العربية • বাংলা • Deutsch • English • Español • فارسی • Français • हिन्दी • Bahasa Indonesia • Italiano • 日本語 • 한국어 • Polski • Português • Română • Русский • Slovenščina • ไทย • Türkçe • Українська • Tiếng Việt • 简体中文 • 繁體中文
![]()


![]()
![]()
Apache Doris は、MPP アーキテクチャに基づいた使いやすく、高性能でリアルタイムの分析データベースであり、その極めて高速な処理速度と使いやすさで知られています。大量のデータ下でもサブ秒レベルの応答時間でクエリ結果を返すことができ、高並行ポイントクエリシナリオだけでなく、高スループットの複雑な分析シナリオもサポートできます。
これらの特性により、Apache Dorisはレポート分析、アドホッククエリ、統合データウェアハウス構築、データレイククエリ加速などのシナリオに理想的なツールとなっています。Apache Doris上では、ユーザー行動分析、ABテストプラットフォーム、ログ検索分析、ユーザープロファイル分析、注文分析など、さまざまなアプリケーションを構築できます。
🎉 🔗すべてのリリースをチェックして、過去1年間にリリースされたApache Dorisバージョンの時系列サマリーを確認してください。
👀 🔗公式ウェブサイトを探索して、Apache Dorisのコア機能、ブログ、ユーザー事例を詳しくご覧ください。
以下の図に示すように、さまざまなデータ統合と処理の後、データソースは通常、リアルタイムデータウェアハウスApache Dorisとオフラインデータレイクまたはデータウェアハウス(Apache Hive、Apache Iceberg、またはApache Hudi内)に保存されます。
Apache Dorisは以下のシナリオで広く使用されています:
リアルタイムデータ分析:
リアルタイムレポートと意思決定:Dorisは、内部および外部の企業使用のためのリアルタイム更新レポートとダッシュボードを提供し、自動化プロセスでのリアルタイム意思決定をサポートします。
アドホック分析:Dorisは多次元データ分析機能を提供し、迅速なビジネスインテリジェンス分析とアドホッククエリを可能にし、ユーザーが複雑なデータから迅速に洞察を発見できるようにします。
ユーザープロファイルと行動分析:Dorisは、参加率、リテンション率、コンバージョン率などのユーザー行動を分析でき、人口統計の洞察や行動分析のための群衆選択などのシナリオもサポートします。
データレイク分析:
データレイククエリ加速:Dorisは、その効率的なクエリエンジンにより、データレイクデータクエリを加速します。
連合分析:Dorisは複数のデータソースにわたる連合クエリをサポートし、アーキテクチャを簡素化し、データサイロを排除します。
