English • 简体中文 • 繁體中文 • 日本語 • 한국어 • Español • Français • Deutsch • العربية • Türkçe • Tiếng Việt • বাংলা • Română • Polski • हिन्दी • فارسی • Slovenščina • Bahasa Indonesia • Português • Русский • Italiano • ไทย • Українська
![]()


![]()
![]()
Apache Doris 是一個基於 MPP 架構的易用、高效能、即時的分析型資料庫,以其極速和易用性而聞名。它僅需亞秒級響應時間即可返回海量資料下的查詢結果,不僅可以支援高併發的點查詢場景,也能支援高吞吐的複雜分析場景。
所有這些特性使得 Apache Doris 成為報表分析、即席查詢、統一數倉構建、資料湖查詢加速等場景的理想工具。在 Apache Doris 上,使用者可以構建各種應用,如使用者行為分析、AB 測試平台、日誌檢索分析、使用者畫像分析、訂單分析等。
🎉 查看 🔗所有版本,您將找到過去一年發布的 Apache Doris 版本的按時間順序總結。
👀 探索 🔗官方網站,詳細了解 Apache Doris 的核心功能、部落格和使用者案例。
如下圖所示,經過各種資料整合和處理後,資料來源通常儲存在即時資料倉庫 Apache Doris 和離線資料湖或資料倉庫(在 Apache Hive、Apache Iceberg 或 Apache Hudi 中)中。
Apache Doris 廣泛應用於以下場景:
即時資料分析:
即時報表和決策:Doris 為內部和外部企業使用提供即時更新的報表和儀表板,支援自動化流程中的即時決策。
即席分析:Doris 提供多維資料分析能力,支援快速商業智慧分析和即席查詢,幫助使用者快速從複雜資料中挖掘洞察。
使用者畫像和行為分析:Doris 可以分析使用者行為,如參與度、留存率和轉化率,同時支援人群洞察和人群選擇等行為分析場景。
資料湖分析:
資料湖查詢加速:Doris 通過其高效的查詢引擎加速資料湖資料查詢。
聯邦分析:Doris 支援跨多個資料來源的聯邦查詢,簡化架構並消除資料孤島。
即時資料處理:Doris 結合即時資料流和批次處理能力,滿足高併發和低延遲複雜業務需求。
基於 SQL 的可觀測性:
Apache Doris 使用 MySQL 協定,與 MySQL 語法高度相容,並支援標準 SQL。使用者可以通過各種客戶端工具存取 Apache Doris,並且它可以與 BI 工具無縫整合。
