query operator to the pipeline.
-
- :param max_deep: Maximum depth for the graph query.
- :param max_graph_items: Maximum number of items to retrieve.
- :param max_v_prop_len: Maximum length of vertex properties.
- :param max_e_prop_len: Maximum length of edge properties.
- :param prop_to_match: Property to match in the graph.
- :param num_gremlin_generate_example: Number of examples to generate.
- :param gremlin_prompt: Gremlin prompt for generating examples.
- :return: Self-instance for chaining.
- """
- self._operators.append(
- GraphRAGQuery(
- max_deep=max_deep,
- max_graph_items=max_graph_items,
- max_v_prop_len=max_v_prop_len,
- max_e_prop_len=max_e_prop_len,
- prop_to_match=prop_to_match,
- num_gremlin_generate_example=num_gremlin_generate_example,
- gremlin_prompt=gremlin_prompt,
- )
- )
- return self
-
- def query_vector_index(self, max_items: int = 3):
- """
- Add a vector index query operator to the pipeline.
-
- :param max_items: Maximum number of items to retrieve.
- :return: Self-instance for chaining.
- """
- self._operators.append(
- VectorIndexQuery(
- embedding=self._embedding,
- topk=max_items,
- )
- )
- return self
-
- def merge_dedup_rerank(
- self,
- graph_ratio: float = 0.5,
- rerank_method: Literal["bleu", "reranker"] = "bleu",
- near_neighbor_first: bool = False,
- custom_related_information: str = "",
- topk_return_results: int = huge_settings.topk_return_results,
- ):
- """
- Add a merge, deduplication, and rerank operator to the pipeline.
-
- :return: Self-instance for chaining.
- """
- self._operators.append(
- MergeDedupRerank(
- embedding=self._embedding,
- graph_ratio=graph_ratio,
- method=rerank_method,
- near_neighbor_first=near_neighbor_first,
- custom_related_information=custom_related_information,
- topk_return_results=topk_return_results,
- )
- )
- return self
-
- def synthesize_answer(
- self,
- raw_answer: bool = False,
- vector_only_answer: bool = True,
- graph_only_answer: bool = False,
- graph_vector_answer: bool = False,
- answer_prompt: Optional[str] = None,
- ):
- """
- Add an answer synthesis operator to the pipeline.
-
- :param raw_answer: Whether to return raw answers.
- :param vector_only_answer: Whether to return vector-only answers.
- :param graph_only_answer: Whether to return graph-only answers.
- :param graph_vector_answer: Whether to return graph-vector combined answers.
- :param answer_prompt: Template for the answer synthesis prompt.
- :return: Self-instance for chaining.
- """
- self._operators.append(
- AnswerSynthesize(
- raw_answer=raw_answer,
- vector_only_answer=vector_only_answer,
- graph_only_answer=graph_only_answer,
- graph_vector_answer=graph_vector_answer,
- prompt_template=answer_prompt,
- )
- )
- return self
-
- def print_result(self):
- """
- Add a print result operator to the pipeline.
-
- :return: Self-instance for chaining.
- """
- self._operators.append(PrintResult())
- return self
-
- @log_time("total time")
- @record_rpm
- def run(self, **kwargs) -> Dict[str, Any]:
- """
- Execute all operators in the pipeline in sequence.
-
- :param kwargs: Additional context to pass to operators.
- :return: Final context after all operators have been executed.
- """
- if len(self._operators) == 0:
- self.extract_keywords().query_graphdb(
- max_graph_items=kwargs.get("max_graph_items")
- ).synthesize_answer()
-
- context = kwargs
-
- for operator in self._operators:
- context = self._run_operator(operator, context)
- return context
-
- @log_operator_time
- def _run_operator(self, operator, context):
- return operator.run(context)
diff --git a/hugegraph-llm/src/hugegraph_llm/operators/gremlin_generate_task.py b/hugegraph-llm/src/hugegraph_llm/operators/gremlin_generate_task.py
deleted file mode 100644
index 70f3d27..0000000
--- a/hugegraph-llm/src/hugegraph_llm/operators/gremlin_generate_task.py
+++ /dev/null
@@ -1,81 +0,0 @@
-# Licensed to the Apache Software Foundation (ASF) under one
-# or more contributor license agreements. See the NOTICE file
-# distributed with this work for additional information
-# regarding copyright ownership. The ASF licenses this file
-# to you under the Apache License, Version 2.0 (the
-# "License"); you may not use this file except in compliance
-# with the License. You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing,
-# software distributed under the License is distributed on an
-# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-# KIND, either express or implied. See the License for the
-# specific language governing permissions and limitations
-# under the License.
-from typing import Optional, List
-
-from hugegraph_llm.models.embeddings.base import BaseEmbedding
-from hugegraph_llm.models.llms.base import BaseLLM
-from hugegraph_llm.operators.common_op.check_schema import CheckSchema
-from hugegraph_llm.operators.common_op.print_result import PrintResult
-from hugegraph_llm.operators.hugegraph_op.schema_manager import SchemaManager
-from hugegraph_llm.operators.index_op.build_gremlin_example_index import BuildGremlinExampleIndex
-from hugegraph_llm.operators.index_op.gremlin_example_index_query import GremlinExampleIndexQuery
-from hugegraph_llm.operators.llm_op.gremlin_generate import GremlinGenerateSynthesize
-from hugegraph_llm.utils.decorators import log_time, log_operator_time, record_rpm
-
-
-class GremlinGenerator:
- def __init__(self, llm: BaseLLM, embedding: BaseEmbedding):
- self.embedding = []
- self.llm = llm
- self.embedding = embedding
- self.result = None
- self.operators = []
-
- def clear(self):
- self.operators = []
- return self
-
- def example_index_build(self, examples):
- self.operators.append(BuildGremlinExampleIndex(self.embedding, examples))
- return self
-
- def import_schema(self, from_hugegraph=None, from_extraction=None, from_user_defined=None):
- if from_hugegraph:
- self.operators.append(SchemaManager(from_hugegraph))
- elif from_user_defined:
- self.operators.append(CheckSchema(from_user_defined))
- elif from_extraction:
- raise NotImplementedError("Not implemented yet")
- else:
- raise ValueError("No input data / invalid schema type")
- return self
-
- def example_index_query(self, num_examples):
- self.operators.append(GremlinExampleIndexQuery(self.embedding, num_examples))
- return self
-
- def gremlin_generate_synthesize(
- self, schema, gremlin_prompt: Optional[str] = None, vertices: Optional[List[str]] = None
- ):
- self.operators.append(GremlinGenerateSynthesize(self.llm, schema, vertices, gremlin_prompt))
- return self
-
- def print_result(self):
- self.operators.append(PrintResult())
- return self
-
- @log_time("total time")
- @record_rpm
- def run(self, **kwargs):
- context = kwargs
- for operator in self.operators:
- context = self._run_operator(operator, context)
- return context
-
- @log_operator_time
- def _run_operator(self, operator, context):
- return operator.run(context)
diff --git a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/commit_to_hugegraph.py b/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/commit_to_hugegraph.py
index 52626b7..ba4392f 100644
--- a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/commit_to_hugegraph.py
+++ b/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/commit_to_hugegraph.py
@@ -40,7 +40,6 @@
schema = data.get("schema")
vertices = data.get("vertices", [])
edges = data.get("edges", [])
- print(f"get schema {schema}")
if not vertices and not edges:
log.critical(
"(Loading) Both vertices and edges are empty. Please check the input data again."
@@ -50,7 +49,9 @@
if not schema:
# TODO: ensure the function works correctly (update the logic later)
self.schema_free_mode(data.get("triples", []))
- log.warning("Using schema_free mode, could try schema_define mode for better effect!")
+ log.warning(
+ "Using schema_free mode, could try schema_define mode for better effect!"