リアルタイムデータ処理:Dorisはリアルタイムデータストリームとバッチデータ処理機能を組み合わせて、高並行性と低レイテンシの複雑なビジネス要件のニーズを満たします。
SQLベースの可観測性:
Apache DorisはMySQLプロトコルを使用し、MySQL構文と高度に互換性があり、標準SQLをサポートしています。ユーザーはさまざまなクライアントツールを通じてApache Dorisにアクセスでき、BIツールとシームレスに統合できます。
Apache Dorisのストレージ・コンピュート統合アーキテクチャは、合理化されており、保守が容易です。以下の図に示すように、2種類のプロセスのみで構成されています:
Frontend (FE): 主にユーザーリクエストの処理、クエリの解析と計画、メタデータ管理、ノード管理タスクを担当します。
Backend (BE): 主にデータストレージとクエリ実行を担当します。データはシャードに分割され、BEノード間で複数のレプリカとして保存されます。
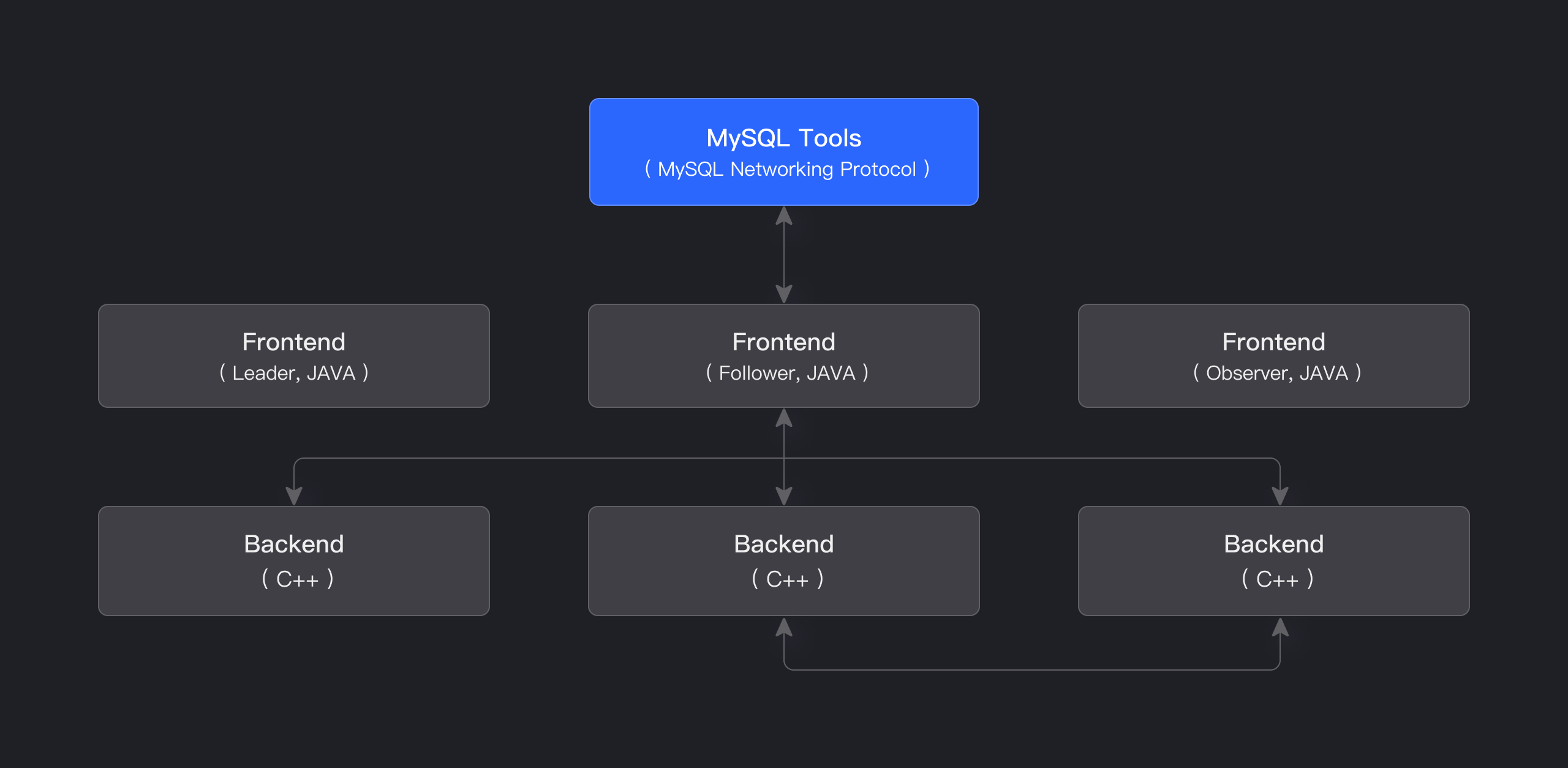
本番環境では、災害復旧のために複数のFEノードを展開できます。各FEノードはメタデータの完全なコピーを維持します。FEノードは3つの役割に分かれています:
| 役割 | 機能 |
|---|---|
| Master | FE Masterノードはメタデータの読み書き操作を担当します。Masterノードでメタデータの変更が発生すると、BDB JEプロトコルを介してFollowerまたはObserverノードに同期されます。 |
| Follower | Followerノードはメタデータの読み取りを担当します。Masterノードが失敗した場合、Followerノードを新しいMasterとして選択できます。 |
| Observer | Observerノードはメタデータの読み取りを担当し、主にクエリの並行性を向上させるために使用されます。クラスターリーダーシップ選挙には参加しません。 |
FEとBEプロセスはどちらも水平スケーリング可能で、単一クラスターが数百台のマシンと数十ペタバイトのストレージ容量をサポートできます。FEとBEプロセスは一貫性プロトコルを使用して、サービスの高可用性とデータの高信頼性を確保します。ストレージ・コンピュート統合アーキテクチャは高度に統合されており、分散システムの運用複雑性を大幅に削減します。
高可用性:Apache Dorisでは、メタデータとデータの両方が複数のレプリカとして保存され、quorumプロトコルを介してデータログが同期されます。大多数のレプリカが書き込みを完了すると、データ書き込みは成功と見なされ、少数のノードが失敗してもクラスターが利用可能なままであることを確保します。Apache Dorisは同地域内および地域間の災害復旧をサポートし、デュアルクラスターのマスタースレーブモードを可能にします。一部のノードで障害が発生した場合、クラスターは障害ノードを自動的に分離し、クラスター全体の可用性が影響を受けないようにします。