Apache Doris 的存算一體架構簡潔且易於維護。如下圖所示,它僅由兩種類型的程序組成:
Frontend (FE): 主要負責處理使用者請求、查詢解析和規劃、元資料管理和節點管理任務。
Backend (BE): 主要負責資料儲存和查詢執行。資料被分割為分片,並在 BE 節點之間以多個副本儲存。
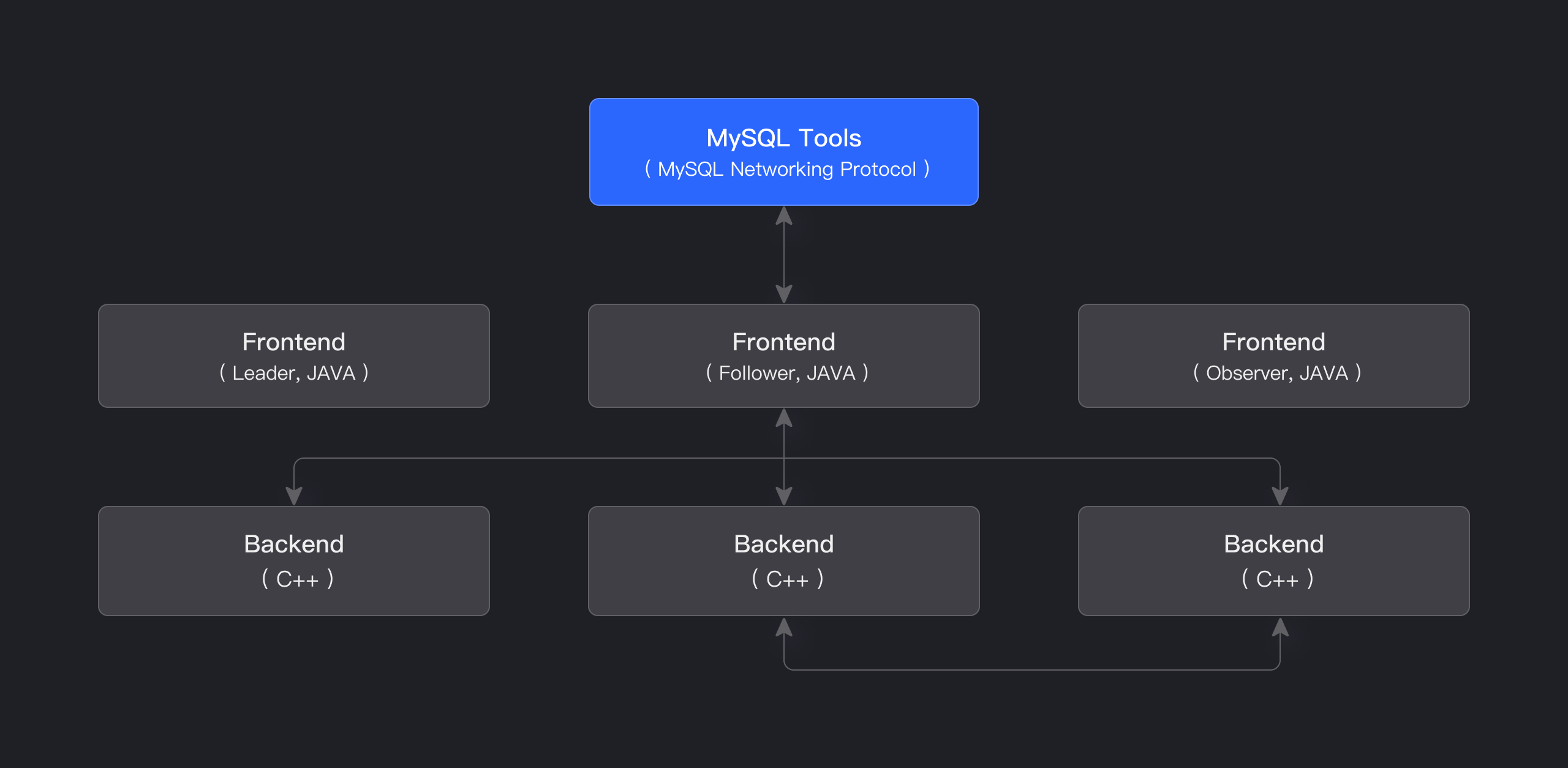
在生產環境中,可以部署多個 FE 節點以實現容災。每個 FE 節點維護元資料的完整副本。FE 節點分為三種角色:
| 角色 | 功能 |
|---|---|
| Master | FE Master 節點負責元資料的讀寫操作。當 Master 節點發生元資料變更時,它們通過 BDB JE 協定同步到 Follower 或 Observer 節點。 |
| Follower | Follower 節點負責讀取元資料。如果 Master 節點失敗,可以選擇 Follower 節點作為新的 Master。 |
| Observer | Observer 節點負責讀取元資料,主要用於增加查詢併發。它不參與叢集領導選舉。 |
FE 和 BE 程序都可以水平擴展,使單個叢集能夠支援數百台機器和數十 PB 的儲存容量。FE 和 BE 程序使用一致性協定來確保服務的高可用性和資料的高可靠性。存算一體架構高度整合,顯著降低了分散式系統的運維複雜度。
高可用性:在 Apache Doris 中,元資料和資料都以多個副本儲存,通過 quorum 協定同步資料日誌。一旦大多數副本完成寫入,資料寫入即被視為成功,確保即使少數節點失敗,叢集仍然可用。Apache Doris 支援同城和跨地域容災,支援雙叢集主從模式。當某些節點出現故障時,叢集可以自動隔離故障節點,防止整體叢集可用性受到影響。
高相容性:Apache Doris 與 MySQL 協定高度相容,支援標準 SQL 語法,涵蓋大多數 MySQL 和 Hive 函數。這種高相容性使使用者能夠無縫遷移和整合現有應用程式和工具。Apache Doris 支援 MySQL 生態系統,使使用者能夠使用 MySQL 客戶端工具連接 Doris,實現更便捷的運維。它還支援 BI 報表工具和資料傳輸工具的 MySQL 協定相容性,確保資料分析和資料傳輸過程的效率和穩定性。
即時資料倉庫:基於 Apache Doris,可以構建即時資料倉庫服務。Apache Doris 提供秒級資料擷取能力,在幾秒鐘內將上游線上事務資料庫的增量變更捕獲到 Doris 中。利用向量化引擎、MPP 架構和 Pipeline 執行引擎,Doris 提供亞秒級資料查詢能力,從而構建高效能、低延遲的即時資料倉庫平台。