+ )
else:
self.init_schema_if_need(schema)
self.load_into_graph(vertices, edges, schema)
@@ -66,7 +67,9 @@
# list or set
default_value = []
input_properties[key] = default_value
- log.warning("Property '%s' missing in vertex, set to '%s' for now", key, default_value)
+ log.warning(
+ "Property '%s' missing in vertex, set to '%s' for now", key, default_value
+ )
def _handle_graph_creation(self, func, *args, **kwargs):
try:
@@ -80,9 +83,13 @@
def load_into_graph(self, vertices, edges, schema): # pylint: disable=too-many-statements
# pylint: disable=R0912 (too-many-branches)
- vertex_label_map = {v_label["name"]: v_label for v_label in schema["vertexlabels"]}
+ vertex_label_map = {
+ v_label["name"]: v_label for v_label in schema["vertexlabels"]
+ }
edge_label_map = {e_label["name"]: e_label for e_label in schema["edgelabels"]}
- property_label_map = {p_label["name"]: p_label for p_label in schema["propertykeys"]}
+ property_label_map = {
+ p_label["name"]: p_label for p_label in schema["propertykeys"]
+ }
for vertex in vertices:
input_label = vertex["label"]
@@ -98,7 +105,9 @@
vertex_label = vertex_label_map[input_label]
primary_keys = vertex_label["primary_keys"]
nullable_keys = vertex_label.get("nullable_keys", [])
- non_null_keys = [key for key in vertex_label["properties"] if key not in nullable_keys]
+ non_null_keys = [
+ key for key in vertex_label["properties"] if key not in nullable_keys
+ ]
has_problem = False
# 2. Handle primary-keys mode vertex
@@ -130,7 +139,9 @@
# 3. Ensure all non-nullable props are set
for key in non_null_keys:
if key not in input_properties:
- self._set_default_property(key, input_properties, property_label_map)
+ self._set_default_property(
+ key, input_properties, property_label_map
+ )
# 4. Check all data type value is right
for key, value in input_properties.items():
@@ -167,7 +178,9 @@
continue
# TODO: we could try batch add edges first, setback to single-mode if failed
- self._handle_graph_creation(self.client.graph().addEdge, label, start, end, properties)
+ self._handle_graph_creation(
+ self.client.graph().addEdge, label, start, end, properties
+ )
def init_schema_if_need(self, schema: dict):
properties = schema["propertykeys"]
@@ -191,18 +204,20 @@
source_vertex_label = edge["source_label"]
target_vertex_label = edge["target_label"]
properties = edge["properties"]
- self.schema.edgeLabel(edge_label).sourceLabel(source_vertex_label).targetLabel(
- target_vertex_label
- ).properties(*properties).nullableKeys(*properties).ifNotExist().create()
+ self.schema.edgeLabel(edge_label).sourceLabel(
+ source_vertex_label
+ ).targetLabel(target_vertex_label).properties(*properties).nullableKeys(
+ *properties
+ ).ifNotExist().create()
def schema_free_mode(self, data):
self.schema.propertyKey("name").asText().ifNotExist().create()
self.schema.vertexLabel("vertex").useCustomizeStringId().properties(
"name"
).ifNotExist().create()
- self.schema.edgeLabel("edge").sourceLabel("vertex").targetLabel("vertex").properties(
- "name"
- ).ifNotExist().create()
+ self.schema.edgeLabel("edge").sourceLabel("vertex").targetLabel(
+ "vertex"
+ ).properties("name").ifNotExist().create()
self.schema.indexLabel("vertexByName").onV("vertex").by(
"name"
@@ -262,7 +277,9 @@
log.warning("UUID type is not supported, use text instead")
property_key.asText()
else:
- log.error("Unknown data type %s for property_key %s", data_type, property_key)
+ log.error(
+ "Unknown data type %s for property_key %s", data_type, property_key
+ )
def _set_property_cardinality(self, property_key, cardinality):
if cardinality == PropertyCardinality.SINGLE:
@@ -272,9 +289,13 @@
elif cardinality == PropertyCardinality.SET:
property_key.valueSet()
else:
- log.error("Unknown cardinality %s for property_key %s", cardinality, property_key)
+ log.error(
+ "Unknown cardinality %s for property_key %s", cardinality, property_key
+ )
- def _check_property_data_type(self, data_type: str, cardinality: str, value) -> bool:
+ def _check_property_data_type(
+ self, data_type: str, cardinality: str, value
+ ) -> bool:
if cardinality in (
PropertyCardinality.LIST.value,
PropertyCardinality.SET.value,
@@ -304,7 +325,9 @@
if data_type in (PropertyDataType.TEXT.value, PropertyDataType.UUID.value):
return isinstance(value, str)
# TODO: check ok below
- if data_type == PropertyDataType.DATE.value: # the format should be "yyyy-MM-dd"
+ if (
+ data_type == PropertyDataType.DATE.value
+ ): # the format should be "yyyy-MM-dd"
import re
return isinstance(value, str) and re.match(r"^\d{4}-\d{2}-\d{2}$", value)
diff --git a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/graph_rag_query.py b/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/graph_rag_query.py
deleted file mode 100644
index bcff5f0..0000000
--- a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/graph_rag_query.py
+++ /dev/null
@@ -1,455 +0,0 @@
-# Licensed to the Apache Software Foundation (ASF) under one
-# or more contributor license agreements. See the NOTICE file
-# distributed with this work for additional information
-# regarding copyright ownership. The ASF licenses this file
-# to you under the Apache License, Version 2.0 (the
-# "License"); you may not use this file except in compliance
-# with the License. You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing,
-# software distributed under the License is distributed on an
-# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-# KIND, either express or implied. See the License for the
-# specific language governing permissions and limitations
-# under the License.
-
-import json
-from typing import Any, Dict, Optional, List, Set, Tuple
-
-from hugegraph_llm.config import huge_settings, prompt
-from hugegraph_llm.models.embeddings.base import BaseEmbedding
-from hugegraph_llm.models.llms.base import BaseLLM
-from hugegraph_llm.operators.gremlin_generate_task import GremlinGenerator
-from hugegraph_llm.utils.log import log
-from pyhugegraph.client import PyHugeClient
-
-# TODO: remove 'as('subj)' step
-VERTEX_QUERY_TPL = "g.V({keywords}).limit(8).as('subj').toList()"
-
-# TODO: we could use a simpler query (like kneighbor-api to get the edges)
-# TODO: test with profile()/explain() to speed up the query
-VID_QUERY_NEIGHBOR_TPL = """\
-g.V({keywords})
-.repeat(
- bothE({edge_labels}).limit({edge_limit}).otherV().dedup()
-).times({max_deep}).emit()
-.simplePath()
-.path()
-.by(project('label', 'id', 'props')
- .by(label())
- .by(id())
- .by(valueMap().by(unfold()))
-)
-.by(project('label', 'inV', 'outV', 'props')
- .by(label())
- .by(inV().id())
- .by(outV().id())
- .by(valueMap().by(unfold()))
-)
-.limit({max_items})
-.toList()
-"""
-
-PROPERTY_QUERY_NEIGHBOR_TPL = """\
-g.V().has('{prop}', within({keywords}))
-.repeat(
- bothE({edge_labels}).limit({edge_limit}).otherV().dedup()
-).times({max_deep}).emit()
-.simplePath()
-.path()
-.by(project('label', 'props')
- .by(label())
- .by(valueMap().by(unfold()))
-)
-.by(project('label', 'inV', 'outV', 'props')
- .by(label())
- .by(inV().values('{prop}'))
- .by(outV().values('{prop}'))
- .by(valueMap().by(unfold()))
-)
-.limit({max_items})
-.toList()
-"""
-
-
-class GraphRAGQuery:
- def __init__(
- self,
- max_deep: int = 2,
- max_graph_items: int = huge_settings.max_graph_items,
- prop_to_match: Optional[str] = None,
- llm: Optional[BaseLLM] = None,
- embedding: Optional[BaseEmbedding] = None,
- max_v_prop_len: Optional[int] = 2048,
- max_e_prop_len: Optional[int] = 256,
- num_gremlin_generate_example: Optional[int] = -1,
- gremlin_prompt: Optional[str] = None,
- ):
- self._client = PyHugeClient(
- url=huge_settings.graph_url,
- graph=huge_settings.graph_name,
- user=huge_settings.graph_user,
- pwd=huge_settings.graph_pwd,
- graphspace=huge_settings.graph_space,
- )
- self._max_deep = max_deep
- self._max_items = max_graph_items
- self._prop_to_match = prop_to_match
- self._schema = ""
- self._limit_property = huge_settings.limit_property.lower() == "true"
- self._max_v_prop_len = max_v_prop_len
- self._max_e_prop_len = max_e_prop_len
- self._gremlin_generator = GremlinGenerator(
- llm=llm,
- embedding=embedding,
- )
- self._num_gremlin_generate_example = num_gremlin_generate_example
- self._gremlin_prompt = gremlin_prompt or prompt.gremlin_generate_prompt
-
- def run(self, context: Dict[str, Any]) -> Dict[str, Any]:
- self.init_client(context)
-
- # initial flag: -1 means no result, 0 means subgraph query, 1 means gremlin query
- context["graph_result_flag"] = -1
- # 1. Try to perform a query based on the generated gremlin
- if self._num_gremlin_generate_example >= 0:
- context = self._gremlin_generate_query(context)
- # 2. Try to perform a query based on subgraph-search if the previous query failed
- if not context.get("graph_result"):
- context = self._subgraph_query(context)
-
- if context.get("graph_result"):
- log.debug("Knowledge from Graph:\n%s", "\n".join(context["graph_result"]))
- else:
- log.debug("No Knowledge Extracted from Graph")
- return context
-
- def _gremlin_generate_query(self, context: Dict[str, Any]) -> Dict[str, Any]:
- query = context["query"]
- vertices = context.get("match_vids")
- query_embedding = context.get("query_embedding")
-
- self._gremlin_generator.clear()
- self._gremlin_generator.example_index_query(num_examples=self._num_gremlin_generate_example)
- gremlin_response = self._gremlin_generator.gremlin_generate_synthesize(
- context["simple_schema"], vertices=vertices, gremlin_prompt=self._gremlin_prompt
- ).run(query=query, query_embedding=query_embedding)
- if self._num_gremlin_generate_example > 0:
- gremlin = gremlin_response["result"]
- else:
- gremlin = gremlin_response["raw_result"]
- log.info("Generated gremlin: %s", gremlin)
- context["gremlin"] = gremlin
- try:
- result = self._client.gremlin().exec(gremlin=gremlin)["data"]
- if result == [None]:
- result = []
- context["graph_result"] = [json.dumps(item, ensure_ascii=False) for item in result]
- if context["graph_result"]:
- context["graph_result_flag"] = 1
- context["graph_context_head"] = (
- f"The following are graph query result " f"from gremlin query `{gremlin}`.\n"
- )
- except Exception as e: # pylint: disable=broad-except
- log.error(e)
- context["graph_result"] = ""
- return context
-
- def _subgraph_query(self, context: Dict[str, Any]) -> Dict[str, Any]:
- # 1. Extract params from context
- matched_vids = context.get("match_vids")
- if isinstance(context.get("max_deep"), int):
- self._max_deep = context["max_deep"]
- if isinstance(context.get("max_items"), int):
- self._max_items = context["max_items"]
- if isinstance(context.get("prop_to_match"), str):
- self._prop_to_match = context["prop_to_match"]
-
- # 2. Extract edge_labels from graph schema
- _, edge_labels = self._extract_labels_from_schema()
- edge_labels_str = ",".join("'" + label + "'" for label in edge_labels)
- # TODO: enhance the limit logic later
- edge_limit_amount = len(edge_labels) * huge_settings.edge_limit_pre_label
-
- use_id_to_match = self._prop_to_match is None
- if use_id_to_match:
- if not matched_vids:
- return context
-
- gremlin_query = VERTEX_QUERY_TPL.format(keywords=matched_vids)
- vertexes = self._client.gremlin().exec(gremlin=gremlin_query)["data"]
- log.debug("Vids gremlin query: %s", gremlin_query)
-
- vertex_knowledge = self._format_graph_from_vertex(query_result=vertexes)
- paths: List[Any] = []
- # TODO: use generator or asyncio to speed up the query logic
- for matched_vid in matched_vids:
- gremlin_query = VID_QUERY_NEIGHBOR_TPL.format(
- keywords=f"'{matched_vid}'",
- max_deep=self._max_deep,
- edge_labels=edge_labels_str,
- edge_limit=edge_limit_amount,
- max_items=self._max_items,
- )
- log.debug("Kneighbor gremlin query: %s", gremlin_query)
- paths.extend(self._client.gremlin().exec(gremlin=gremlin_query)["data"])
-
- graph_chain_knowledge, vertex_degree_list, knowledge_with_degree = (
- self._format_graph_query_result(query_paths=paths)
- )
-
- # TODO: we may need to optimize the logic here with global deduplication (may lack some single vertex)
- if not graph_chain_knowledge:
- graph_chain_knowledge.update(vertex_knowledge)
- if vertex_degree_list:
- vertex_degree_list[0].update(vertex_knowledge)
- else:
- vertex_degree_list.append(vertex_knowledge)
- else:
- # WARN: When will the query enter here?