高互換性:Apache DorisはMySQLプロトコルと高度に互換性があり、標準SQL構文をサポートし、ほとんどのMySQL関数とHive関数をカバーしています。この高い互換性により、ユーザーは既存のアプリケーションとツールをシームレスに移行および統合できます。Apache DorisはMySQLエコシステムをサポートし、ユーザーがMySQLクライアントツールを使用してDorisに接続し、より便利な運用と保守を実現できます。また、BIレポートツールとデータ転送ツールのMySQLプロトコル互換性をサポートし、データ分析とデータ転送プロセスの効率と安定性を確保します。
リアルタイムデータウェアハウス:Apache Dorisに基づいて、リアルタイムデータウェアハウスサービスを構築できます。Apache Dorisは秒レベルのデータ取り込み機能を提供し、数秒以内に上流のオンライントランザクションデータベースからの増分変更をDorisにキャプチャします。ベクトル化エンジン、MPPアーキテクチャ、およびPipeline実行エンジンを活用して、Dorisはサブ秒レベルのデータクエリ機能を提供し、高性能で低レイテンシのリアルタイムデータウェアハウスプラットフォームを構築します。
統合データレイク:Apache Dorisは、データレイクやリレーショナルデータベースなどの外部データソースに基づいて統合データレイクアーキテクチャを構築できます。Doris統合データレイクソリューションは、データレイクとデータウェアハウス間のシームレスな統合と自由なデータフローを実現し、ユーザーがデータウェアハウス機能を直接活用してデータレイク内のデータ分析問題を解決できるようにし、同時にデータレイクデータ管理機能を十分に活用してデータ価値を強化します。
柔軟なモデリング:Apache Dorisは、ワイドテーブルモデル、事前集計モデル、スター/スノーフレークスキーマなど、さまざまなモデリングアプローチを提供します。データインポート中、データはワイドテーブルにフラット化され、FlinkやSparkなどのコンピュートエンジンを介してDorisに書き込まれるか、データを直接Dorisにインポートし、ビュー、マテリアライズドビュー、またはリアルタイムマルチテーブル結合を介してデータモデリング操作を実行できます。
Dorisは効率的なSQLインターフェースを提供し、MySQLプロトコルと完全に互換性があります。そのクエリエンジンはMPP(大規模並列処理)アーキテクチャに基づいており、複雑な分析クエリを効率的に実行し、低レイテンシのリアルタイムクエリを実現できます。データエンコーディングと圧縮のためのカラムナストレージ技術により、クエリパフォーマンスとストレージ圧縮比を大幅に最適化します。