統一資料湖:Apache Doris 可以基於外部資料來源(如資料湖或關聯式資料庫)構建統一資料湖架構。Doris 統一資料湖解決方案實現了資料湖和資料倉庫之間的無縫整合和自由資料流動,幫助使用者直接利用資料倉庫能力解決資料湖中的資料分析問題,同時充分利用資料湖資料管理能力來增強資料價值。
靈活建模:Apache Doris 提供各種建模方法,如寬表模型、預聚合模型、星型/雪花型模式等。在資料匯入期間,資料可以扁平化為寬表,並通過 Flink 或 Spark 等計算引擎寫入 Doris,或者資料可以直接匯入到 Doris,通過視圖、物化視圖或即時多表連接執行資料建模操作。
Doris 提供高效的 SQL 介面,完全相容 MySQL 協定。其查詢引擎基於 MPP(大規模並行處理)架構,能夠高效執行複雜的分析查詢並實現低延遲即時查詢。通過用於資料編碼和壓縮的列式儲存技術,它顯著優化了查詢效能和儲存壓縮比。
Apache Doris 採用 MySQL 協定,支援標準 SQL,並與 MySQL 語法高度相容。使用者可以通過各種客戶端工具存取 Apache Doris,並與 BI 工具無縫整合,包括但不限於 Smartbi、DataEase、FineBI、Tableau、Power BI 和 Apache Superset。Apache Doris 可以作為任何支援 MySQL 協定的 BI 工具的資料來源。
Apache Doris 具有列式儲存引擎,按列對資料進行編碼、壓縮和讀取。這使得資料壓縮比非常高,並大大減少了不必要的資料掃描,從而更有效地利用 IO 和 CPU 資源。
Apache Doris 支援各種索引結構以最小化資料掃描:
排序複合鍵索引:使用者最多可以指定三列形成複合排序鍵。這可以有效地剪枝資料,更好地支援高併發報表場景。
Min/Max 索引:這在數值類型的等價和範圍查詢中實現有效的資料過濾。
BloomFilter 索引:這在等價過濾和高基數列的剪枝中非常有效。
倒排索引:這實現了對任何欄位的快速搜尋。
Apache Doris 支援多種資料模型,並針對不同場景進行了優化:
明細模型(Duplicate Key Model): 一種明細資料模型,旨在滿足事實表的詳細儲存需求。
主鍵模型(Unique Key Model): 確保唯一鍵;具有相同鍵的資料會被覆蓋,實現行級資料更新。
聚合模型(Aggregate Key Model): 合併具有相同鍵的值列,通過預聚合顯著提高效能。