- keywords = context.get("keywords")
- assert keywords, "No related property(keywords) for graph query."
- keywords_str = ",".join("'" + kw + "'" for kw in keywords)
- gremlin_query = PROPERTY_QUERY_NEIGHBOR_TPL.format(
- prop=self._prop_to_match,
- keywords=keywords_str,
- edge_labels=edge_labels_str,
- edge_limit=edge_limit_amount,
- max_deep=self._max_deep,
- max_items=self._max_items,
- )
- log.warning(
- "Unable to find vid, downgraded to property query, please confirm if it meets expectation."
- )
-
- paths: List[Any] = self._client.gremlin().exec(gremlin=gremlin_query)["data"]
- graph_chain_knowledge, vertex_degree_list, knowledge_with_degree = (
- self._format_graph_query_result(query_paths=paths)
- )
-
- context["graph_result"] = list(graph_chain_knowledge)
- if context["graph_result"]:
- context["graph_result_flag"] = 0
- context["vertex_degree_list"] = [
- list(vertex_degree) for vertex_degree in vertex_degree_list
- ]
- context["knowledge_with_degree"] = knowledge_with_degree
- context["graph_context_head"] = (
- f"The following are graph knowledge in {self._max_deep} depth, e.g:\n"
- "`vertexA--[links]-->vertexB<--[links]--vertexC ...`"
- "extracted based on key entities as subject:\n"
- )
- return context
-
- # TODO: move this method to a util file for reuse (remove self param)
- def init_client(self, context):
- """Initialize the HugeGraph client from context or default settings."""
- # pylint: disable=R0915 (too-many-statements)
- if self._client is None:
- if isinstance(context.get("graph_client"), PyHugeClient):
- self._client = context["graph_client"]
- else:
- url = context.get("url") or "http://localhost:8080"
- graph = context.get("graph") or "hugegraph"
- user = context.get("user") or "admin"
- pwd = context.get("pwd") or "admin"
- gs = context.get("graphspace") or None
- self._client = PyHugeClient(url, graph, user, pwd, gs)
- assert self._client is not None, "No valid graph to search."
-
- def get_vertex_details(self, vertex_ids: List[str]) -> List[Dict[str, Any]]:
- if not vertex_ids:
- return []
-
- formatted_ids = ", ".join(f"'{vid}'" for vid in vertex_ids)
- gremlin_query = f"g.V({formatted_ids}).limit(20)"
- result = self._client.gremlin().exec(gremlin=gremlin_query)["data"]
- return result
-
- def _format_graph_from_vertex(self, query_result: List[Any]) -> Set[str]:
- knowledge = set()
- for item in query_result:
- props_str = ", ".join(f"{k}: {v}" for k, v in item["properties"].items())
- node_str = f"{item['id']}{{{props_str}}}"
- knowledge.add(node_str)
- return knowledge
-
- def _format_graph_query_result(
- self, query_paths
- ) -> Tuple[Set[str], List[Set[str]], Dict[str, List[str]]]:
- use_id_to_match = self._prop_to_match is None
- subgraph = set()
- subgraph_with_degree = {}
- vertex_degree_list: List[Set[str]] = []
- v_cache: Set[str] = set()
- e_cache: Set[Tuple[str, str, str]] = set()
-
- for path in query_paths:
- # 1. Process each path
- path_str, vertex_with_degree = self._process_path(
- path, use_id_to_match, v_cache, e_cache
- )
- subgraph.add(path_str)
- subgraph_with_degree[path_str] = vertex_with_degree
- # 2. Update vertex degree list
- self._update_vertex_degree_list(vertex_degree_list, vertex_with_degree)
-
- return subgraph, vertex_degree_list, subgraph_with_degree
-
- def _process_path(
- self,
- path: Any,
- use_id_to_match: bool,
- v_cache: Set[str],
- e_cache: Set[Tuple[str, str, str]],
- ) -> Tuple[str, List[str]]:
- flat_rel = ""
- raw_flat_rel = path["objects"]
- assert len(raw_flat_rel) % 2 == 1, "The length of raw_flat_rel should be odd."
-
- node_cache = set()
- prior_edge_str_len = 0
- depth = 0
- nodes_with_degree = []
-
- for i, item in enumerate(raw_flat_rel):
- if i % 2 == 0:
- # Process each vertex
- flat_rel, prior_edge_str_len, depth = self._process_vertex(
- item,
- flat_rel,
- node_cache,
- prior_edge_str_len,
- depth,
- nodes_with_degree,
- use_id_to_match,
- v_cache,
- )
- else:
- # Process each edge
- flat_rel, prior_edge_str_len = self._process_edge(
- item, flat_rel, raw_flat_rel, i, use_id_to_match, e_cache
- )
-
- return flat_rel, nodes_with_degree
-
- def _process_vertex(
- self,
- item: Any,
- flat_rel: str,
- node_cache: Set[str],
- prior_edge_str_len: int,
- depth: int,
- nodes_with_degree: List[str],
- use_id_to_match: bool,
- v_cache: Set[str],
- ) -> Tuple[str, int, int]:
- matched_str = item["id"] if use_id_to_match else item["props"][self._prop_to_match]
- if matched_str in node_cache:
- flat_rel = flat_rel[:-prior_edge_str_len]
- return flat_rel, prior_edge_str_len, depth
-
- node_cache.add(matched_str)
- props_str = ", ".join(
- f"{k}: {self._limit_property_query(v, 'v')}" for k, v in item["props"].items() if v
- )
-
- # TODO: we may remove label id or replace with label name
- if matched_str in v_cache:
- node_str = matched_str
- else:
- v_cache.add(matched_str)
- node_str = f"{item['id']}{{{props_str}}}"
-
- flat_rel += node_str
- nodes_with_degree.append(node_str)
- depth += 1
- return flat_rel, prior_edge_str_len, depth
-
- def _process_edge(
- self,
- item: Any,
- path_str: str,
- raw_flat_rel: List[Any],
- i: int,
- use_id_to_match: bool,
- e_cache: Set[Tuple[str, str, str]],
- ) -> Tuple[str, int]:
- props_str = ", ".join(
- f"{k}: {self._limit_property_query(v, 'e')}" for k, v in item["props"].items() if v
- )
- props_str = f"{{{props_str}}}" if props_str else ""
- prev_matched_str = (
- raw_flat_rel[i - 1]["id"]
- if use_id_to_match
- else (raw_flat_rel)[i - 1]["props"][self._prop_to_match]
- )
-
- edge_key = (item["inV"], item["label"], item["outV"])
- if edge_key not in e_cache:
- e_cache.add(edge_key)
- edge_label = f"{item['label']}{props_str}"
- else:
- edge_label = item["label"]
-
- edge_str = (
- f"--[{edge_label}]-->" if item["outV"] == prev_matched_str else f"<--[{edge_label}]--"
- )
- path_str += edge_str
- prior_edge_str_len = len(edge_str)
- return path_str, prior_edge_str_len
-
- def _update_vertex_degree_list(
- self, vertex_degree_list: List[Set[str]], nodes_with_degree: List[str]
- ) -> None:
- for depth, node_str in enumerate(nodes_with_degree):
- if depth >= len(vertex_degree_list):
- vertex_degree_list.append(set())
- vertex_degree_list[depth].add(node_str)
-
- def _extract_labels_from_schema(self) -> Tuple[List[str], List[str]]:
- schema = self._get_graph_schema()
- vertex_props_str, edge_props_str = schema.split("\n")[:2]
- # TODO: rename to vertex (also need update in the schema)
- vertex_props_str = vertex_props_str[len("Vertex properties: ") :].strip("[").strip("]")
- edge_props_str = edge_props_str[len("Edge properties: ") :].strip("[").strip("]")
- vertex_labels = self._extract_label_names(vertex_props_str)
- edge_labels = self._extract_label_names(edge_props_str)
- return vertex_labels, edge_labels
-
- @staticmethod
- def _extract_label_names(source: str, head: str = "name: ", tail: str = ", ") -> List[str]:
- result = []
- for s in source.split(head):
- end = s.find(tail)
- label = s[:end]
- if label:
- result.append(label)
- return result
-
- def _get_graph_schema(self, refresh: bool = False) -> str:
- if self._schema and not refresh:
- return self._schema
-
- schema = self._client.schema()
- vertex_schema = schema.getVertexLabels()
- edge_schema = schema.getEdgeLabels()
- relationships = schema.getRelations()
-
- self._schema = (
- f"Vertex properties: {vertex_schema}\n"
- f"Edge properties: {edge_schema}\n"
- f"Relationships: {relationships}\n"
- )
- log.debug("Link(Relation): %s", relationships)
- return self._schema
-
- def _limit_property_query(self, value: Optional[str], item_type: str) -> Optional[str]:
- # NOTE: we skip the filter for list/set type (e.g., list of string, add it if needed)
- if not self._limit_property or not isinstance(value, str):
- return value
-
- max_len = self._max_v_prop_len if item_type == "v" else self._max_e_prop_len
- return value[:max_len] if value else value
diff --git a/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_semantic_index.py b/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_semantic_index.py
index 5689a59..2ed4e84 100644
--- a/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_semantic_index.py
+++ b/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_semantic_index.py
@@ -37,11 +37,15 @@
self.folder_name = get_index_folder_name(
huge_settings.graph_name, huge_settings.graph_space
)
- self.index_dir = str(os.path.join(resource_path, self.folder_name, "graph_vids"))
+ self.index_dir = str(
+ os.path.join(resource_path, self.folder_name, "graph_vids")
+ )
self.filename_prefix = get_filename_prefix(
llm_settings.embedding_type, getattr(embedding, "model_name", None)
)
- self.vid_index = VectorIndex.from_index_file(self.index_dir, self.filename_prefix)
+ self.vid_index = VectorIndex.from_index_file(
+ self.index_dir, self.filename_prefix
+ )
self.embedding = embedding
self.sm = SchemaManager(huge_settings.graph_name)
@@ -50,19 +54,27 @@
def run(self, context: Dict[str, Any]) -> Dict[str, Any]:
vertexlabels = self.sm.schema.getSchema()["vertexlabels"]
- all_pk_flag = all(data.get("id_strategy") == "PRIMARY_KEY" for data in vertexlabels)
+ all_pk_flag = bool(vertexlabels) and all(
+ data.get("id_strategy") == "PRIMARY_KEY" for data in vertexlabels
+ )
past_vids = self.vid_index.properties
# TODO: We should build vid vector index separately, especially when the vertices may be very large
- present_vids = context["vertices"] # Warning: data truncated by fetch_graph_data.py
+ present_vids = context[
+ "vertices"
+ ] # Warning: data truncated by fetch_graph_data.py
removed_vids = set(past_vids) - set(present_vids)
removed_num = self.vid_index.remove(removed_vids)
added_vids = list(set(present_vids) - set(past_vids))
if added_vids:
- vids_to_process = self._extract_names(added_vids) if all_pk_flag else added_vids
- added_embeddings = asyncio.run(get_embeddings_parallel(self.embedding, vids_to_process))
+ vids_to_process = (
+ self._extract_names(added_vids) if all_pk_flag else added_vids
+ )
+ added_embeddings = asyncio.run(
+ get_embeddings_parallel(self.embedding, vids_to_process)
+ )
log.info("Building vector index for %s vertices...", len(added_vids))
self.vid_index.add(added_embeddings, added_vids)
self.vid_index.to_index_file(self.index_dir, self.filename_prefix)
diff --git a/hugegraph-llm/src/hugegraph_llm/operators/kg_construction_task.py b/hugegraph-llm/src/hugegraph_llm/operators/kg_construction_task.py
deleted file mode 100644
index 3b5c631..0000000
--- a/hugegraph-llm/src/hugegraph_llm/operators/kg_construction_task.py
+++ /dev/null
@@ -1,120 +0,0 @@
-# Licensed to the Apache Software Foundation (ASF) under one
-# or more contributor license agreements. See the NOTICE file
-# distributed with this work for additional information
-# regarding copyright ownership. The ASF licenses this file
-# to you under the Apache License, Version 2.0 (the
-# "License"); you may not use this file except in compliance
-# with the License. You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing,
-# software distributed under the License is distributed on an
-# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-# KIND, either express or implied. See the License for the
-# specific language governing permissions and limitations
-# under the License.
-
-
-from typing import Dict, Any, Optional, Literal, Union, List
-
-from hugegraph_llm.models.embeddings.base import BaseEmbedding
-from hugegraph_llm.models.llms.base import BaseLLM
-from hugegraph_llm.operators.common_op.check_schema import CheckSchema
-from hugegraph_llm.operators.common_op.print_result import PrintResult
-from hugegraph_llm.operators.document_op.chunk_split import ChunkSplit
-from hugegraph_llm.operators.hugegraph_op.commit_to_hugegraph import Commit2Graph
-from hugegraph_llm.operators.hugegraph_op.fetch_graph_data import FetchGraphData
-from hugegraph_llm.operators.hugegraph_op.schema_manager import SchemaManager
-from hugegraph_llm.operators.index_op.build_semantic_index import BuildSemanticIndex
-from hugegraph_llm.operators.index_op.build_vector_index import BuildVectorIndex
-from hugegraph_llm.operators.llm_op.disambiguate_data import DisambiguateData
-from hugegraph_llm.operators.llm_op.info_extract import InfoExtract
-from hugegraph_llm.operators.llm_op.property_graph_extract import PropertyGraphExtract
-from hugegraph_llm.operators.llm_op.schema_build import SchemaBuilder
-from hugegraph_llm.utils.decorators import log_time, log_operator_time, record_rpm
-from pyhugegraph.client import PyHugeClient
-
-
-class KgBuilder:
- def __init__(
- self,
- llm: BaseLLM,
- embedding: Optional[BaseEmbedding] = None,
- graph: Optional[PyHugeClient] = None,
- ):
- self.operators = []
- self.llm = llm
- self.embedding = embedding
- self.graph = graph
- self.result = None
-
- def import_schema(self, from_hugegraph=None, from_extraction=None, from_user_defined=None):
- if from_hugegraph:
- self.operators.append(SchemaManager(from_hugegraph))
- elif from_user_defined:
- self.operators.append(CheckSchema(from_user_defined))
- elif from_extraction:
- raise NotImplementedError("Not implemented yet")
- else:
- raise ValueError("No input data / invalid schema type")
- return self
-
- def fetch_graph_data(self):
- self.operators.append(FetchGraphData(self.graph))
- return self
-
- def chunk_split(
- self,
- text: Union[str, List[str]], # text to be split
- split_type: Literal["document", "paragraph", "sentence"] = "document",
- language: Literal["zh", "en"] = "zh",
- ):
- self.operators.append(ChunkSplit(text, split_type, language))
- return self
-
- def extract_info(
- self,
- example_prompt: Optional[str] = None,
- extract_type: Literal["triples", "property_graph"] = "triples",
- ):
- if extract_type == "triples":
- self.operators.append(InfoExtract(self.llm, example_prompt))
- elif extract_type == "property_graph":
- self.operators.append(PropertyGraphExtract(self.llm, example_prompt))
- return self
-
- def disambiguate_word_sense(self):
- self.operators.append(DisambiguateData(self.llm))
- return self
-
- def commit_to_hugegraph(self):
- self.operators.append(Commit2Graph())
- return self
-
- def build_vertex_id_semantic_index(self):
- self.operators.append(BuildSemanticIndex(self.embedding))
- return self
-
- def build_vector_index(self):
- self.operators.append(BuildVectorIndex(self.embedding))
- return self
-
- def print_result(self):
- self.operators.append(PrintResult())
- return self
-
- def build_schema(self):
- self.operators.append(SchemaBuilder(self.llm))
- return self
-
- @log_time("total time")
- @record_rpm
- def run(self, context: Optional[Dict[str, Any]] = None) -> Dict[str, Any]:
- for operator in self.operators:
- context = self._run_operator(operator, context)
- return context
-
- @log_operator_time
- def _run_operator(self, operator, context) -> Dict[str, Any]:
- return operator.run(context)
diff --git a/hugegraph-llm/src/hugegraph_llm/operators/llm_op/keyword_extract.py b/hugegraph-llm/src/hugegraph_llm/operators/llm_op/keyword_extract.py
index 32ed965..48369b4 100644
--- a/hugegraph-llm/src/hugegraph_llm/operators/llm_op/keyword_extract.py
+++ b/hugegraph-llm/src/hugegraph_llm/operators/llm_op/keyword_extract.py
@@ -22,7 +22,9 @@
from hugegraph_llm.config import prompt, llm_settings
from hugegraph_llm.models.llms.base import BaseLLM
from hugegraph_llm.models.llms.init_llm import LLMs
-from hugegraph_llm.operators.document_op.textrank_word_extract import MultiLingualTextRank
+from hugegraph_llm.operators.document_op.textrank_word_extract import (
+ MultiLingualTextRank,
+)
from hugegraph_llm.utils.log import log
KEYWORDS_EXTRACT_TPL = prompt.keywords_extract_prompt
@@ -43,8 +45,8 @@
self._extract_template = extract_template or KEYWORDS_EXTRACT_TPL
self._extract_method = llm_settings.keyword_extract_type.lower()
self._textrank_model = MultiLingualTextRank(
- keyword_num=max_keywords,
- window_size=llm_settings.window_size)
+ keyword_num=max_keywords, window_size=llm_settings.window_size
+ )
def run(self, context: Dict[str, Any]) -> Dict[str, Any]:
if self._query is None:
@@ -66,7 +68,11 @@
max_keyword_num = self._max_keywords
self._max_keywords = max(1, max_keyword_num)
- method = (context.get("extract_method", self._extract_method) or "LLM").strip().lower()
+ method = (
+ (context.get("extract_method", self._extract_method) or "LLM")
+ .strip()
+ .lower()
+ )
if method == "llm":
# LLM method
ranks = self._extract_with_llm()
@@ -82,7 +88,7 @@
keywords = [] if not ranks else sorted(ranks, key=ranks.get, reverse=True)
keywords = [k.replace("'", "") for k in keywords]
- context["keywords"] = keywords[:self._max_keywords]
+ context["keywords"] = keywords[: self._max_keywords]
log.info("User Query: %s\nKeywords: %s", self._query, context["keywords"])
# extracting keywords & expanding synonyms increase the call count by 1
@@ -101,7 +107,7 @@
return keywords
def _extract_with_textrank(self) -> Dict[str, float]:
- """ TextRank mode extraction """
+ """TextRank mode extraction"""
start_time = time.perf_counter()
ranks = {}
try:
@@ -111,12 +117,13 @@
except MemoryError as e:
log.critical("TextRank memory error (text too large?): %s", e)
end_time = time.perf_counter()
- log.debug("TextRank Keyword extraction time: %.2f seconds",
- end_time - start_time)
+ log.debug(
+ "TextRank Keyword extraction time: %.2f seconds", end_time - start_time
+ )
return ranks
def _extract_with_hybrid(self) -> Dict[str, float]:
- """ Hybrid mode extraction """
+ """Hybrid mode extraction"""
ranks = {}
if isinstance(llm_settings.hybrid_llm_weights, float):
@@ -140,7 +147,7 @@
if word in llm_scores:
ranks[word] += llm_scores[word] * llm_weights
if word in tr_scores:
- ranks[word] += tr_scores[word] * (1-llm_weights)
+ ranks[word] += tr_scores[word] * (1 - llm_weights)
end_time = time.perf_counter()
log.debug("Hybrid Keyword extraction time: %.2f seconds", end_time - start_time)
@@ -151,13 +158,11 @@
response: str,
lowercase: bool = True,
start_token: str = "",
-<<<<<<< HEAD
) -> Dict[str, float]:
-
results = {}
# use re.escape(start_token) if start_token contains special chars like */&/^ etc.
- matches = re.findall(rf'{start_token}([^\n]+\n?)', response)
+ matches = re.findall(rf"{start_token}([^\n]+\n?)", response)
for match in matches:
match = match.strip()
@@ -175,34 +180,13 @@
continue
score_val = float(score_raw)
if not 0.0 <= score_val <= 1.0:
- log.warning("Score out of range for %s: %s", word_raw, score_val)
+ log.warning(
+ "Score out of range for %s: %s", word_raw, score_val
+ )
score_val = min(1.0, max(0.0, score_val))
word_out = word_raw.lower() if lowercase else word_raw
results[word_out] = score_val
except (ValueError, AttributeError) as e:
log.warning("Failed to parse item '%s': %s", item, e)
continue
-=======
- ) -> Set[str]:
- keywords = []
- # use re.escape(start_token) if start_token contains special chars like */&/^ etc.
- matches = re.findall(rf"{start_token}[^\n]+\n?", response)
-
- for match in matches:
- match = match[len(start_token) :].strip()
- keywords.extend(
- k.lower() if lowercase else k
- for k in re.split(r"[,,]+", match)
- if len(k.strip()) > 1
- )
-
- # if the keyword consists of multiple words, split into sub-words (removing stopwords)
- results = set(keywords)
- for token in keywords:
- sub_tokens = re.findall(r"\w+", token)
- if len(sub_tokens) > 1:
- results.update(
- w for w in sub_tokens if w not in NLTKHelper().stopwords(lang=self._language)
- )
->>>>>>> 78011d3 (Refactor: text2germlin with PCgraph framework (#50))
return results
diff --git a/hugegraph-llm/src/hugegraph_llm/operators/operator_list.py b/hugegraph-llm/src/hugegraph_llm/operators/operator_list.py
new file mode 100644
index 0000000..6b6bf48
--- /dev/null
+++ b/hugegraph-llm/src/hugegraph_llm/operators/operator_list.py
@@ -0,0 +1,281 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+from typing import Optional, List, Literal, Union
+
+from hugegraph_llm.config import huge_settings
+from hugegraph_llm.models.embeddings.base import BaseEmbedding
+from hugegraph_llm.models.llms.base import BaseLLM
+from hugegraph_llm.operators.common_op.check_schema import CheckSchema
+from hugegraph_llm.operators.common_op.print_result import PrintResult
+from hugegraph_llm.operators.hugegraph_op.schema_manager import SchemaManager
+from hugegraph_llm.operators.index_op.build_gremlin_example_index import (
+ BuildGremlinExampleIndex,
+)
+from hugegraph_llm.operators.index_op.gremlin_example_index_query import (
+ GremlinExampleIndexQuery,
+)
+from hugegraph_llm.operators.llm_op.gremlin_generate import GremlinGenerateSynthesize
+from hugegraph_llm.utils.decorators import log_time, log_operator_time, record_rpm
+from hugegraph_llm.operators.hugegraph_op.fetch_graph_data import FetchGraphData
+from hugegraph_llm.operators.document_op.chunk_split import ChunkSplit
+from hugegraph_llm.operators.llm_op.info_extract import InfoExtract
+from hugegraph_llm.operators.llm_op.property_graph_extract import PropertyGraphExtract
+from hugegraph_llm.operators.llm_op.disambiguate_data import DisambiguateData
+from hugegraph_llm.operators.hugegraph_op.commit_to_hugegraph import Commit2Graph
+from hugegraph_llm.operators.index_op.build_semantic_index import BuildSemanticIndex
+from hugegraph_llm.operators.index_op.build_vector_index import BuildVectorIndex
+from hugegraph_llm.operators.document_op.word_extract import WordExtract
+from hugegraph_llm.operators.llm_op.keyword_extract import KeywordExtract
+from hugegraph_llm.operators.index_op.semantic_id_query import SemanticIdQuery
+from hugegraph_llm.operators.index_op.vector_index_query import VectorIndexQuery
+from hugegraph_llm.operators.common_op.merge_dedup_rerank import MergeDedupRerank
+from hugegraph_llm.operators.llm_op.answer_synthesize import AnswerSynthesize
+from pyhugegraph.client import PyHugeClient
+
+
+class OperatorList:
+ def __init__(
+ self,
+ llm: BaseLLM,
+ embedding: BaseEmbedding,
+ graph: Optional[PyHugeClient] = None,
+ ):
+ self.llm = llm
+ self.embedding = embedding
+ self.result = None
+ self.operators = []
+ self.graph = graph
+
+ def clear(self):
+ self.operators = []
+ return self
+
+ def example_index_build(self, examples):
+ self.operators.append(BuildGremlinExampleIndex(self.embedding, examples))
+ return self
+
+ def import_schema(
+ self, from_hugegraph=None, from_extraction=None, from_user_defined=None
+ ):
+ if from_hugegraph:
+ self.operators.append(SchemaManager(from_hugegraph))
+ elif from_user_defined:
+ self.operators.append(CheckSchema(from_user_defined))
+ elif from_extraction:
+ raise NotImplementedError("Not implemented yet")
+ else:
+ raise ValueError("No input data / invalid schema type")
+ return self
+
+ def example_index_query(self, num_examples):
+ self.operators.append(GremlinExampleIndexQuery(self.embedding, num_examples))
+ return self
+
+ def gremlin_generate_synthesize(
+ self,
+ schema,
+ gremlin_prompt: Optional[str] = None,
+ vertices: Optional[List[str]] = None,
+ ):
+ self.operators.append(
+ GremlinGenerateSynthesize(self.llm, schema, vertices, gremlin_prompt)
+ )
+ return self
+
+ def print_result(self):
+ self.operators.append(PrintResult())
+ return self
+
+ def fetch_graph_data(self):
+ if self.graph is None:
+ raise ValueError("graph client is required for fetch_graph_data operation")
+ self.operators.append(FetchGraphData(self.graph))
+ return self
+
+ def chunk_split(
+ self,
+ text: Union[str, List[str]], # text to be split
+ split_type: Literal["document", "paragraph", "sentence"] = "document",
+ language: Literal["zh", "en"] = "zh",
+ ):
+ self.operators.append(ChunkSplit(text, split_type, language))
+ return self
+
+ def extract_info(
+ self,
+ example_prompt: Optional[str] = None,
+ extract_type: Literal["triples", "property_graph"] = "triples",
+ ):
+ if extract_type == "triples":
+ self.operators.append(InfoExtract(self.llm, example_prompt))
+ elif extract_type == "property_graph":
+ self.operators.append(PropertyGraphExtract(self.llm, example_prompt))
+ else:
+ raise ValueError(
+ f"invalid extract_type: {extract_type!r}, expected 'triples' or 'property_graph'"
+ )
+ return self
+
+ def disambiguate_word_sense(self):
+ self.operators.append(DisambiguateData(self.llm))
+ return self
+
+ def commit_to_hugegraph(self):
+ self.operators.append(Commit2Graph())
+ return self
+
+ def build_vertex_id_semantic_index(self):
+ self.operators.append(BuildSemanticIndex(self.embedding))
+ return self
+
+ def build_vector_index(self):
+ self.operators.append(BuildVectorIndex(self.embedding))
+ return self
+
+ def extract_word(self, text: Optional[str] = None):
+ """
+ Add a word extraction operator to the pipeline.
+
+ :param text: Text to extract words from.
+ :return: Self-instance for chaining.