Apache DorisはMySQLプロトコルを採用し、標準SQLをサポートし、MySQL構文と高度に互換性があります。ユーザーはさまざまなクライアントツールを通じてApache Dorisにアクセスでき、Smartbi、DataEase、FineBI、Tableau、Power BI、Apache Supersetなどを含むがこれらに限定されないBIツールとシームレスに統合できます。Apache Dorisは、MySQLプロトコルをサポートする任意のBIツールのデータソースとして機能できます。
Apache Dorisにはカラムナストレージエンジンがあり、列ごとにデータをエンコード、圧縮、読み取ります。これにより、非常に高いデータ圧縮比が実現され、不要なデータスキャンが大幅に削減され、IOとCPUリソースをより効率的に利用できます。
Apache Dorisは、データスキャンを最小限に抑えるためのさまざまなインデックス構造をサポートしています:
ソート複合キーインデックス:ユーザーは最大3列を指定して複合ソートキーを形成できます。これにより、データを効果的に剪定し、高並行レポートシナリオをより良くサポートできます。
Min/Maxインデックス:これは数値型の等価性と範囲クエリで効果的なデータフィルタリングを可能にします。
BloomFilterインデックス:これは等価性フィルタリングと高カーディナリティ列の剪定で非常に効果的です。
転置インデックス:これは任意のフィールドの高速検索を可能にします。
Apache Dorisは、さまざまなデータモデルをサポートし、異なるシナリオに対して最適化されています:
詳細モデル(Duplicate Key Model): ファクトテーブルの詳細ストレージ要件を満たすように設計された詳細データモデル。
主キーモデル(Unique Key Model): 一意のキーを確保します。同じキーを持つデータは上書きされ、行レベルのデータ更新が可能になります。
集計モデル(Aggregate Key Model): 同じキーを持つ値列をマージし、事前集計によりパフォーマンスを大幅に向上させます。
Apache Dorisは、強一貫性の単一テーブルマテリアライズドビューと非同期リフレッシュのマルチテーブルマテリアライズドビューもサポートしています。単一テーブルマテリアライズドビューは、システムによって自動的にリフレッシュおよび維持され、ユーザーの手動介入は必要ありません。マルチテーブルマテリアライズドビューは、クラスター内スケジューリングまたは外部スケジューリングツールを使用して定期的にリフレッシュでき、データモデリングの複雑さを軽減します。
Apache Dorisには、ノード間およびノード内の並列実行のためのMPPベースのクエリエンジンがあります。大規模テーブルの分散シャッフル結合をサポートし、複雑なクエリをより良く処理します。
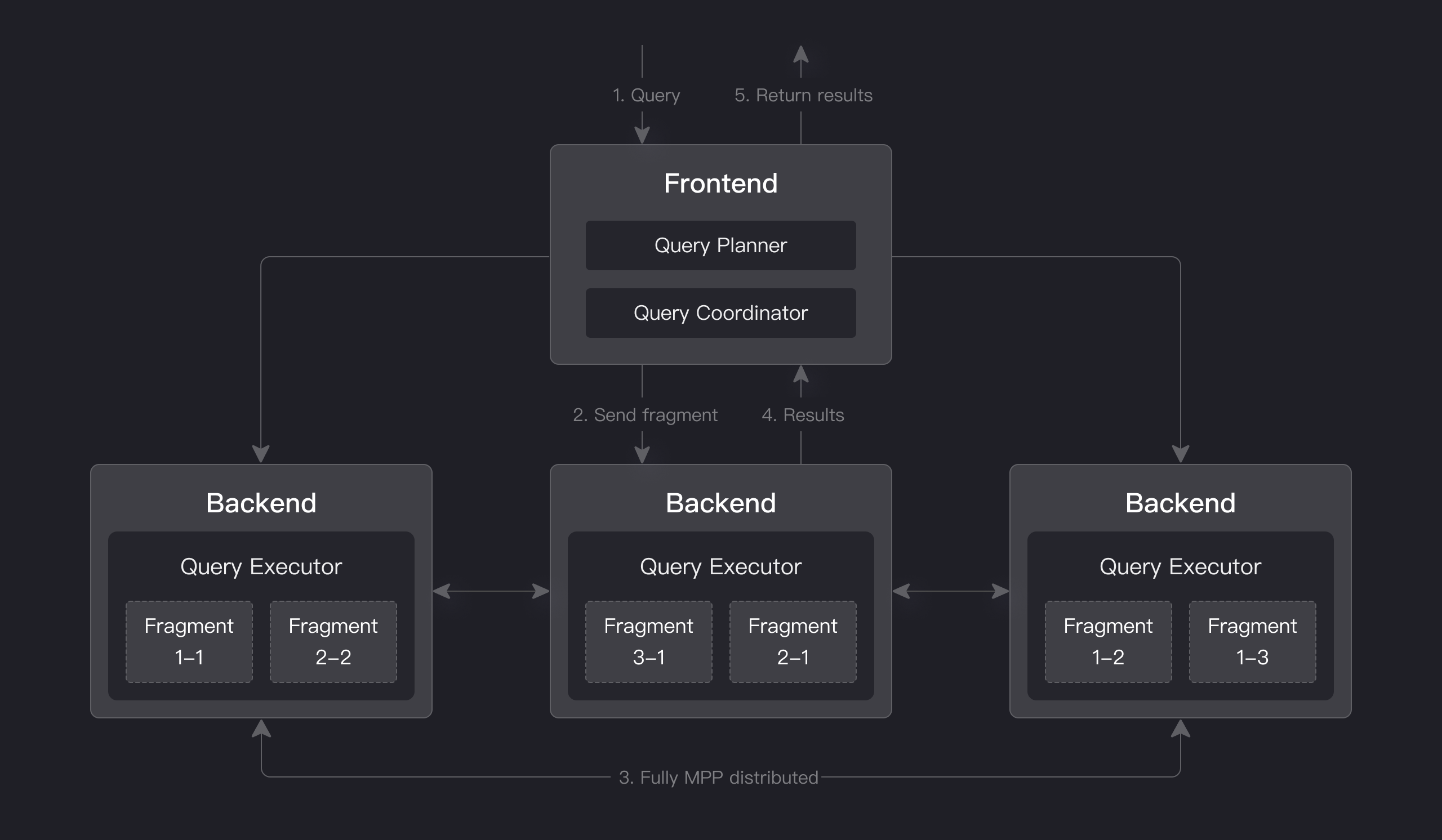