Apache Doris 還支援強一致的单表物化視圖和異步刷新的多表物化視圖。单表物化視圖由系統自動刷新和維護,無需使用者手動干預。多表物化視圖可以使用叢集內排程或外部排程工具定期刷新,降低資料建模的複雜度。
Apache Doris 具有基於 MPP 的查詢引擎,用於節點間和節點內的並行執行。它支援大表的分散式 shuffle join,以更好地處理複雜查詢。
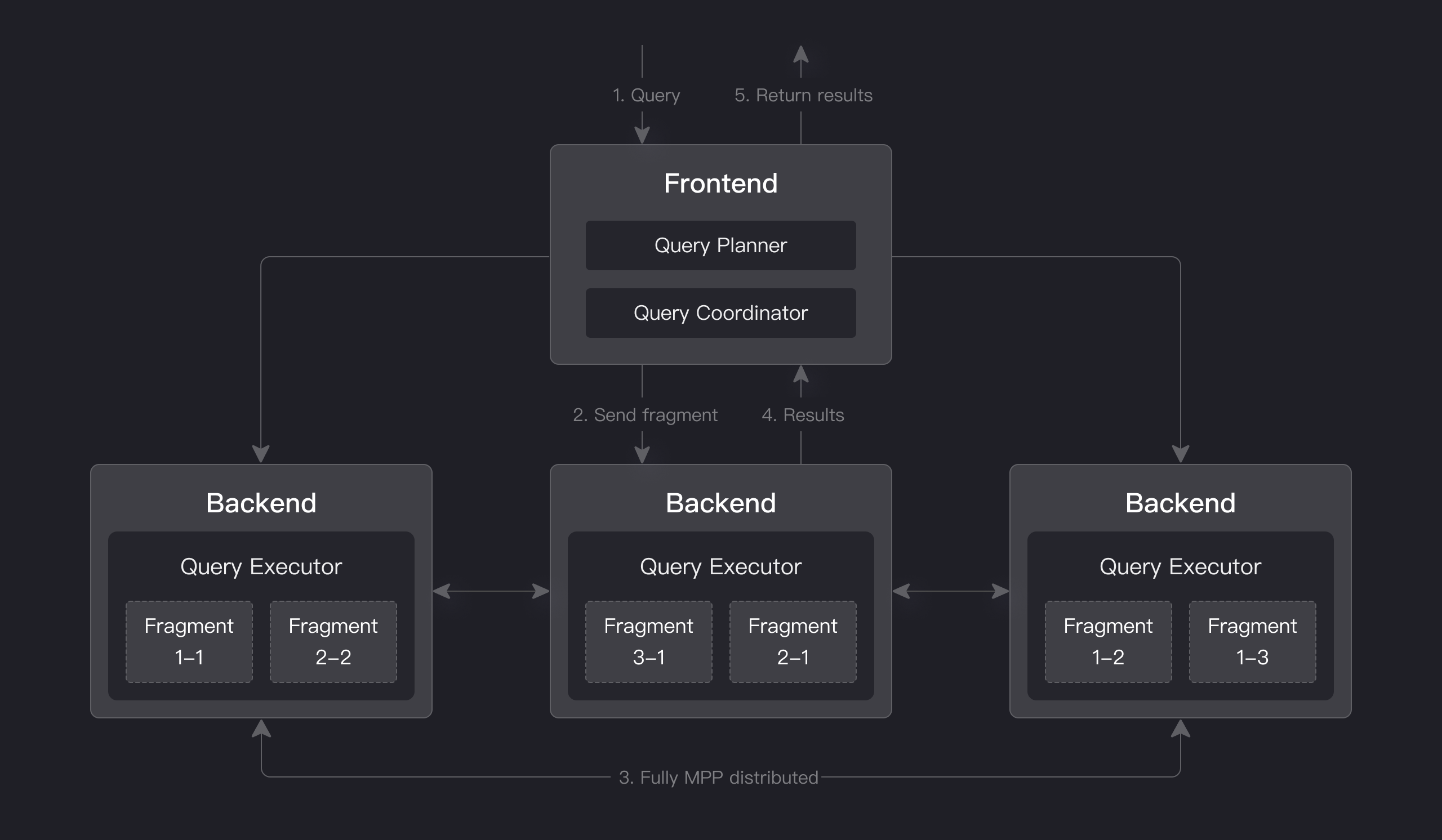
Apache Doris 的查詢引擎完全向量化,所有記憶體結構都以列式格式佈局。這可以大大減少虛函數呼叫,提高快取命中率,並有效利用 SIMD 指令。Apache Doris 在寬表聚合場景中的效能比非向量化引擎高 5~10 倍。

Apache Doris 使用自適應查詢執行技術,根據執行時統計資訊動態調整執行計劃。例如,它可以生成執行時過濾器並將其推送到探測端。具體來說,它將過濾器推送到探測端最底層的掃描節點,這大大減少了要處理的資料量並提高了連接效能。Apache Doris 的執行時過濾器支援 In/Min/Max/Bloom Filter。
Apache Doris 使用 Pipeline 執行引擎,將查詢分解為多個子任務進行並行執行,充分利用多核 CPU 能力。它同時通過限制查詢執行緒數來解決執行緒爆炸問題。Pipeline 執行引擎減少了資料複製和共享,優化了排序和聚合操作,從而顯著提高了查詢效率和吞吐量。
在優化器方面,Apache Doris 採用 CBO(基於成本的優化器)、RBO(基於規則的優化器)和 HBO(基於歷史的優化器)的組合優化策略。RBO 支援常數折疊、子查詢重寫、謂詞下推等。CBO 支援連接重排序和其他優化。HBO 根據歷史查詢資訊推薦最佳執行計劃。這些多重優化措施確保 Doris 能夠在各種類型的查詢中枚舉高效能查詢計劃。
🎯 易於使用:兩個程序,無其他依賴;線上叢集擴展,自動副本恢復;相容 MySQL 協定,使用標準 SQL。
🚀 高效能:通過列式儲存引擎、現代 MPP 架構、向量化查詢引擎、預聚合物化視圖和資料索引,實現低延遲和高吞吐量查詢的極快效能。
🖥️ 統一系統:單一系統可以支援即時資料服務、互動式資料分析和離線資料處理場景。
⚛️ 聯邦查詢:支援對 Hive、Iceberg、Hudi 等資料湖和 MySQL、Elasticsearch 等資料庫進行聯邦查詢。
⏩ 多種資料匯入方式:支援從 HDFS/S3 批次匯入和從 MySQL Binlog/Kafka 串流匯入;支援通過 HTTP 介面進行微批次寫入和使用 JDBC 中的 Insert 進行即時寫入。