+ """
+ self.operators.append(WordExtract(text=text))
+ return self
+
+ def extract_keywords(
+ self,
+ text: Optional[str] = None,
+ extract_template: Optional[str] = None,
+ ):
+ """
+ Add a keyword extraction operator to the pipeline.
+
+ :param text: Text to extract keywords from.
+ :param extract_template: Template for keyword extraction.
+ :return: Self-instance for chaining.
+ """
+ self.operators.append(
+ KeywordExtract(text=text, extract_template=extract_template)
+ )
+ return self
+
+ def keywords_to_vid(
+ self,
+ by: Literal["query", "keywords"] = "keywords",
+ topk_per_keyword: int = huge_settings.topk_per_keyword,
+ topk_per_query: int = 10,
+ vector_dis_threshold: float = huge_settings.vector_dis_threshold,
+ ):
+ """
+ Add a semantic ID query operator to the pipeline.
+ :param by: Match by query or keywords.
+ :param topk_per_keyword: Top K results per keyword.
+ :param topk_per_query: Top K results per query.
+ :param vector_dis_threshold: Vector distance threshold.
+ :return: Self-instance for chaining.
+ """
+ self.operators.append(
+ SemanticIdQuery(
+ embedding=self.embedding,
+ by=by,
+ topk_per_keyword=topk_per_keyword,
+ topk_per_query=topk_per_query,
+ vector_dis_threshold=vector_dis_threshold,
+ )
+ )
+ return self
+
+ def query_vector_index(self, max_items: int = 3):
+ """
+ Add a vector index query operator to the pipeline.
+
+ :param max_items: Maximum number of items to retrieve.
+ :return: Self-instance for chaining.
+ """
+ self.operators.append(
+ VectorIndexQuery(
+ embedding=self.embedding,
+ topk=max_items,
+ )
+ )
+ return self
+
+ def merge_dedup_rerank(
+ self,
+ graph_ratio: float = 0.5,
+ rerank_method: Literal["bleu", "reranker"] = "bleu",
+ near_neighbor_first: bool = False,
+ custom_related_information: str = "",
+ topk_return_results: int = huge_settings.topk_return_results,
+ ):
+ """
+ Add a merge, deduplication, and rerank operator to the pipeline.
+
+ :return: Self-instance for chaining.
+ """
+ self.operators.append(
+ MergeDedupRerank(
+ embedding=self.embedding,
+ graph_ratio=graph_ratio,
+ method=rerank_method,
+ near_neighbor_first=near_neighbor_first,
+ custom_related_information=custom_related_information,
+ topk_return_results=topk_return_results,
+ )
+ )
+ return self
+
+ def synthesize_answer(
+ self,
+ raw_answer: bool = False,
+ vector_only_answer: bool = True,
+ graph_only_answer: bool = False,
+ graph_vector_answer: bool = False,
+ answer_prompt: Optional[str] = None,
+ ):
+ """
+ Add an answer synthesis operator to the pipeline.
+
+ :param raw_answer: Whether to return raw answers.
+ :param vector_only_answer: Whether to return vector-only answers.
+ :param graph_only_answer: Whether to return graph-only answers.
+ :param graph_vector_answer: Whether to return graph-vector combined answers.
+ :param answer_prompt: Template for the answer synthesis prompt.
+ :return: Self-instance for chaining.
+ """
+ self.operators.append(
+ AnswerSynthesize(
+ raw_answer=raw_answer,
+ vector_only_answer=vector_only_answer,
+ graph_only_answer=graph_only_answer,
+ graph_vector_answer=graph_vector_answer,
+ prompt_template=answer_prompt,
+ )
+ )
+ return self
+
+ @log_time("total time")
+ @record_rpm
+ def run(self, **kwargs):
+ context = kwargs
+ for operator in self.operators:
+ context = self._run_operator(operator, context)
+ return context
+
+ @log_operator_time
+ def _run_operator(self, operator, context):
+ return operator.run(context)
diff --git a/hugegraph-llm/src/hugegraph_llm/operators/util.py b/hugegraph-llm/src/hugegraph_llm/operators/util.py
deleted file mode 100644
index 60bdc2e..0000000
--- a/hugegraph-llm/src/hugegraph_llm/operators/util.py
+++ /dev/null
@@ -1,27 +0,0 @@
-# Licensed to the Apache Software Foundation (ASF) under one or more
-# contributor license agreements. See the NOTICE file distributed with
-# this work for additional information regarding copyright ownership.
-# The ASF licenses this file to You under the Apache License, Version 2.0
-# (the "License"); you may not use this file except in compliance with
-# the License. You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from PyCGraph import CStatus
-
-
-def init_context(obj) -> CStatus:
- try:
- obj.context = obj.getGParamWithNoEmpty("wkflow_state")
- obj.wk_input = obj.getGParamWithNoEmpty("wkflow_input")
- if obj.context is None or obj.wk_input is None:
- return CStatus(-1, "Required workflow parameters not found")
- return CStatus()
- except Exception as e:
- return CStatus(-1, f"Failed to initialize context: {str(e)}")
diff --git a/hugegraph-llm/src/hugegraph_llm/state/ai_state.py b/hugegraph-llm/src/hugegraph_llm/state/ai_state.py
index 3a6fd3c..429aba9 100644
--- a/hugegraph-llm/src/hugegraph_llm/state/ai_state.py
+++ b/hugegraph-llm/src/hugegraph_llm/state/ai_state.py
@@ -13,64 +13,71 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+from typing import AsyncGenerator, Union, List, Optional, Any, Dict
from PyCGraph import GParam, CStatus
-from typing import Union, List, Optional, Any
+from hugegraph_llm.utils.log import log
class WkFlowInput(GParam):
- texts: Union[str, List[str]] = None # texts input used by ChunkSplit Node
- language: str = None # language configuration used by ChunkSplit Node
- split_type: str = None # split type used by ChunkSplit Node
- example_prompt: str = None # need by graph information extract
- schema: str = None # Schema information requeired by SchemaNode
- data_json = None
- extract_type = None
- query_examples = None
- few_shot_schema = None
+ texts: Optional[Union[str, List[str]]] = None # texts input used by ChunkSplit Node
+ language: Optional[str] = None # language configuration used by ChunkSplit Node
+ split_type: Optional[str] = None # split type used by ChunkSplit Node
+ example_prompt: Optional[str] = None # need by graph information extract
+ schema: Optional[str] = None # Schema information requeired by SchemaNode
+ data_json: Optional[Dict[str, Any]] = None
+ extract_type: Optional[str] = None
+ query_examples: Optional[Any] = None
+ few_shot_schema: Optional[Any] = None
# Fields related to PromptGenerate
- source_text: str = None # Original text
- scenario: str = None # Scenario description
- example_name: str = None # Example name
+ source_text: Optional[str] = None # Original text
+ scenario: Optional[str] = None # Scenario description
+ example_name: Optional[str] = None # Example name
# Fields for Text2Gremlin
- example_num: int = None
- gremlin_prompt: str = None
+ example_num: Optional[int] = None
requested_outputs: Optional[List[str]] = None
# RAG Flow related fields
- query: str = None # User query for RAG
- vector_search: bool = None # Enable vector search
- graph_search: bool = None # Enable graph search
- raw_answer: bool = None # Return raw answer
- vector_only_answer: bool = None # Vector only answer mode
- graph_only_answer: bool = None # Graph only answer mode
- graph_vector_answer: bool = None # Combined graph and vector answer
- graph_ratio: float = None # Graph ratio for merging
- rerank_method: str = None # Reranking method
- near_neighbor_first: bool = None # Near neighbor first flag
- custom_related_information: str = None # Custom related information
- answer_prompt: str = None # Answer generation prompt
- keywords_extract_prompt: str = None # Keywords extraction prompt
- gremlin_tmpl_num: int = None # Gremlin template number
- gremlin_prompt: str = None # Gremlin generation prompt
- max_graph_items: int = None # Maximum graph items
- topk_return_results: int = None # Top-k return results
- vector_dis_threshold: float = None # Vector distance threshold
- topk_per_keyword: int = None # Top-k per keyword
- max_keywords: int = None
- max_items: int = None
+ query: Optional[str] = None # User query for RAG
+ vector_search: Optional[bool] = None # Enable vector search
+ graph_search: Optional[bool] = None # Enable graph search
+ raw_answer: Optional[bool] = None # Return raw answer
+ vector_only_answer: Optional[bool] = None # Vector only answer mode
+ graph_only_answer: Optional[bool] = None # Graph only answer mode
+ graph_vector_answer: Optional[bool] = None # Combined graph and vector answer
+ graph_ratio: Optional[float] = None # Graph ratio for merging
+ rerank_method: Optional[str] = None # Reranking method
+ near_neighbor_first: Optional[bool] = None # Near neighbor first flag
+ custom_related_information: Optional[str] = None # Custom related information
+ answer_prompt: Optional[str] = None # Answer generation prompt
+ keywords_extract_prompt: Optional[str] = None # Keywords extraction prompt