Apache Dorisのクエリエンジンは完全にベクトル化されており、すべてのメモリ構造がカラムナ形式で配置されています。これにより、仮想関数呼び出しが大幅に削減され、キャッシュヒット率が向上し、SIMD命令を効率的に利用できます。Apache Dorisは、ワイドテーブル集計シナリオで、非ベクトル化エンジンよりも5〜10倍高いパフォーマンスを提供します。

Apache Dorisは適応的クエリ実行技術を使用して、実行時統計に基づいて実行計画を動的に調整します。たとえば、実行時フィルターを生成し、プローブ側にプッシュできます。具体的には、フィルターをプローブ側の最下位スキャンノードにプッシュし、処理するデータ量を大幅に削減し、結合パフォーマンスを向上させます。Apache Dorisの実行時フィルターは、In/Min/Max/Bloom Filterをサポートしています。
Apache DorisはPipeline実行エンジンを使用して、クエリを複数のサブタスクに分解して並列実行し、マルチコアCPU機能を十分に活用します。同時に、クエリスレッド数を制限することでスレッド爆発の問題に対処します。Pipeline実行エンジンは、データのコピーと共有を削減し、ソートと集計操作を最適化することで、クエリ効率とスループットを大幅に向上させます。
オプティマイザーの観点から、Apache Dorisは、CBO(コストベースオプティマイザー)、RBO(ルールベースオプティマイザー)、およびHBO(履歴ベースオプティマイザー)の組み合わせ最適化戦略を採用しています。RBOは定数折りたたみ、サブクエリの書き換え、述語プッシュダウンなどをサポートします。CBOは結合の並べ替えやその他の最適化をサポートします。HBOは、履歴クエリ情報に基づいて最適な実行計画を推奨します。これらの複数の最適化措置により、Dorisはさまざまなタイプのクエリで高性能なクエリ計画を列挙できることが保証されます。
🎯 使いやすい:2つのプロセス、他の依存関係なし。オンラインクラスタースケーリング、自動レプリカ回復。MySQLプロトコルと互換性があり、標準SQLを使用します。
🚀 高性能:カラムナストレージエンジン、最新のMPPアーキテクチャ、ベクトル化クエリエンジン、事前集計マテリアライズドビュー、データインデックスにより、低レイテンシと高スループットクエリの極めて高速なパフォーマンスを実現します。
🖥️ 単一統合:単一システムで、リアルタイムデータサービス、インタラクティブデータ分析、オフラインデータ処理シナリオをサポートできます。
⚛️ 連合クエリ:Hive、Iceberg、Hudiなどのデータレイクや、MySQL、Elasticsearchなどのデータベースの連合クエリをサポートします。
⏩ さまざまなデータインポート方法:HDFS/S3からのバッチインポートとMySQL Binlog/Kafkaからのストリームインポートをサポートします。HTTPインターフェースを介したマイクロバッチ書き込みと、JDBCのInsertを使用したリアルタイム書き込みをサポートします。