🚙 豐富生態:Spark 使用 Spark-Doris-Connector 讀寫 Doris;Flink-Doris-Connector 使 Flink CDC 能夠實現精確一次的資料寫入到 Doris;提供 DBT Doris Adapter 以使用 DBT 在 Doris 中轉換資料。
Apache Doris 已成功從 Apache 孵化器畢業,並於 2022 年 6 月成為頂級專案。
我們深深感謝 🔗社群貢獻者 對 Apache Doris 的貢獻。
Apache Doris 現在在中國和世界各地擁有廣泛的使用者基礎,截至今天,Apache Doris 在全球數千家公司的生產環境中使用。按市值或估值計算,中國前 50 大網際網路公司中超過 80% 的公司長期使用 Apache Doris,包括百度、美團、小米、京東、字節跳動、騰訊、網易、快手、新浪、360、米哈遊和貝殼控股。它還在金融、能源、製造業和電信等一些傳統行業中得到廣泛應用。
Apache Doris 的使用者:🔗使用者
在 Apache Doris 網站上新增您的公司徽標:🔗新增您的公司
所有文件 🔗文件
所有版本和二進位版本 🔗下載
查看如何編譯 🔗編譯)
查看如何安裝和部署 🔗安裝和部署
Doris 通過 Connector 支援 Spark/Flink 讀取儲存在 Doris 中的資料,也支援通過 Connector 將資料寫入 Doris。
郵件列表是 Apache 社群中最受認可的交流形式。查看如何 🔗訂閱郵件列表
如果您遇到任何問題,請隨時提交 🔗GitHub Issue 或在 🔗GitHub Discussion 中發布,並通過提交 🔗Pull Request 來修復
我們歡迎您的建議、評論(包括批評)、意見和貢獻。查看 🔗如何貢獻 和 🔗程式碼提交指南
🔗Doris 改進提案 (DSIP) 可以被視為 所有主要功能更新或改進的設計文件集合。
🔗 後端 C++ 編碼規範 應嚴格遵守,這將幫助我們實現更好的程式碼品質。
通過以下郵件列表聯絡我們。
| 名稱 | 範圍 | |||
|---|---|---|---|---|
| dev@doris.apache.org | 開發相關討論 | 訂閱 | 取消訂閱 | 歸檔 |
注意 某些第三方依賴項的許可證與 Apache 2.0 許可證不相容。因此,您需要停用某些 Doris 功能以符合 Apache 2.0 許可證。有關詳細資訊,請參閱
thirdparty/LICENSE.txt