+ gremlin_tmpl_num: Optional[int] = None # Gremlin template number
+ gremlin_prompt: Optional[str] = None # Gremlin generation prompt
+ max_graph_items: Optional[int] = None # Maximum graph items
+ topk_return_results: Optional[int] = None # Top-k return results
+ vector_dis_threshold: Optional[float] = None # Vector distance threshold
+ topk_per_keyword: Optional[int] = None # Top-k per keyword
+ max_keywords: Optional[int] = None
+ max_items: Optional[int] = None
# Semantic query related fields
- semantic_by: str = None # Semantic query method
- topk_per_query: int = None # Top-k per query
+ semantic_by: Optional[str] = None # Semantic query method
+ topk_per_query: Optional[int] = None # Top-k per query
# Graph query related fields
- max_deep: int = None # Maximum depth for graph traversal
- max_v_prop_len: int = None # Maximum vertex property length
- max_e_prop_len: int = None # Maximum edge property length
- prop_to_match: str = None # Property to match
+ max_deep: Optional[int] = None # Maximum depth for graph traversal
+ max_v_prop_len: Optional[int] = None # Maximum vertex property length
+ max_e_prop_len: Optional[int] = None # Maximum edge property length
+ prop_to_match: Optional[str] = None # Property to match
- stream: bool = None # used for recognize stream mode
+ stream: Optional[bool] = None # used for recognize stream mode
+
+ # used for rag_recall api
+ is_graph_rag_recall: bool = False
+ is_vector_only: bool = False
+
+ # used for build text2gremin index
+ examples: Optional[List[Dict[str, str]]] = None
def reset(self, _: CStatus) -> None:
self.texts = None
@@ -78,7 +85,6 @@
self.split_type = None
self.example_prompt = None
self.schema = None
- self.graph_name = None
self.data_json = None
self.extract_type = None
self.query_examples = None
@@ -106,7 +112,6 @@
self.answer_prompt = None
self.keywords_extract_prompt = None
self.gremlin_tmpl_num = None
- self.gremlin_prompt = None
self.max_graph_items = None
self.topk_return_results = None
self.vector_dis_threshold = None
@@ -123,6 +128,10 @@
self.prop_to_match = None
self.stream = None
+ self.examples = None
+ self.is_graph_rag_recall = False
+ self.is_vector_only = False
+
class WkFlowState(GParam):
schema: Optional[str] = None # schema message
@@ -134,9 +143,9 @@
call_count: Optional[int] = None
keywords: Optional[List[str]] = None
- vector_result = None
- graph_result = None
- keywords_embeddings = None
+ vector_result: Optional[Any] = None
+ graph_result: Optional[Any] = None
+ keywords_embeddings: Optional[Any] = None
generated_extract_prompt: Optional[str] = None
# Fields for Text2Gremlin results
@@ -146,18 +155,43 @@
template_exec_res: Optional[Any] = None
raw_exec_res: Optional[Any] = None
- match_vids = None
- vector_result = None
- graph_result = None
+ match_vids: Optional[Any] = None
- raw_answer: str = None
- vector_only_answer: str = None
- graph_only_answer: str = None
- graph_vector_answer: str = None
+ raw_answer: Optional[str] = None
+ vector_only_answer: Optional[str] = None
+ graph_only_answer: Optional[str] = None
+ graph_vector_answer: Optional[str] = None
- merged_result = None
+ merged_result: Optional[Any] = None
- def setup(self):
+ vertex_num: Optional[int] = None
+ edge_num: Optional[int] = None
+ note: Optional[str] = None
+ removed_vid_vector_num: Optional[int] = None
+ added_vid_vector_num: Optional[int] = None
+ raw_texts: Optional[List] = None
+ query_examples: Optional[List] = None
+ few_shot_schema: Optional[Dict] = None
+ source_text: Optional[str] = None
+ scenario: Optional[str] = None
+ example_name: Optional[str] = None
+
+ graph_ratio: Optional[float] = None
+ query: Optional[str] = None
+ vector_search: Optional[bool] = None
+ graph_search: Optional[bool] = None
+ max_graph_items: Optional[int] = None
+ stream_generator: Optional[AsyncGenerator] = None
+
+ graph_result_flag: Optional[int] = None
+ vertex_degree_list: Optional[List] = None
+ knowledge_with_degree: Optional[Dict] = None
+ graph_context_head: Optional[str] = None
+
+ embed_dim: Optional[int] = None
+ is_graph_rag_recall: Optional[bool] = None
+
+ def setup(self) -> CStatus:
self.schema = None
self.simple_schema = None
self.chunks = None
@@ -184,9 +218,36 @@
self.graph_only_answer = None
self.graph_vector_answer = None
- self.vector_result = None
- self.graph_result = None
self.merged_result = None
+
+ self.match_vids = None
+ self.vertex_num = None
+ self.edge_num = None
+ self.note = None
+ self.removed_vid_vector_num = None
+ self.added_vid_vector_num = None
+
+ self.raw_texts = None
+ self.query_examples = None
+ self.few_shot_schema = None
+ self.source_text = None
+ self.scenario = None
+ self.example_name = None
+
+ self.graph_ratio = None
+ self.query = None
+ self.vector_search = None
+ self.graph_search = None
+ self.max_graph_items = None
+
+ self.stream_generator = None
+ self.graph_result_flag = None
+ self.vertex_degree_list = None
+ self.knowledge_with_degree = None
+ self.graph_context_head = None
+
+ self.embed_dim = None
+ self.is_graph_rag_recall = None
return CStatus()
def to_json(self):
@@ -210,4 +271,9 @@
Assigns each key in the input json object as a member variable of WkFlowState.
"""
for k, v in data_json.items():
- setattr(self, k, v)
+ if hasattr(self, k):
+ setattr(self, k, v)
+ else:
+ log.warning(
+ "key %s should be a member of WkFlowState & type %s", k, type(v)
+ )
diff --git a/hugegraph-llm/src/hugegraph_llm/utils/graph_index_utils.py b/hugegraph-llm/src/hugegraph_llm/utils/graph_index_utils.py
index 3f527f2..9c53e81 100644
--- a/hugegraph-llm/src/hugegraph_llm/utils/graph_index_utils.py
+++ b/hugegraph-llm/src/hugegraph_llm/utils/graph_index_utils.py
@@ -16,29 +16,28 @@
# under the License.
-import json
import os
import traceback
-from typing import Dict, Any, Union, Optional
+from typing import Dict, Any, Union, List
import gradio as gr
+from hugegraph_llm.flows import FlowName
from hugegraph_llm.flows.scheduler import SchedulerSingleton
+from pyhugegraph.client import PyHugeClient
from .embedding_utils import get_filename_prefix, get_index_folder_name
-from .hugegraph_utils import get_hg_client, clean_hg_data
+from .hugegraph_utils import clean_hg_data
from .log import log
from .vector_index_utils import read_documents
from ..config import resource_path, huge_settings, llm_settings
from ..indices.vector_index import VectorIndex
from ..models.embeddings.init_embedding import Embeddings
-from ..models.llms.init_llm import LLMs
-from ..operators.kg_construction_task import KgBuilder
def get_graph_index_info():
try:
scheduler = SchedulerSingleton.get_instance()
- return scheduler.schedule_flow("get_graph_index_info")
+ return scheduler.schedule_flow(FlowName.GET_GRAPH_INDEX_INFO)
except Exception as e: # pylint: disable=broad-exception-caught
log.error(e)
raise gr.Error(str(e))
@@ -63,65 +62,33 @@
gr.Info("Clear graph index and text2gql index successfully!")
+def get_vertex_details(
+ vertex_ids: List[str], context: Dict[str, Any]
+) -> List[Dict[str, Any]]:
+ if isinstance(context.get("graph_client"), PyHugeClient):
+ client = context["graph_client"]
+ else:
+ url = context.get("url") or "http://localhost:8080"
+ graph = context.get("graph") or "hugegraph"
+ user = context.get("user") or "admin"
+ pwd = context.get("pwd") or "admin"
+ gs = context.get("graphspace") or None
+ client = PyHugeClient(url, graph, user, pwd, gs)
+ if not vertex_ids:
+ return []
+
+ formatted_ids = ", ".join(f"'{vid}'" for vid in vertex_ids)
+ gremlin_query = f"g.V({formatted_ids}).limit(20)"
+ result = client.gremlin().exec(gremlin=gremlin_query)["data"]
+ return result
+
+
def clean_all_graph_data():
clean_hg_data()
log.warning("Clear graph data successfully!")
gr.Info("Clear graph data successfully!")
-def parse_schema(schema: str, builder: KgBuilder) -> Optional[str]:
- schema = schema.strip()
- if schema.startswith("{"):
- try:
- schema = json.loads(schema)
- builder.import_schema(from_user_defined=schema)
- except json.JSONDecodeError:
- log.error("Invalid JSON format in schema. Please check it again.")
- return "ERROR: Invalid JSON format in schema. Please check it carefully."
- else:
- log.info("Get schema '%s' from graphdb.", schema)
- builder.import_schema(from_hugegraph=schema)
- return None
-
-
-def extract_graph_origin(input_file, input_text, schema, example_prompt) -> str:
- texts = read_documents(input_file, input_text)
- builder = KgBuilder(
- LLMs().get_chat_llm(), Embeddings().get_embedding(), get_hg_client()
- )
- if not schema:
- return "ERROR: please input with correct schema/format."