🚙 豊富なエコシステム:SparkはSpark-Doris-Connectorを使用してDorisの読み書きを行います。Flink-Doris-Connectorにより、Flink CDCがDorisへの正確に1回のデータ書き込みを実現できます。DBT Doris Adapterが提供され、DBTを使用してDoris内のデータを変換できます。
Apache Dorisは、Apacheインキュベーターから正常に卒業し、2022年6月にトップレベルプロジェクトになりました。
Apache Dorisへの貢献に対して、🔗コミュニティ貢献者に深く感謝いたします。
Apache Dorisは現在、中国および世界中で広範なユーザーベースを持ち、今日までに、Apache Dorisは世界中の数千の企業の本番環境で使用されています。時価総額または評価額で中国のトップ50インターネット企業の80%以上が、Apache Dorisを長期間使用しており、百度、美団、小米、京東、字節跳動、騰訊、網易、快手、新浪、360、米哈遊、貝殼控股などが含まれます。金融、エネルギー、製造業、通信などの一部の伝統的な業界でも広く使用されています。
Apache Dorisのユーザー:🔗ユーザー
Apache Dorisウェブサイトに会社のロゴを追加:🔗会社を追加
すべてのドキュメント 🔗ドキュメント
すべてのリリースとバイナリバージョン 🔗ダウンロード
コンパイル方法を確認 🔗コンパイル)
インストールと展開方法を確認 🔗インストールと展開
Dorisは、Connectorを介してSpark/FlinkがDorisに保存されているデータを読み取ることをサポートし、Connectorを介してDorisにデータを書き込むこともサポートします。
メーリングリストは、Apacheコミュニティで最も認められたコミュニケーション形式です。🔗メーリングリストを購読する方法を確認してください
質問がある場合は、🔗GitHub Issueを提出するか、🔗GitHub Discussionに投稿し、🔗Pull Requestを提出して修正してください
ご提案、コメント(批判を含む)、意見、貢献を歓迎します。🔗貢献方法と🔗コード提出ガイドを参照してください
🔗Doris改善提案 (DSIP)は、すべての主要な機能更新または改善の設計ドキュメントのコレクションと考えることができます。
🔗 バックエンドC++コーディング仕様は厳密に遵守する必要があり、これによりコード品質の向上に役立ちます。
以下のメーリングリストを通じてお問い合わせください。
| 名前 | 範囲 | |||
|---|---|---|---|---|
| dev@doris.apache.org | 開発関連の議論 | 購読 | 購読解除 | アーカイブ |
注意 一部のサードパーティ依存関係のライセンスは、Apache 2.0ライセンスと互換性がありません。したがって、Apache 2.0ライセンスに準拠するために、一部のDoris機能を無効にする必要があります。詳細については、
thirdparty/LICENSE.txtを参照してください