-
- error_message = parse_schema(schema, builder)
- if error_message:
- return error_message
- builder.chunk_split(texts, "document", "zh").extract_info(
- example_prompt, "property_graph"
- )
-
- try:
- context = builder.run()
- if not context["vertices"] and not context["edges"]:
- log.info("Please check the schema.(The schema may not match the Doc)")
- return json.dumps(
- {
- "vertices": context["vertices"],
- "edges": context["edges"],
- "warning": "The schema may not match the Doc",
- },
- ensure_ascii=False,
- indent=2,
- )
- return json.dumps(
- {"vertices": context["vertices"], "edges": context["edges"]},
- ensure_ascii=False,
- indent=2,
- )
- except Exception as e: # pylint: disable=broad-exception-caught
- log.error(e)
- raise gr.Error(str(e))
-
-
def extract_graph(input_file, input_text, schema, example_prompt) -> str:
texts = read_documents(input_file, input_text)
scheduler = SchedulerSingleton.get_instance()
@@ -130,7 +97,7 @@
try:
return scheduler.schedule_flow(
- "graph_extract", schema, texts, example_prompt, "property_graph"
+ FlowName.GRAPH_EXTRACT, schema, texts, example_prompt, "property_graph"
)
except Exception as e: # pylint: disable=broad-exception-caught
log.error(e)
@@ -140,7 +107,7 @@
def update_vid_embedding():
scheduler = SchedulerSingleton.get_instance()
try:
- return scheduler.schedule_flow("update_vid_embeddings")
+ return scheduler.schedule_flow(FlowName.UPDATE_VID_EMBEDDINGS)
except Exception as e: # pylint: disable=broad-exception-caught
log.error(e)
raise gr.Error(str(e))
@@ -149,7 +116,7 @@
def import_graph_data(data: str, schema: str) -> Union[str, Dict[str, Any]]:
try:
scheduler = SchedulerSingleton.get_instance()
- return scheduler.schedule_flow("import_graph_data", data, schema)
+ return scheduler.schedule_flow(FlowName.IMPORT_GRAPH_DATA, data, schema)
except Exception as e: # pylint: disable=W0718
log.error(e)
traceback.print_exc()
@@ -162,7 +129,8 @@
scheduler = SchedulerSingleton.get_instance()
try:
return scheduler.schedule_flow(
- "build_schema", input_text, query_example, few_shot
+ FlowName.BUILD_SCHEMA, input_text, query_example, few_shot
)
- except (TypeError, ValueError) as e:
+ except Exception as e: # pylint: disable=broad-exception-caught
+ log.error("Schema generation failed: %s", e)
raise gr.Error(f"Schema generation failed: {e}")
diff --git a/hugegraph-llm/src/hugegraph_llm/utils/vector_index_utils.py b/hugegraph-llm/src/hugegraph_llm/utils/vector_index_utils.py
index 301a6bd..67904a4 100644
--- a/hugegraph-llm/src/hugegraph_llm/utils/vector_index_utils.py
+++ b/hugegraph-llm/src/hugegraph_llm/utils/vector_index_utils.py
@@ -22,6 +22,7 @@
import gradio as gr
from hugegraph_llm.config import resource_path, huge_settings, llm_settings
+from hugegraph_llm.flows import FlowName
from hugegraph_llm.indices.vector_index import VectorIndex
from hugegraph_llm.models.embeddings.init_embedding import model_map
from hugegraph_llm.flows.scheduler import SchedulerSingleton
@@ -50,7 +51,9 @@
texts.append(text)
elif full_path.endswith(".pdf"):
# TODO: support PDF file
- raise gr.Error("PDF will be supported later! Try to upload text/docx now")
+ raise gr.Error(
+ "PDF will be supported later! Try to upload text/docx now"
+ )
else:
raise gr.Error("Please input txt or docx file.")
else:
@@ -60,7 +63,9 @@
# pylint: disable=C0301
def get_vector_index_info():
- folder_name = get_index_folder_name(huge_settings.graph_name, huge_settings.graph_space)
+ folder_name = get_index_folder_name(
+ huge_settings.graph_name, huge_settings.graph_space
+ )
filename_prefix = get_filename_prefix(
llm_settings.embedding_type, model_map.get(llm_settings.embedding_type)
)
@@ -87,11 +92,15 @@
def clean_vector_index():
- folder_name = get_index_folder_name(huge_settings.graph_name, huge_settings.graph_space)
+ folder_name = get_index_folder_name(
+ huge_settings.graph_name, huge_settings.graph_space
+ )
filename_prefix = get_filename_prefix(
llm_settings.embedding_type, model_map.get(llm_settings.embedding_type)
)
- VectorIndex.clean(str(os.path.join(resource_path, folder_name, "chunks")), filename_prefix)
+ VectorIndex.clean(
+ str(os.path.join(resource_path, folder_name, "chunks")), filename_prefix
+ )
gr.Info("Clean vector index successfully!")
@@ -100,4 +109,4 @@
raise gr.Error("Please only choose one between file and text.")
texts = read_documents(input_file, input_text)
scheduler = SchedulerSingleton.get_instance()
- return scheduler.schedule_flow("build_vector_index", texts)
+ return scheduler.schedule_flow(FlowName.BUILD_VECTOR_INDEX, texts)
diff --git a/hugegraph-ml/pyproject.toml b/hugegraph-ml/pyproject.toml
index 6d46ba7..929eb3a 100644
--- a/hugegraph-ml/pyproject.toml
+++ b/hugegraph-ml/pyproject.toml
@@ -22,7 +22,7 @@
[project]
name = "hugegraph-ml"
-version = "1.5.0"
+version = "1.7.0"
description = "Machine learning extensions for Apache HugeGraph."
authors = [
{ name = "Apache HugeGraph Contributors", email = "dev@hugegraph.apache.org" },
diff --git a/hugegraph-python-client/pyproject.toml b/hugegraph-python-client/pyproject.toml
index 81565d9..ddae125 100644
--- a/hugegraph-python-client/pyproject.toml
+++ b/hugegraph-python-client/pyproject.toml
@@ -17,7 +17,7 @@
[project]
name = "hugegraph-python-client"
-version = "1.5.0"
+version = "1.7.0"
description = "A Python SDK for Apache HugeGraph Database."
authors = [
{ name = "Apache HugeGraph Contributors", email = "dev@hugegraph.apache.org" },
diff --git a/pyproject.toml b/pyproject.toml
index 8bcf589..2dd4161 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -17,7 +17,7 @@
[project]
name = "hugegraph-ai"
-version = "1.5.0"
+version = "1.7.0"
description = "A repository for AI-related projects for Apache HugeGraph."
authors = [
{ name = "Apache HugeGraph Contributors", email = "dev@hugegraph.apache.org" },
diff --git a/scripts/build_llm_image.sh b/scripts/build_llm_image.sh
old mode 100644
new mode 100755
index 42aa36e..7425b3d
--- a/scripts/build_llm_image.sh
+++ b/scripts/build_llm_image.sh
@@ -18,7 +18,7 @@
set -e
-tag="1.5.0"
+tag="1.7.0"
script_dir=$(realpath "$(dirname "$0")")
diff --git a/.vibedev/spec/hugegraph-llm/fixed_flow/design.md b/spec/hugegraph-llm/fixed_flow/design.md
similarity index 99%
rename from .vibedev/spec/hugegraph-llm/fixed_flow/design.md
rename to spec/hugegraph-llm/fixed_flow/design.md
index c577723..5ad6440 100644
--- a/.vibedev/spec/hugegraph-llm/fixed_flow/design.md
+++ b/spec/hugegraph-llm/fixed_flow/design.md
@@ -202,7 +202,7 @@
- `BuildVectorIndexFlow`: 向量索引构建工作流
- `GraphExtractFlow`: 图抽取工作流
- `ImportGraphDataFlow`: 图数据导入工作流
- - `UpdateVidEmbeddingsFlows`: 向量更新工作流
+ - `UpdateVidEmbeddingsFlow`: 向量更新工作流
- `GetGraphIndexInfoFlow`: 图索引信息获取工作流
- `BuildSchemaFlow`: 模式构建工作流
- `PromptGenerateFlow`: 提示词生成工作流
@@ -407,7 +407,6 @@
prepared_input.split_type = "document"
prepared_input.example_prompt = example_prompt
prepared_input.schema = schema
- prepare_schema(prepared_input, schema)
return
def build_flow(self, schema, texts, example_prompt, extract_type):
diff --git a/.vibedev/spec/hugegraph-llm/fixed_flow/requirements.md b/spec/hugegraph-llm/fixed_flow/requirements.md
similarity index 100%
rename from .vibedev/spec/hugegraph-llm/fixed_flow/requirements.md
rename to spec/hugegraph-llm/fixed_flow/requirements.md
diff --git a/.vibedev/spec/hugegraph-llm/fixed_flow/tasks.md b/spec/hugegraph-llm/fixed_flow/tasks.md
similarity index 100%
rename from .vibedev/spec/hugegraph-llm/fixed_flow/tasks.md
rename to spec/hugegraph-llm/fixed_flow/tasks.md
diff --git a/style/pylint.conf b/style/pylint.conf
index 6ccb7a0..4fb3a17 100644
--- a/style/pylint.conf
+++ b/style/pylint.conf
@@ -476,6 +476,7 @@
# it should appear only once). See also the "--disable" option for examples.
enable=
+extension-pkg-whitelist=PyCGraph
[METHOD_ARGS]
@@ -596,7 +597,8 @@
# List of members which are set dynamically and missed by pylint inference
# system, and so shouldn't trigger E1101 when accessed. Python regular
# expressions are accepted.
-generated-members=
+ignored-modules=PyCGraph
+generated-members=PyCGraph.*
# Tells whether to warn about missing members when the owner of the attribute
# is inferred to be None.
diff --git a/vermeer-python-client/pyproject.toml b/vermeer-python-client/pyproject.toml
index 9860108..d60acc0 100644
--- a/vermeer-python-client/pyproject.toml
+++ b/vermeer-python-client/pyproject.toml
@@ -17,7 +17,7 @@
[project]
name = "vermeer-python-client"
-version = "1.5.0" # Independently managed version for the vermeer-python-client package
+version = "1.7.0" # Independently managed version for the vermeer-python-client package
description = "A Python client library for interacting with Vermeer, a tool for managing and analyzing large-scale graph data."
authors = [
{ name = "Apache HugeGraph Contributors", email = "dev@hugegraph.apache.org" }
@@ -33,7 +33,7 @@
"setuptools",
"urllib3",
"rich",
-
+
# Vermeer specific dependencies
"python-dateutil",
]